




 分页查询在众多网站中广泛使用,旨在提高性能和用户体验。本文探讨了为何进行分页查询,实现分页的两种方式(真分页和假分页),以及分页对象的设计,强调异步查询在提升用户体验中的作用。此外,还讨论了数据库层面的分页实现,如MySQL的limit和PostgreSQL的limit、offset。
分页查询在众多网站中广泛使用,旨在提高性能和用户体验。本文探讨了为何进行分页查询,实现分页的两种方式(真分页和假分页),以及分页对象的设计,强调异步查询在提升用户体验中的作用。此外,还讨论了数据库层面的分页实现,如MySQL的limit和PostgreSQL的limit、offset。
目录
●为什么要做分页查询?
大家登陆网站,使用到查询功能的时候有没有发现,其实页面上几乎都不会给你展示所有内容,而是以分页的方式进行展示,我们来看看几个常见的场景:
优快云博客——

站长素材——

Printrest——

包括大家常用的淘宝、知乎、微博、视频网站等,无一例外都是采用了分页查询的机制,具体表现在:
1、查询的数据量相对较多,每次给用户展示一部分;
2、用户通过上一页、下一页、页码跳转、滚动条(瀑布流网站)等方式获取其余的数据。
这么做的原因有以下几点:
1、当数据量很大的时候,后台全部查询出来是一个很耗时间的操作;
2、退一步说,就算了用到分布式、缓存等技术,降低后台操作时间,但大量数据在网络上传输给用户时也是很耗时的,例如目前常见的网络环境也不过就是10M或者100M;
3、再退一步说,就算查询和传输都是迅速完成的,把这么多数据,全部展现在用户面前,让用户自己去大海捞针般的查看,体验也是很糟糕的。
因此,无论是从性能表现上还是用户体验上,分页查询是必须要做的。
●如何实现分页查询
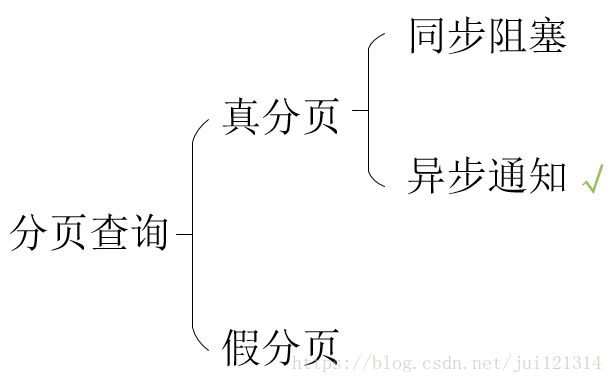
按笔者的理解,分页查询可以分为两类,一类称之为“真分页”;一类称之为“假分页”。
“真分页”是在后台按需查询所要显示的数据,回传给前台展示;“假分页”是后台查询出所有数据,回传给前台,由前台来进行分页展示。毫无疑问,“假分页”是一种自欺欺人的做法。
“真分页”根据实现的技术,笔者也将其分为两类,一类利用同步阻塞,一类利用异步通知。前者等待数据到达页面之后用户才可以进行其他操作,后者这是利用Ajax,不对用户的操作产生阻塞,表现在用户可以点击其他按钮/菜单,进行别的操作。正常来说,都是选择异步通知的方式进行真分页。
流程上来说,用户设置好查询条件(例如输入查询起止时间、查询的类别等),点击查询按钮(当然,不同的网站表现也不同,例如有的是加载网页后直接查询出一些分页内容,例如点击淘宝的已购买的宝贝,就会自动按时间排序查出最新的X条数据,之后用户可以设置查询条件再点查询),页面向服务器后台发起查询请求,服务器根据查询条件,拼接好查询SQL语句并执行,查出满足条件的前XX条数据,并且记录下总的记录条数,通过分页对象返回给前台。前台翻页的时候会把当前页数、每页展示数据量等信息告诉服务器后台,继而查询之后的数据。
整个流程的时序图如下:
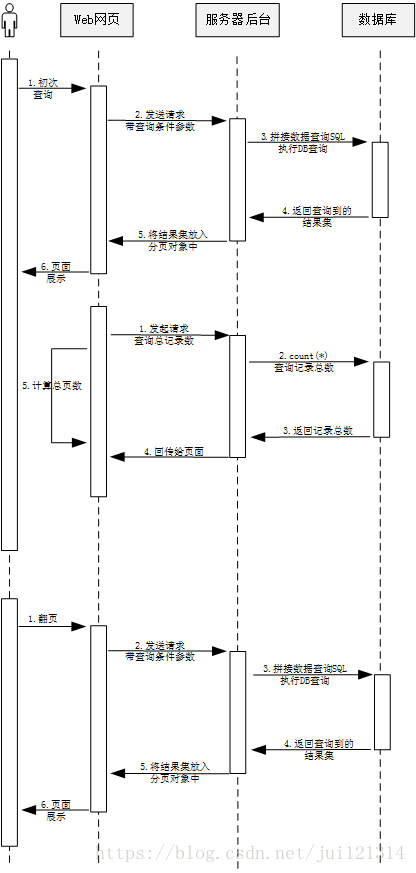
值得注意的是,用户进行首次查询的时候,网页其实是发起了两次请求,将查询数据(设置了显示数量、类别等条件)和查询总记录的条数分开请求,如果不分开,count(*)的操作可能会消耗大量时间,造成用户迟迟无法看到返回的数据。因此,先把数据展示给用户,改善用户的体验。而在之后的翻页操作中,就不用再去查询记录的总条数了,因为第一次已经查询过,并且给到了前台计算总页数并保存,之后的翻页操作,前台除了将查询的限制条件发给后台外,再讲查询的起始值也发过去就可以了。例如每页显示20条数据,用户翻页到第五页,那么起始值就应该是20*(5-1)=80。第一次点击查询的时候页面传过去的起始值是0。
●分页对象的设计
通常分页对象需要设计包括以下成员变量:页面大小(即一页展示多少条数据)、数据起始id、总的记录条数、最后一条数据的id、数据(一般是一个List对象)、
通常分页对象还需要设计包括以下方法:相应的get/set方法、取总页数的方法(当然也可以把这个逻辑下放到前台去执行)、取当前页码的方法(同前)、是否有上下页以及一些对应的数据所在位置的计算函数。
来看一下具体的代码实现:
import java.util.ArrayList;
public class Page {
// 常量,定义默认的页面大小,即一页默认展示多少数据
private static int DEFAULT_PAGE_SIZE = 10;
// 每页的记录数,先设为默认值
private int pageSize = DEFAULT_PAGE_SIZE;
// 当前页第一条数据在List中的位置,从0开始
private long start;
// 当前页中存放的记录,类型一般为List<T>
private Object data;
// 总记录数
private long totalCount;
// 最大的一条记录的id
private String recordMaxIds;
/**
* 构造方法,构造空页.
*/
public Page() {
