




目前,市面上许多开源模型都是基于 LLaMA(Meta 开源的系列大模型)进行改造,但并非所有开源模型都依赖 LLaMA。
LLaMA 系列模型的影响力
-
LLaMA(Meta 开源)是当前最受欢迎的开源大模型基座之一,其架构(如 Transformer 变体)被广泛采用。
-
LLaMA 3/4 的变体:许多开源模型基于 LLaMA 微调(如使用 LoRA、Adapter 等技术),或在其基础上扩展多模态能力。
-
Hugging Face 生态:LLaMA 系列在 Hugging Face 上有大量衍生模型,例如:
-
Chinese-LLaMA(中文优化版)
-
LLaMA-2/3 的医学、法律等垂直领域微调版
-
其他独立开源模型
尽管 LLaMA 影响深远,仍有部分开源模型并非基于 LLaMA,例如:
-
DeepSeek 系列(如 DeepSeek-R1、DeepSeek V3):采用独立架构,并非 LLaMA 变体。
-
OLMo(Allen AI):完全独立训练,附带完整训练数据与代码。
-
Qwen(通义千问):阿里自研,非 LLaMA 衍生。
-
Mistral/Mixtral:法国 Mistral AI 开发的高效 MoE 模型,架构与 LLaMA 不同
为什么 LLaMA 被广泛采用
-
开源友好:Meta 允许商用(部分版本需申请),促进社区二次开发。
-
架构成熟:LLaMA 的 Transformer 变体优化较好,适合微调。
-
生态支持:Hugging Face、LlamaFactory 等工具简化了 LLaMA 的训练与部署
基于 LLaMA 怎么做微调
基于 LLaMA 微调(Fine-tuning)
适用场景
-
希望快速适配特定任务(如对话、代码生成、垂直领域问答)。
-
计算资源有限(如单张消费级 GPU)。
-
不需要大幅修改模型架构。
常见方法
-
全参数微调(Full Fine-tuning):调整所有模型参数(需较大显存)。
-
参数高效微调(PEFT):如 LoRA(Low-Rank Adaptation)、QLoRA(量化 LoRA),仅训练少量新增参数,保持原模型权重不变
优点
✅ 计算成本低(QLoRA 可在 24GB GPU 上微调 LLaMA-3 8B)。
✅ 保留 LLaMA 的通用能力,仅优化特定任务表现。
✅ 工具成熟(如 LLaMA Factory、Hugging Face Transformers)。
缺点
❌ 依赖 LLaMA 的原始架构,无法修改模型结构(如注意力机制、层数)。
❌ 需遵守 Meta 的许可证(商用可能受限)。
基于 LLaMA 源码二次开发 + 重新训练
适用场景
-
需要改进模型架构(如优化注意力机制、扩展上下文窗口)。
-
训练数据与 LLaMA 差异极大(如专业领域语料)。
-
希望完全自主可控(避免许可证限制)。
常见方法
-
修改架构:调整 Transformer 层、归一化方式(如 RMSNorm → LayerNorm)。
-
增量预训练(Continual Pre-training):在 LLaMA 基础上用新数据继续训练。
-
完全重新训练:仅借鉴 LLaMA 设计,从零训练(需海量计算资源)。
优点
✅ 可突破 LLaMA 的原始限制(如支持更长上下文)。
✅ 无需受限于 Meta 的许可证(若完全重写代码)。
缺点
❌ 计算成本极高(如 LLaMA-3 8B 需 130 万 GPU 小时)。
❌ 技术门槛高(需深度掌握分布式训练、数据清洗等)。
趋势与建议
-
微调仍是主流:90% 的开源衍生模型基于微调(如 ChatGLM、Alpaca)。
-
二次开发渐增:部分团队开始修改架构(如 DeepSeek-MoE 采用非 LLaMA 设计)。
-
建议优先尝试微调:除非有明确需求(如支持 100K 上下文),否则微调性价比更高。
微调利器:LLaMA-Factory vs LoRA
| 对比维度 | LLaMA-Factory | LoRA(Low-Rank Adaptation) |
