




 本文深入探讨Python的内存驻留机制,包括可变与不可变类型的存储、代码块缓存、小数据池,揭示Python如何提高运行效率。讲解了整数和字符串在不同情况下的驻留规则,并建议使用join而非'+'连接字符串以提升性能。
本文深入探讨Python的内存驻留机制,包括可变与不可变类型的存储、代码块缓存、小数据池,揭示Python如何提高运行效率。讲解了整数和字符串在不同情况下的驻留规则,并建议使用join而非'+'连接字符串以提升性能。
Python中的可变类型和不可变类型是如何存储的?小数据池对于整形存储有什么影响?Python解释器为了提高字符串使用的效率和使用性能又做了哪些优化?本文将为你慢慢道来,让你深入了解Python中的内存驻留。接下来话不多说,直接进入正题。
1可变类型和不可变类型
咱们先来复习一下Python中的不可变类型和可变类型。可变类型:列表、字典、可变集合,可以通过操作原处修改,而不用创建新的对象;不可变类型:数字、字符串、元组、不可变集合,不支持原地修改。看下面的例子:

从上图能够看到,我们可以对可变类型进行原地修改,id不变;而去操作不可变对象时,因为它不可原地修改,内部没有实现__iadd__()方法,所以a += 1等同于a = a + 1,创建了新的对象,id改变。关于id这里需要注意,我们用id函数获取的是对象的唯一标识符,只不过在CPython解释器下,刚好返回的是对象的内存地址。
我们可以看到,对于不可变类型,每次修改一次就要创建一个新的对象。如果过多的进行修改操作无疑会消耗很大的内存。出于提高效率,减少内存消耗的考量,Python实现了自己的内存驻留机制。
2代码块的缓存机制
我们先来看Python官方对于代码块的定义:
https://docs.python.org/3/reference/executionmodel.html。

翻译过来主要意思是:一个Python程序是由代码块组成的。一个代码块是一个Python程序员的文本,它是作为一个单元执行的。一个模块,一个函数,一个类,一个脚本文件等都是代码块。而交互方式下的每一个命令都是一个代码块。在命令行模式下敲命令python,就看到类似如下的一堆文本输出,然后就进入到Python交互模式,它的提示符是>>>。
代码块缓存机制的适用对象为:int(float),str,bool。在同一代码块内,Python执行初始化对象的命令时,会先检查其值是否存在,如果存在则重用,不存在再建立对象。更详细一点,Python会维护一个名为interned的字典,在这个字典中,记录着被驻留机制处理过的对象。举个例子:如果对于a应用了驻留机制,那么之后要创建b的时候,Python会首先在nterned字典中查找,如果发现对应的对象已经存在,那么就将该对象的引用返回,而不是重新创建一个对象。其实这么说不太具体,对于字符串,Python无论如何都会先创建一个临时的字符串对象,如果发现 interned 里面有的话,把它的引用计数减一,临时对象因为引用计数值为零而被销毁,之后再把引用指向 interned 里的字符串对象。这一点在源码当中可以看出来:

