



 本文深入介绍了Kafka消息系统,包括其异步通信、发布订阅模式以及Kafka架构中的ISR机制。讨论了一致性原则,如消费者和存储一致性,并解析了消费者分配策略。同时,讲解了Kafka的安装配置步骤和常用操作,以及Windows和Linux环境下的Producer和ConsumerAPI使用。此外,还提出了常见的问题及解决方案,如解决消费堵塞和实现幂等性。
本文深入介绍了Kafka消息系统,包括其异步通信、发布订阅模式以及Kafka架构中的ISR机制。讨论了一致性原则,如消费者和存储一致性,并解析了消费者分配策略。同时,讲解了Kafka的安装配置步骤和常用操作,以及Windows和Linux环境下的Producer和ConsumerAPI使用。此外,还提出了常见的问题及解决方案,如解决消费堵塞和实现幂等性。
文章目录
1.消息系统
消息队列
- 异步通信
- 实现削峰操作
- 解决生产者,消费者处理消息不一致
发布订阅模式
- 消费者主动拉取消息(kafka) 缺点:若队列中没有消息,消费者任然会不断询问是否有消息
- 队列发送给消费者(公众号) 缺点:消费者的处理能力不同会造成资源浪费或者处理过载
kafka架构
-
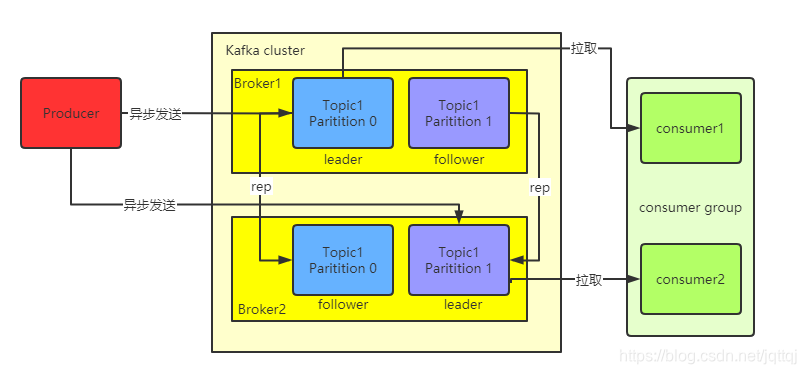
消费者只会从leader拉取消息,follower只负责备份,同一个消费组里的消费者不能消费同一个分区的消息
-
zookeeper存储Kafka的集群信息
-
在 Kafka 中的每一条消息都有一个Topic。生产者生产的每条消息只会被发送到一个Partition中,通过Offset 可以确定在该Partition下的唯一消息。Broker负责接收和处理客户端发送过来的请求,以及对消息进行持久化。
-
ISR机制:
topic中每一个leader接收到消息后会传给其他副本,若某一个副本发生故障没有同步leader的消息,会被剔除ISR;若leader发生故障,会在ISR中的follower中推选出新的leader
一致性原则
-
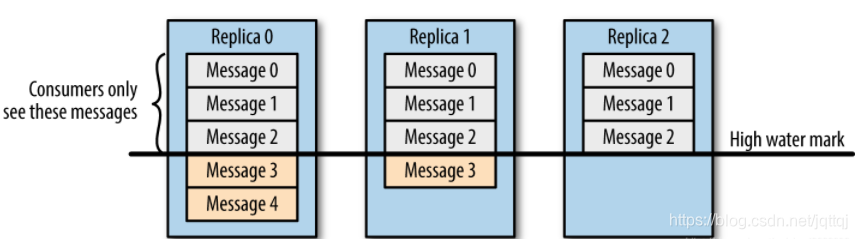
消费者一致性
当某个leader发生故障后,ISR中的新leader与其他follower的存储是不一致的,标注所有副本中的LEO(log end offset)即最大offect,确定队列中的HW(high watermark)即ISR队列中最小的LEO。HW之前的消息才会对消费者可见。
-
存储一致性
故障发生后由于新leader与follower的存储是不一致的,系统会将follower中高于HW的部分全部裁掉,然后从新leader同步数据。
消费者分配策略
该策略只有在消费者数量发生变化时才生效
-
RoundRobin(轮询):轮询消费partition,但必须保证消费组中所有消费者订阅的是同一个topic
-
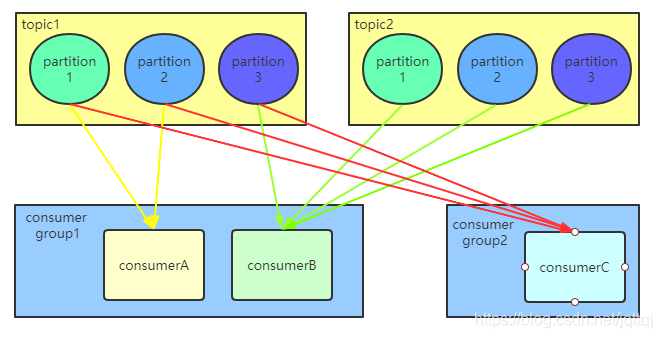
Range(默认):
举个栗子:
有两个主题t1,t2,它们都有三个分区;有两个消费者组,第一组里有A,B两个消费者,第二组里有消费者C;其中A订阅了t1,B订阅了t1,t2,C订阅了t1
文件存储结构
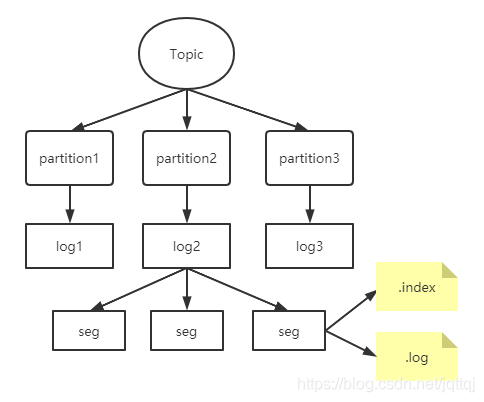
每一个topic中存储着不同的partition,生产者会不断地将消息追加到log文件中,为了防止文件过大,log又会分为多个segment,每个segment都有两个文件,其中log中存储消息数据,index存储大小相同的偏移量
常见问题
-
kafka堵塞的原因/解决
消费能力不足:增加topic的分区数量,增加消费者,二者要相等
下游数据处理不及时:提高每次拉取的数量 -
如何实现幂等性
Producer 的幂等性指的是当发送同一条消息时,数据在 Server 端只会被持久化一次,数据不丟不重 ,但是仅限于单个partition中,跨partition 需要使用 Kafka 的事务性来实现
2.安装配置
配置三台虚拟机,分别配置好zookeeper,Java
将kafka的安装包分别解压到/usr/local,在config目录中修改如下内容
#Slave1中
broker.id=0
zookeeper.connect=Slave1:2181,Slave2:2181,Slave3:2181
log.dirs=/usr/local/kafka/log
#Slave2中
broker.id=1
zookeeper.connect=Slave1:2181,Slave2:2181,Slave3:2181
log.dirs=/usr/local/kafka/log
#Slave3中
broker.id=2
zookeeper.connect=Slave1:2181,Slave2:2181,Slave3:2181
log.dirs=/usr/local/kafka/log
在三台虚拟机上手动启动zookeeper,cd到kafka目录下,输入命令在后台运行
#启动服务
zkServer.sh start
bin/kafka-server-start.sh -daemon config/server.properties