| 定义 | 一个开源的大模型微调框架,支持多种训练方法(如全量微调、LoRA、Freeze、RLHF 等) | 一种参数高效微调(PEFT)技术,通过低秩矩阵分解减少训练参数量 |
| 功能范围 | 提供从数据准备、训练、评估到部署的全流程支持 | 仅是一种微调策略,需结合其他工具(如 Transformers、PEFT)使用 |
| 适用场景 | 适用于全量微调、LoRA、Freeze、RLHF 等多种训练方式 | 适用于资源受限场景,仅调整部分参数 |
微调方式对比
(1) LLaMA-Factory 支持的微调方法
-
全量微调(Full Fine-tuning):更新所有模型参数,计算成本高。
-
LoRA 微调:仅调整低秩适配矩阵,节省显存。
-
Freeze(冻结微调):仅训练部分层(如最后几层)。
-
RLHF / DPO:支持基于人类反馈的强化学习微调。
(2) 纯 LoRA 微调的特点
-
仅调整部分参数:通过引入
A和B低秩矩阵,减少可训练参数(如仅调整q_proj, v_proj)。 -
无额外框架依赖:可单独使用 Hugging Face
peft库实现,但需自行处理数据加载、训练循环等。 -
适合轻量化调整:适用于小规模数据或垂直领域适配
性能与资源消耗
| 指标 | LLaMA-Factory(全量微调) | LLaMA-Factory(LoRA) | 纯 LoRA(PEFT) |
| 显存占用 | 高(如 8B 模型需 80GB+) | 低(如 8B 模型仅需 16GB) | 类似 |
| 训练速度 | 慢 | 快 | 快 |
| 模型效果 | 最优(全参数更新) | 接近全量微调 | 依赖秩(rank)设置 |
LLaMA-Factory(LoRA 微调)vs 基于代码的 LoRA 微调(如 PEFT)
| 对比维度 | LLaMA-Factory(LoRA 微调) | 基于代码的 LoRA 微调(如 PEFT) |
| 操作形式 | 提供 Web UI / CLI / YAML 配置 | 纯代码编写(Python + PEFT 库) |
| 灵活度 | 中高(预设模板+有限自定义) | 极高(可完全自定义训练逻辑) |
| 功能范围 | 全流程支持(数据→训练→评估→部署) | 需自行实现数据加载、训练循环等 |
| 适用人群 | 快速实验/初学者/标准化任务 | 深度定制/研究需求/复杂场景 |
| 代码侵入性 | 低(封装细节) | 高(需理解底层实现) |
灵活度差异
(1) LLaMA-Factory 的局限性
-
参数配置受限:虽然支持通过 YAML 或 UI 调整 LoRA 的
rank、target_modules等参数,但无法直接修改底层逻辑(如自定义损失函数、优化器策略)。
# LLaMA-Factory 的 YAML 配置示例(固定选项)
finetuning_type: lora
lora_rank: 8
lora_target: q_proj,v_proj # 只能选择预设模块-
数据预处理固化:默认使用框架内置的数据加载器,若需特殊处理(如动态掩码、多模态数据),需修改框架源码。
(2) 代码实现的灵活性
-
完全控制训练流程:可自由定义数据加载、模型修改、训练逻辑(例如混合精度策略、梯度裁剪阈值)。
# 自定义 LoRA 配置(PEFT 库)
from peft import LoraConfig
lora_config = LoraConfig(
r=8,
target_modules=["q_proj", "k_proj", "v_proj"], # 任意指定模块
lora_alpha=32,
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM",
)-
扩展性强:可结合其他库(如
accelerate实现分布式训练,或集成wandb自定义日志)。
扩展:为什么 LoRA 是 PEFT 的代表?