this(0, 0, DEFAULT_PAGE_SIZE, new ArrayList());
}
/**
* 默认构造方法.
* @param start 本页数据在数据库中的起始位置
* @param totalSize 数据库中总记录条数
* @param pageSize 本页容量
* @param data 本页里面的数据
*/
public Page(long start, long totalSize, int pageSize, Object data) {
if(pageSize == 0 ){
pageSize = DEFAULT_PAGE_SIZE;
}else{
this.pageSize = pageSize;
}
this.start = start;
this.totalCount = totalSize;
this.data = data;
}
/**
* 取总记录数.
*/
public long getTotalCount() {
return this.totalCount;
}
/**
* 取总页数.
*/
public long getTotalPageCount() {
if(totalCount == 0){
return 1;
}else{
if (totalCount % pageSize == 0)
return totalCount / pageSize;
else
return totalCount / pageSize + 1;
}
}
/**
* 取每页数据容量.
*/
public int getPageSize() {
return pageSize;
}
/**
* 取当前页中的记录.
*/
public Object getResult() {
return data;
}
/**
* 取该页当前页码,页码从1开始.
*/
public long getCurrentPageNo() {
if(pageSize != 0){
return start / pageSize + 1;
}else{
return 1;
}
}
/**
* 该页是否有下一页.
*/
public boolean hasNextPage() {
return this.getCurrentPageNo() < this.getTotalPageCount() - 1;
}
/**
* 该页是否有上一页.
*/
public boolean hasPreviousPage() {
return this.getCurrentPageNo() > 1;
}
/**
* 获取任一页第一条数据在数据集的位置.
* @param pageNo 从1开始的页号
* @param pageSize 每页记录条数
* @return 该页第一条数据
*/
public static int getStartOfPage(int pageNo, int pageSize) {
return (pageNo - 1) * pageSize;
}
/**
* 获取页号,从1开始.
* @param startIndex 开始索引
* @param pageSize 每页记录条数
* @return 从1开始的页号
*/
public static int getPageNo(int startIndex, int pageSize) {
return startIndex % pageSize == 0 ? startIndex / pageSize : startIndex / pageSize + 1;
}
public String getRecordMaxIds() {
return recordMaxIds;
}
public void setRecordMaxIds(String recordMaxIds) {
this.recordMaxIds = recordMaxIds;
}
public void setData(Object data) {
this.data = data;
}
}●其他补充的信息
最后,我们要知道,分页查询最终还是要落实到数据库去执行,通过分页查询的SQL是进行查询时避免全表扫描。因此,分页这个业务,在执行数据库操作时,需要构造不同的查询语句,通常来说MySql利用的是limit子句,PostgreSQL利用的是limit和offset子句来实现的,可以人为去Dao层写对应的函数。如果使用了Hibernate等框架,还可以直接使用它所提供的函数去进行数据库分页,例如Hibernate中的setFirstResult()和setMaxResults()函数来控制查询与返回结果集的条数。而这个控制数量、偏移量的值则是第一次查询出总记录,加上页面设置的每页数据量多少来共同计算的。
分页对象回传给前端网页的时候,一般可以采用JQuery的Ajax技术进行接收处理,笔者目前从事后端开发工作,这一块暂时就先不和大家分享了。今天,你学会了吗?

















 313
313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