1、int
任何整数在同一代码块下都会复用。
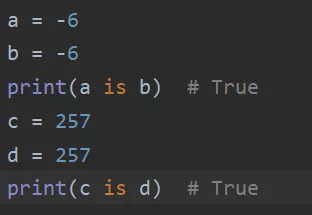
2、bool
True和False在字典中会以1,0方式存在,并且复用。
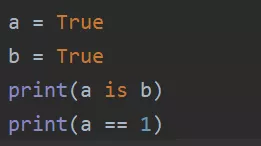
3、str
非乘法得到的所有字符串满足代码块的缓存机制:
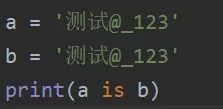
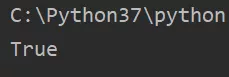
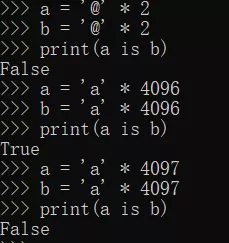
对于乘法得到的字符串:当乘数为1时,跟上一种情况相同,这里不再赘述;当乘数>1时,总长度<=4096则满足代码块的缓存机制。
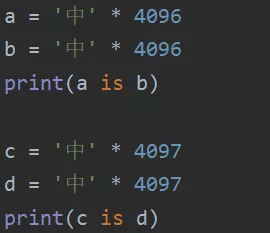
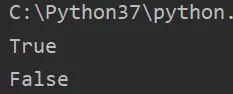
3小数据池
即不同代码块的缓存机制,它发生在代码不在同一代码块内时。官方对于整数的小数据池是这么说的:https://docs.python.org/3.8/c-api/long.html
维基百科上对于字符串的解释:
大概意思就是:Python缓存了-5至256之间的整数,当你打算创建在这个范围中的整数时,并不会重新创建对象,而是使用已经创建好的缓存对象。Python会将一定规则的字符串存在字符串驻留池中,创建一份,当你将这些字符串赋值给变量时,并不会重新创建对象,而是使用在字符串驻留池中创建好的对象。
1、int
对于[-5,256]之间的整数,Python都会驻留。
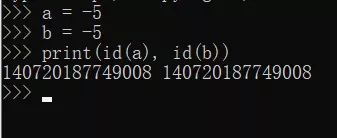
2、str
当字符串长度<=1时,对于非中文的字符串都采用了驻留机制。
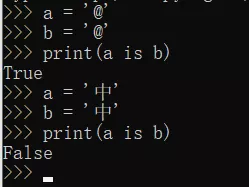
字符串的长度>1,且只含有大小写字母,数字,下划线时,才会默认驻留。
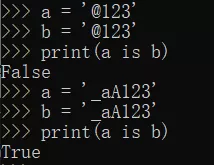
对于用乘法得到的字符串,不包含中文、特殊符号,且总长度<=4096才会被驻留。
4小结和补充
除了上述由Python内部实现的默认的驻留机制,Python还给用户提供了强制驻留的方法。
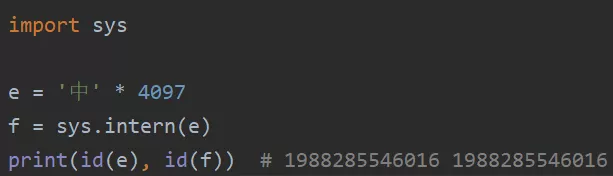
看到这里,相信小伙伴们对Python的驻留机制有了详细的了解。总而言之,都是为了提高效率。这里做一个小结:如果在同一代码块下,则采用同一代码块下的缓存机制。如果是不同代码块,则采用小数据池的驻留机制。可以动手尝试验证一下:
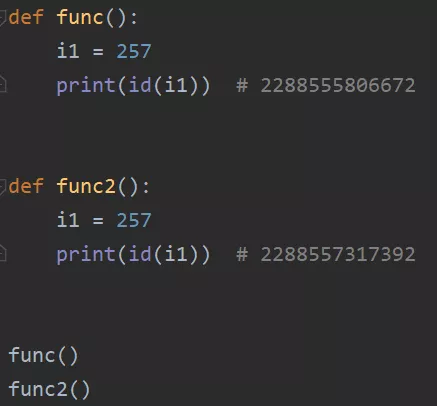
说到效率,这里再说一下字符串连接的问题。前面说了,字符串作为一种不可变类型,如果在程序中进行过多的操作,因为每一次操作都要生成新的字符串对象,势必会消耗很大的内存,极有可能造成内存泄漏。从性能上来说,推荐使用join方法来连接字符串而不是‘+’号。话不多说,先来对比一下:
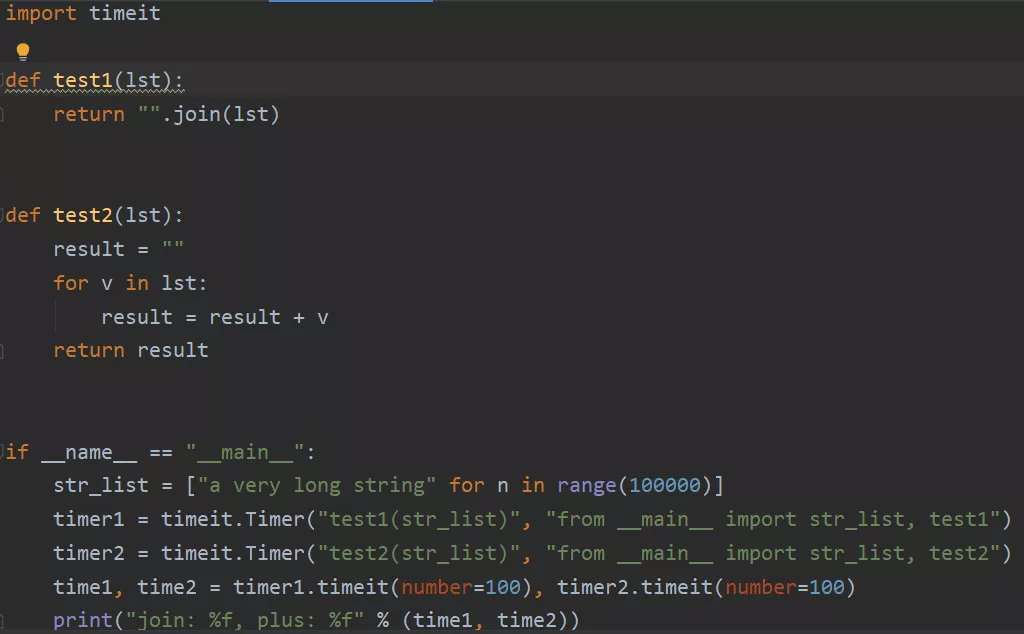
运行结果如下:
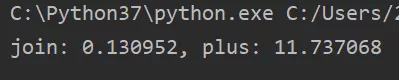
能够看到,用join的速度要远远比用‘+’快。知其然还得知其所以然,接下来看看源码:通过“+”操作符对字符串进行连接时,会调用string_concat函数:

当进行字符串连接时,实际上是必须要创建一个新的PyStringObject对象,每执行一次+都会申请一块新的内存。这样,如果要连接N个PyStringObject对象,那么就必须进行N-1次的内存申请及内存搬运的工作。毫无疑问,这将严重影响Python的执行效率。而如果利用PyStringObject对象的join操作,则会进行如下的动作:

而join在连接字符串的时候,会先计算需要多大的内存存放结果,然后一次性申请所需内存并将字符串复制过去,这是为什么join的性能优于+的原因。所以在连接字符串数组的时候,我们应考虑优先使用join。
本文所有的测试基于Python3.7.1。更多干货内容,欢迎关注公众号:知了python

















 1467
1467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









