



 该博客介绍了如何在Hive中编写用户定义函数(UDF)来判断日期属于哪个季度。首先创建数据库和表,导入数据,然后在IDEA中重写`evaluate`方法,将日期字符串转换为Date对象,并通过Calendar获取季度信息。最后,打包UDF为jar文件,上传到Hive并创建临时函数,用于查询数据表中的季度分布。
该博客介绍了如何在Hive中编写用户定义函数(UDF)来判断日期属于哪个季度。首先创建数据库和表,导入数据,然后在IDEA中重写`evaluate`方法,将日期字符串转换为Date对象,并通过Calendar获取季度信息。最后,打包UDF为jar文件,上传到Hive并创建临时函数,用于查询数据表中的季度分布。
编写UDF,实现季度的判断,具体过程如下:
- 编写sql脚本创建数据库,表,导入数据
create database if not exists udf; use udf; create table if not exists quarterUDF( dates string, name string) row format delimited fields terminated by ','; load data local inpath '/XX/udfdata.csv' overwrite into table quarterUDF; - 在IDEA中重写evaluate方法
public class QuarterUDF extends UDF {
//测试
public static void main(String[] args) throws ParseException {
evaluate("2021/10/3", "yyyy/MM/dd");
}
public static String evaluate(String datestr, String dateformat) throws ParseException {
//将字符串类型的日期转为Date
SimpleDateFormat sd = new SimpleDateFormat(dateformat);
Date date = sd.parse(datestr);
//通过Calendar获取年份和月份
Calendar calendar = Calendar.getInstance();
calendar.setTime(date);
int year = calendar.get(Calendar.YEAR);
int month = calendar.get(Calendar.MONTH)+1;
int day=calendar.get(Calendar.DAY_OF_MONTH);
//通过判断区分季度
System.out.println(year+":"+month+":"+day);
if(month>=1 && month<=3) {return year+"first";}
else if(month>=4 && month<=6) {return year+"second";}
else if(month>=7 && month<=9) {return year+"third";}
else {return year+"forth";}
}
}
- 打包,在hive中上传jar包,创建临时函数并使用
maven工程中双击Lifecycle中的package完成打包,将jar上传到Linux
在hive-shell界面输入:
#添加jar包
add jar /home/jqt/jar/udf_practise-1.0.1.jar;
#as后为实现类的全路径
CREATE TEMPORARY FUNCTION quarter AS 'myudf.QuarterUDF';
#使用UDF
select quarter(dates) from quarterudf;
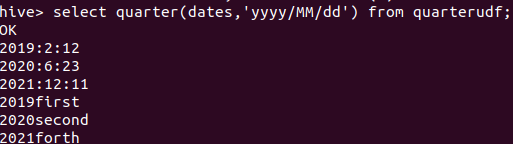
演示结果:


















 1553
1553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









