




内容来自计算机科研圈
分享一个大模型时代很香的研究方向:迁移学习+多模态融合。
众所周知,多模态模型由于全量微调成本过高,对高效迁移一直需求旺盛。再加上模态对齐的问题、人工标注数据的成本...当下对迁移学习+多模态融合的研究也就更热情了。
不过显然,这方向的创新也基本围绕以上问题展开,比如模型高效迁移与参数更新、任务驱动动态融合、统一知识迁移框架、鲁棒迁移与领域泛化等等。如果想发论文,建议先从这些切入点着手。
本文整理了3篇迁移学习+多模态融合新论文,意在帮助各位了解前沿,掌握思路,然后运用到自己的文章中,有需求自取~
Google is all you need: Semi-Supervised Transfer Learning Strategy For Light Multimodal Multi-Task Classification Model
方法:论文提出了一种多模态融合的多标签图像分类模型,通过迁移学习将图像处理(CNN)和文本处理(NLP)模型结合,利用特征融合模块整合视觉和文本信息,提升分类准确性和效率。
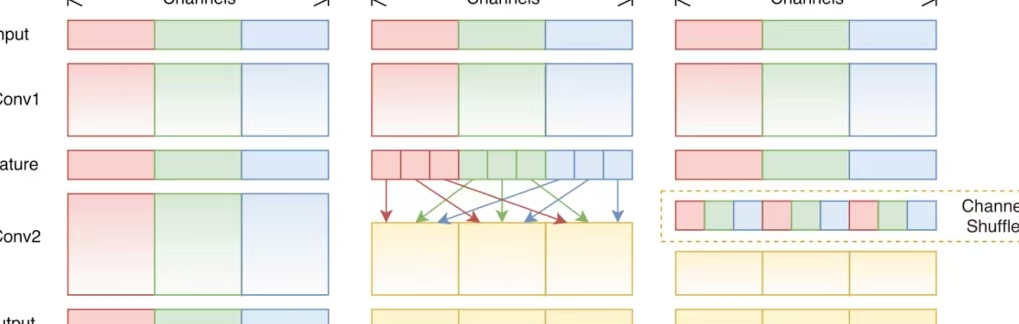
创新点:
-
提出一种多模态多标签图像分类模型,融合图像和文本特征以提升分类准确性。
-
采用迁移学习冻结预训练模型权重,结合数据增强和加权损失函数优化性能。
-
引入半监督学习和交叉注意力机制,增强模型对多模态数据的融合能力和泛化性能。
MedMimic: A Physician-Inspired Multimodal Fusion Framework for Early Diagnosing Fever of Unknown Origin
方法:论文提出了一种名为MedMimic的多模态融合框架,用于早期诊断不明原因发热(FUO)。其核心方法是利用预训练模型提取PET/CT影像数据的特征,并通过自注意力机制将这些特征与临床数据进行融合,从而提高诊断准确性。
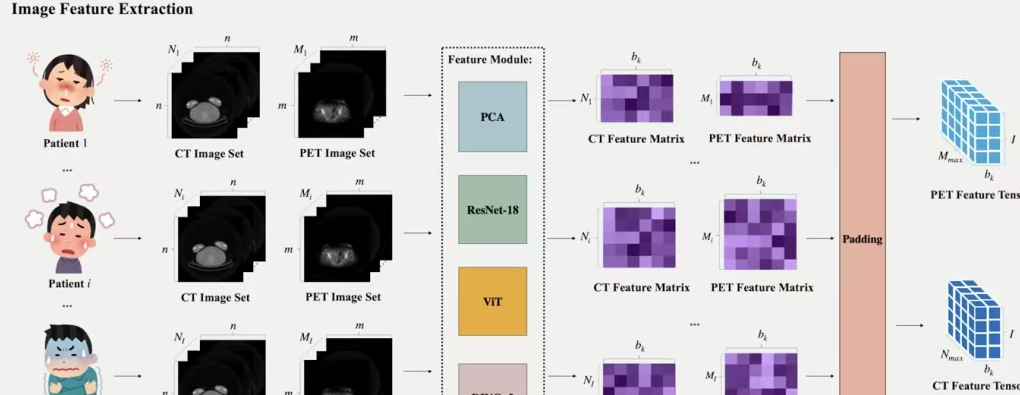
创新点:
-
提出MedMimic框架,利用预训练模型将高维PET/CT影像数据转化为语义特征张量。
-
引入可学习的自注意力机制,动态融合影像特征与临床数据,生成紧凑且具有区分性的特征表示。
-
通过多模态融合分类网络,实现对不明原因发热的早期诊断,显著优于传统单模态方法。

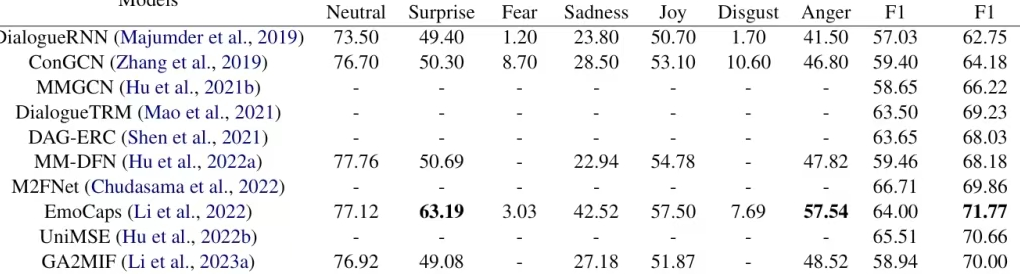
TelME: Teacher-leading Multimodal Fusion Network for Emotion Recognition in Conversation
方法:论文提出了一种名为TelME的多模态融合网络,用于对话中的情感识别。其核心方法是利用文本模态作为“教师”,通过知识蒸馏增强音频和视觉模态的特征,然后通过注意力机制将这些模态的特征进行融合,从而提高情感识别的准确性。
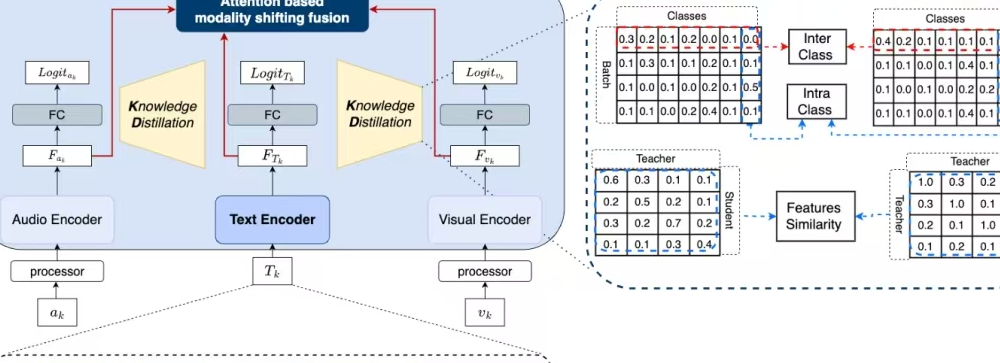
创新点:
-
提出TelME框架,利用文本模态作为“教师”模型,通过知识蒸馏增强音频和视觉模态的特征提取能力。
-
引入基于注意力机制的模态转移融合方法,将增强后的音频和视觉特征与文本特征进行融合,提升情感识别的准确性。
-
实验结果:在两个数据集上表现很好,尤其在多人对话场景中效果最佳。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