Kafka常用操作
#创建名为test02_02的topics (2 partitions & 2 replication-factor)
bin/kafka-topics.sh --bootstrap-server Slave1:9092 --create --topic test_02_02 --replication-factor 2 --partitions 2
#查看topics
bin/kafka-topics.sh --list --zookeeper Slave1:2181
#查看topics详细信息
bin/kafka-topics.sh --bootstrap-server Slave1:9092 --describe --topic test_02_02
#Topic: test_02_02 Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2
#Topic: test_02_02 Partition: 1 Leader: 0 Replicas: 0,1 Isr: 0,1
#创建生产者(发送消息)
bin/kafka-console-producer.sh --broker-list Slave1:9092,Slave2:9092,Slave3:9092 --topic test_02_02
#创建消费者(接收消息)
#–from-beginning:会把topic中以往所有的数据都读取出来,只读取partition 0
bin/kafka-console-consumer.sh --bootstrap-server Slave1:9092 --topic test_02_02 --partition 0 --from-beginning
3.开发环境API
1.ProducerAPI:在windows端发送消息,指定partition接收
public class TestProducer {
public static void main(String[] args){
String topic = "test_02_02";
Map<String,Object> kafkaProperties = new HashMap<>();
kafkaProperties.put("bootstrap.servers","Slave1:9092,Slave2:9092,Slave3:9092");
kafkaProperties.put("acks", "all");
kafkaProperties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
kafkaProperties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(kafkaProperties);
//指定partition 0 接收
for (int i = 0; i < 10; i++)
producer.send(new ProducerRecord<>(topic, 0,"key_"+ Integer.toString(i), Integer.toString(i)));
producer.close();
System.out.println("消息发送完成!");
}
}
2.ConsumerAPI:在Linux端发送数据到指定partition,windows端接收
public class TestConsumer {
public static void main(String[] args){
String topic = "test_02_02";
String group = "test_group";
Map<String,Object> kafkaProperties = new HashMap<>();
kafkaProperties.put("bootstrap.servers","Slave1:9092,Slave2:9092,Slave3:9092");
kafkaProperties.put("group.id", group);
kafkaProperties.put("enable.auto.commit","true");
kafkaProperties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
kafkaProperties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(kafkaProperties);
consumer.assign(Arrays.asList(new TopicPartition(topic,0)));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n ", record.offset(), record.key(), record.value());
}
}
}

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









