




内容源自计算机科研圈
在机器人操作任务中,预测性策略近年来在具身人工智能领域引起了广泛关注,因为它能够利用预测状态来提升机器人的操作性能。然而,让世界模型预测机器人与物体交互的精确未来状态仍然是一个公认的挑战,尤其是生成高质量的像素级表示。
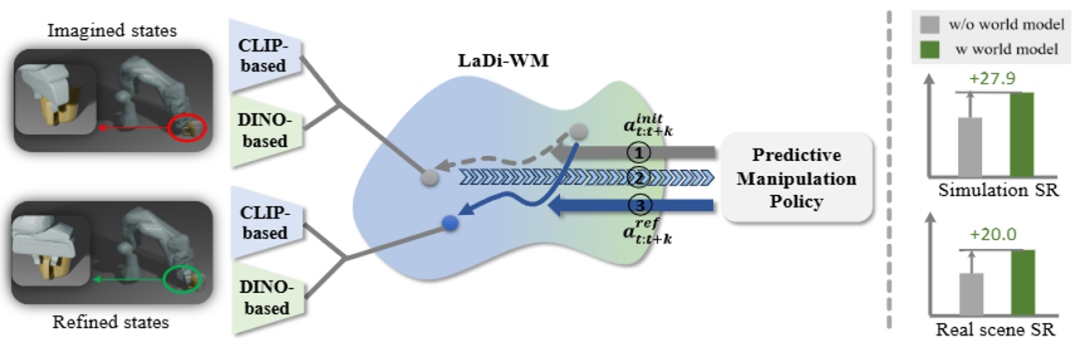
为解决上述问题,国防科大、北京大学、深圳大学团队提出 LaDi-WM(Latent Diffusion-based World Models),一种基于隐空间扩散的世界模型,用于预测隐空间的未来状态。
具体而言,LaDi-WM 利用预训练的视觉基础模型 (Vision Fundation Models) 来构建隐空间表示,该表示同时包含几何特征(基于 DINOv2 构造)和语义特征(基于 Siglip 构造),并具有广泛的通用性,有利于机器人操作的策略学习以及跨任务的泛化能力。
基于 LaDi-WM,团队设计了一种扩散策略,该策略通过整合世界模型生成的预测状态来迭代地优化输出动作,从而生成更一致、更准确的动作结果。通过在虚拟和真实数据集上的大量实验,LaDi-WM 能够显著提高机器人操作任务的成功率,尤其是在 LIBERO-LONG 数据集上提升 27.9%,超过之前的所有方法。

-
论文地址:https://arxiv.org/abs/2505.1152
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