-
参数效率:仅训练低秩矩阵(如0.1%的原始参数量)
-
性能保留:冻结原模型权重,避免灾难性遗忘
-
灵活性:可插拔式应用于Transformer的任意权重层
适用场景建议
-
选择 LLaMA-Factory:
-
需要快速验证模型效果(如测试不同
rank对任务的影响)。 -
缺乏深度学习工程经验(避免手动处理分布式训练/梯度累积)。
-
任务标准化(如对话微调、文本分类)。
-
-
选择代码实现:
-
需要修改模型架构(如插入 Adapter 层)。
-
数据格式特殊(如非结构化日志、多模态输入)。
-
研究性质需求(如实验新型微调算法)。
-
LLaMA-Factory介绍

LLaMA-Factory 支持多种流行的语言模型,如 LLaMA、BLOOM、Mistral、Baichuan 等,涵盖了广泛的应用场景。从学术研究到企业应用,Llama-Factory 都展示了其强大的适应能力和灵活性。此外,Llama-Factory 配备了用户友好的 LlamaBoard Web 界面,降低了使用门槛,使得即便是没有深厚编程背景的用户,也能轻松进行模型微调和推理操作。
分层架构
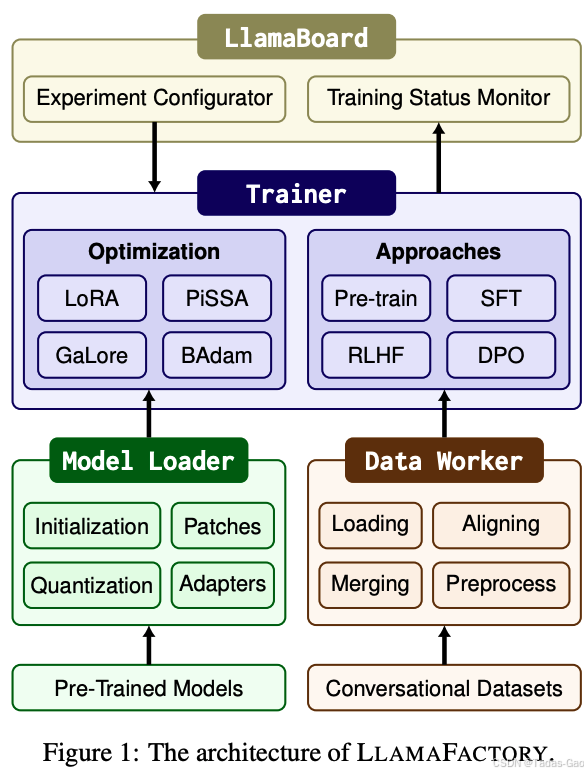
LLaMA-Factory 采用模块化设计,主要分为以下几个核心层次:
用户交互层(UI/CLI)
- 提供 Web UI(LlamaBoard)和 命令行接口(CLI),支持零代码或低代码操作,降低使用门槛。
- 用户可通过可视化界面配置微调参数、选择数据集、启动训练及推理任务。
数据处理层(Data Worker)
- 支持多种数据集格式(如 Alpaca、ShareGPT、自定义 JSONL),并进行预处理(如 tokenization、padding)。
- 内置 Prompt 模板系统,确保输入格式与预训练模型对齐(如 LLaMA2-Chat、ChatML 等)。
模型加载与优化层(Model Loader & Patching)
- 基于 Hugging Face
AutoModelAPI 加载预训练模型,支持 RoPE scaling 处理长上下文。 - 集成 FlashAttention、S2Attention 加速计算,并支持 monkey patching 优化前向传播。
- 动态注入 LoRA/QLoRA 适配器(通过
peft库),实现参数高效微调。
训练与优化层(Trainer)
- 扩展 Hugging Face
Trainer,支持:
- 混合精度训练(bf16/fp16)。
- 分布式训练(FSDP、DeepSpeed Zero)。
- RLHF/DPO/PPO 等强化学习微调。
-
集成 量化技术(4/8-bit QLoRA),降低显存需求。
推理与部署层
- 支持 vLLM 加速推理,提供 OpenAI 风格 API。
- 支持模型权重合并(Adapter → 全参数模型)及量化导出。
特性对比
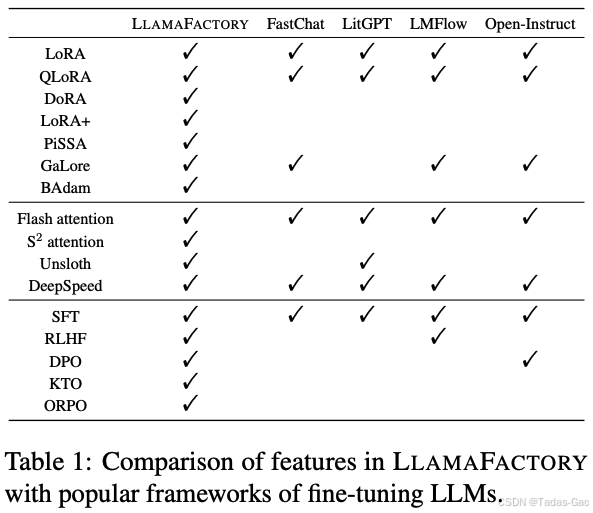
1. LLaMA-Factory 支持最全面,覆盖高效微调(LoRA/QLoRA/DoRA)、注意力优化(FlashAttention/S2Attention)和强化学习(RLHF/DPO/ORPO)。
2. FastChat 侧重推理部署,微调功能较弱,仅支持基础 SFT。
3. LitGPT 专注轻量级微调(LoRA/QLoRA),集成 FlashAttention 但缺乏高级优化。
4. LMFlow 和 Open-Instruct 支持主流微调(SFT/RLHF/DPO)。




















 477
477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











