 多模态特征融合:科研热门方向
多模态特征融合:科研热门方向




💡内容来自gongzhonghao图灵学术AI科研
小编给大家推荐一个高潜力、高回报的研究方向:多模态特征融合。从近期各大顶会的论文占比上就可以看出,这方向仍然是今年的发文热点,尤其在人工智能、医学、自动驾驶等垂直领域。
现在顶会对解决实际问题的创新方法接受度较高,而多模态特征融合能够提升模型的性能、鲁棒性和应用范围,又得益于其通用性,在教育、娱乐、人机交互等多样化场景中都十分适用。
因此这方向无论是创新性,还是发展前景都非常可观,论文er可冲。同时也建议各位结合Mamba等新兴模型与具体应用场景做创新。
1、G2D: Boosting Multimodal Learning with Gradient-Guided Distillation
方法:G2D框架设计了融合损失函数,整合多模态学生损失、特征蒸馏损失和逻辑蒸馏损失,基于置信度排名生成梯度调制系数,确保多模态学生模型高效利用知识蒸馏提升特征对齐能力和分类回归性能。
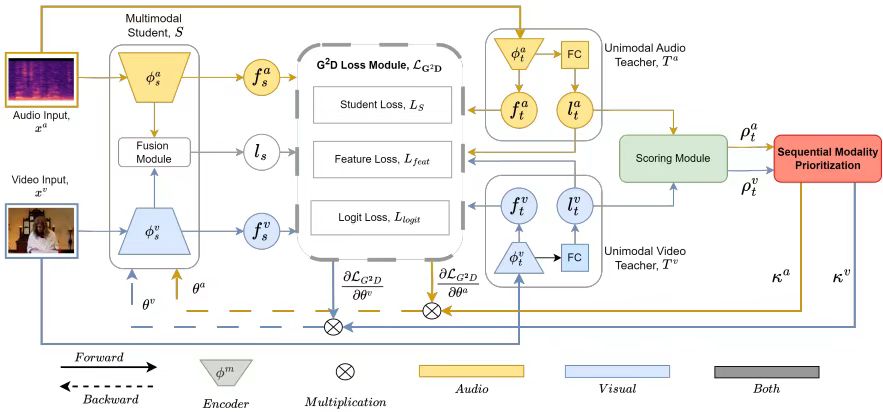
创新点:
-
提出Gradient-Guided Distillation (G2D)框架,融合单模态和多模态目标,通过知识蒸馏优化弱模态利用。
-
引入Sequential Modality Prioritization (SMP)技术,动态调制梯度以优先训练弱模态,避免主导模态的阴影效应。
-
基于单模态教师置信度分数量化模态不平衡,实现自适应训练策略,无需手动调参。

关注计算机科研圈获取ccf/sci发文资讯~
2、DALR: Dual-level Alignment Learning for Multimodal Sentence Representation Learning
方法:DALR设计跨模态一致性任务,基于二元分类框架生成语义相似性软目标,通过余弦嵌入损失动态软化负样本在共享空间优化句子嵌入的判别性与一致性。
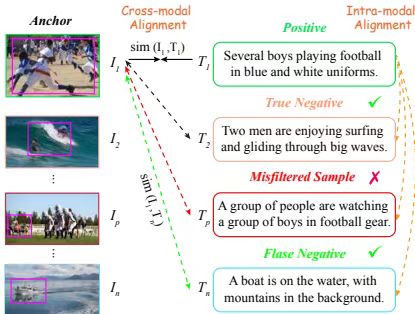
创新点:
-
通过软化负样本与辅助任务语义相似性矩阵,实现细粒度图文对齐,缓解跨模态错位偏差。
-
引入多教师排名蒸馏与KL散度优化,捕获连续语义结构以消除模态内语义分歧。
-
首次整合跨模态与模态内对齐损失,端到端提升句子表示判别力。
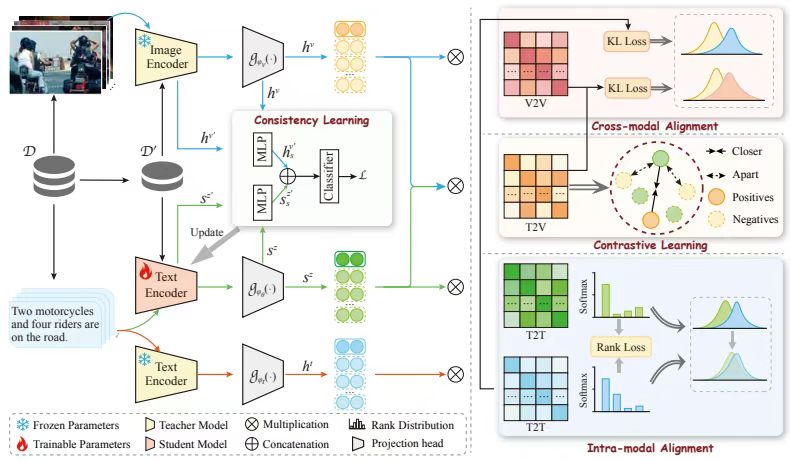
3、A Multi-Stage Framework for Multimodal Controllable Speech Synthesis
方法:设计跨模态对齐损失,通过权重共享分类模块实现基础语义关联,结合相似性矩阵蒸馏迁移教师模型知识,实现面部、文本或语音输入任意组合的灵活控制生成,支持多模态条件驱动的语音合成输出。
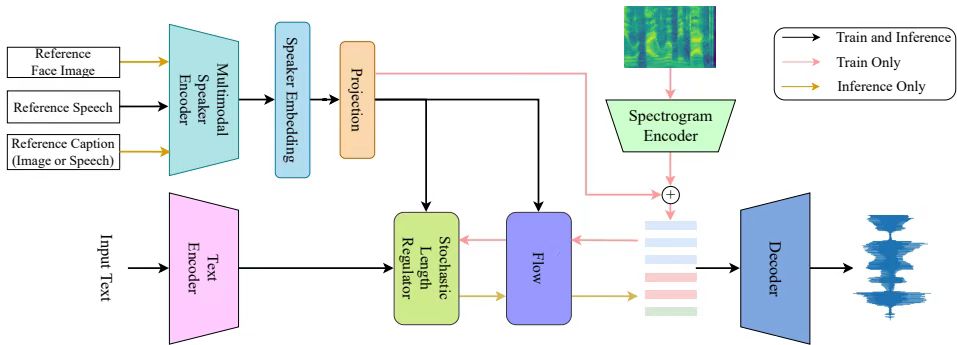
创新点:
-
融合监督学习与教师模型蒸馏,显著提升面部编码器的泛化能力与抗干扰性。
-
联合文本-面部与文本-语音数据训练编码器,突破文本提示的多样性局限。
-
将语音-面部-文本的强依赖转化为弱耦合数据训练,消除多模态数据严格匹配需求。
关注计算机科研圈获取ccf/sci发文资讯~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









