




大家好,我是 Ai 学习的老章
Kimi 也算我们的常客,尤其是 K2 模型,十分亮眼,目前也是我 Agent 常配模型之一
Kimi K2 基于 DeepSeek V3 框架,为何没有被骂
Kimi K2 高效 RL 参数更新,从 10 分钟到 20 秒的技术突破
Claude Code 使用教程,对接 DeepSeek-R1 和 Kimi K2
如何运行 Kimi K2 这个庞然大物(API & 本地部署)
Kimi 内部员工:《Kimi K2 之后:再也不仅仅是 ChatBot》
昨晚Kimi-K2-Thinking 终于来了!只在官方 API 文档中更新了模型信息,我也做了一个小测试,还不错,刚刚模型文件开源,技术博客也发布了,本文做个梳理。
K2 Thinking 简介
kimi-k2-thinking 模型是具有通用 Agentic 能力和推理能力的思考模型,它擅长深度推理,并可通过多步工具调用,帮助解决各类难题。
什么让它与众不同:
⚡ 原生 INT4 量化 → 2 倍快速推理
💾 占用内存减半,无精度损失
🎯 256K 上下文,支持 200-300 次工具调用
官方释放的基准测试结果:
🔹 在 HLE (44.9%) 和 BrowseComp (60.2%) 上达到 SOTA
🔹 最多可以执行 200 – 300 个连续的工具调用 无需人工干预
🔹 在推理、自主搜索和编程方面表现出色
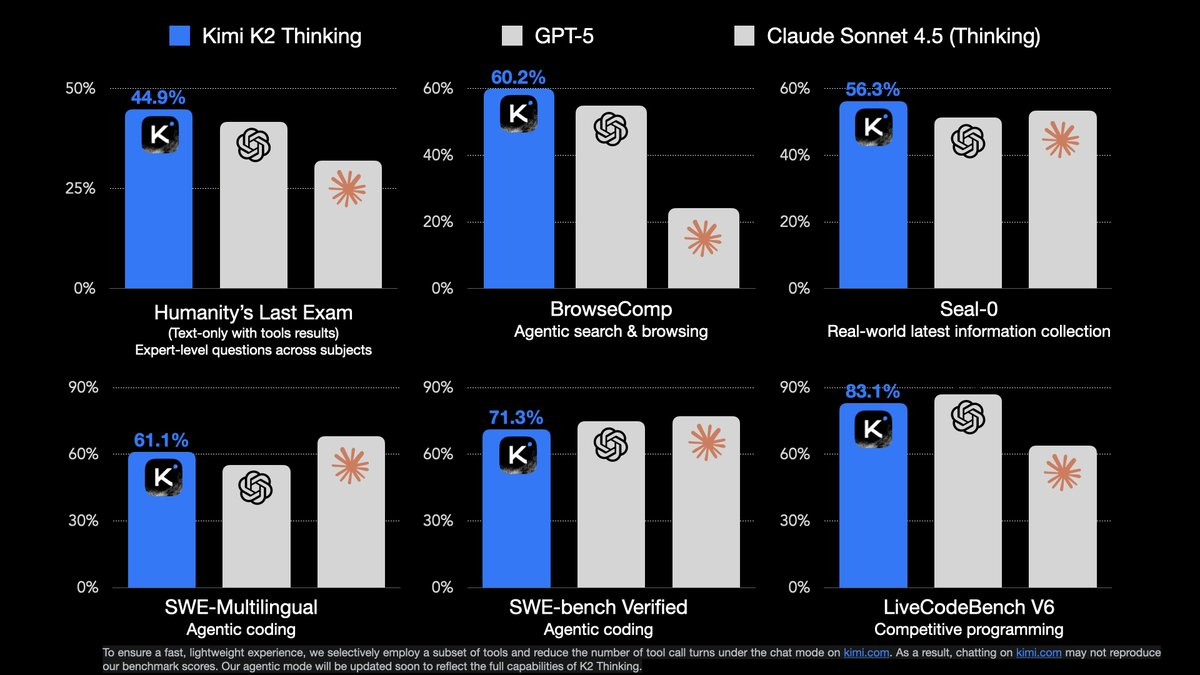
需要指出的是,Kimi 非常自信的与最强的闭源模型进行对比,在多个基准中结果反超闭源模型。
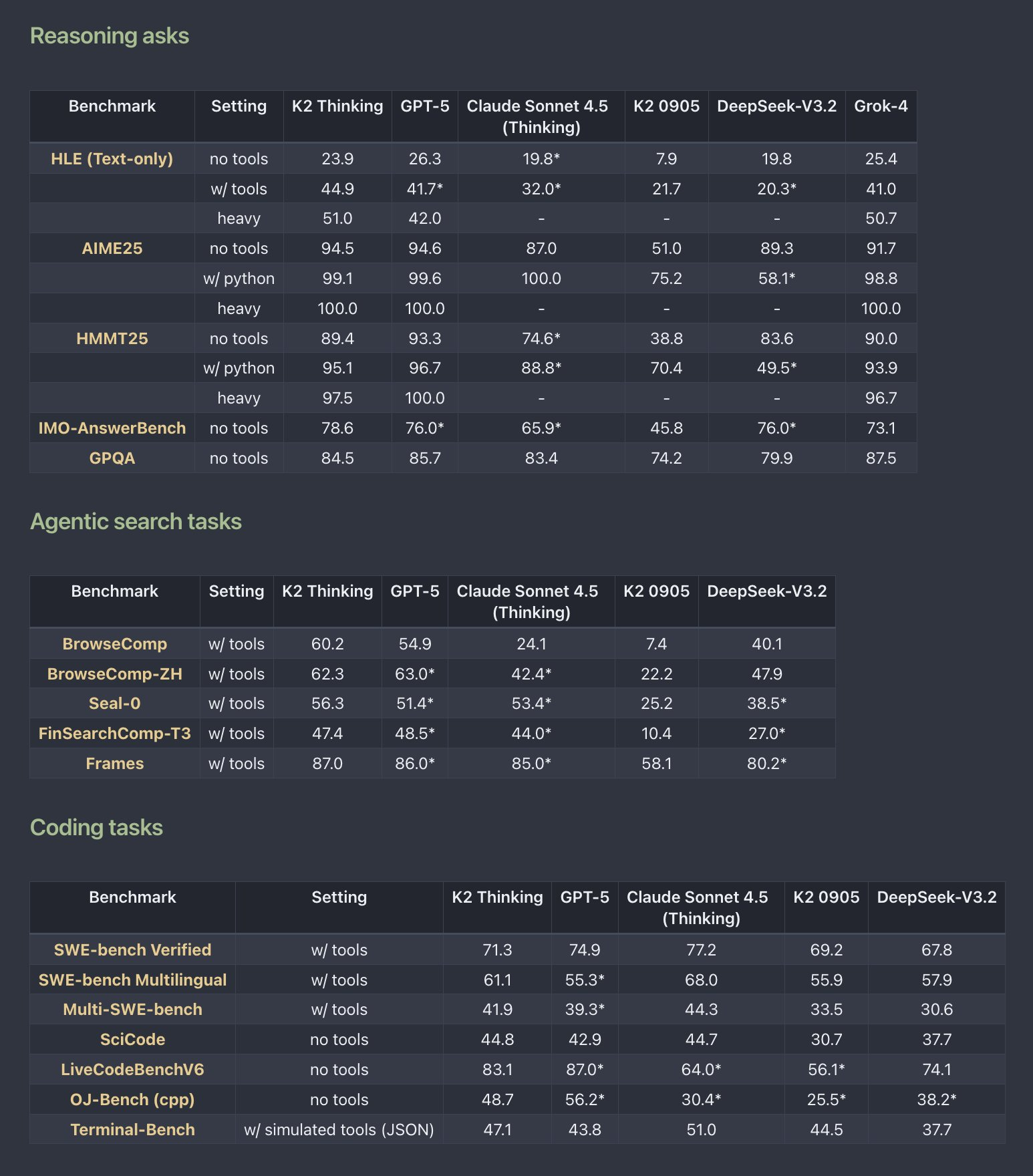
下面是更全面的对比结果,确实不需要与其他开源模型比参数了:
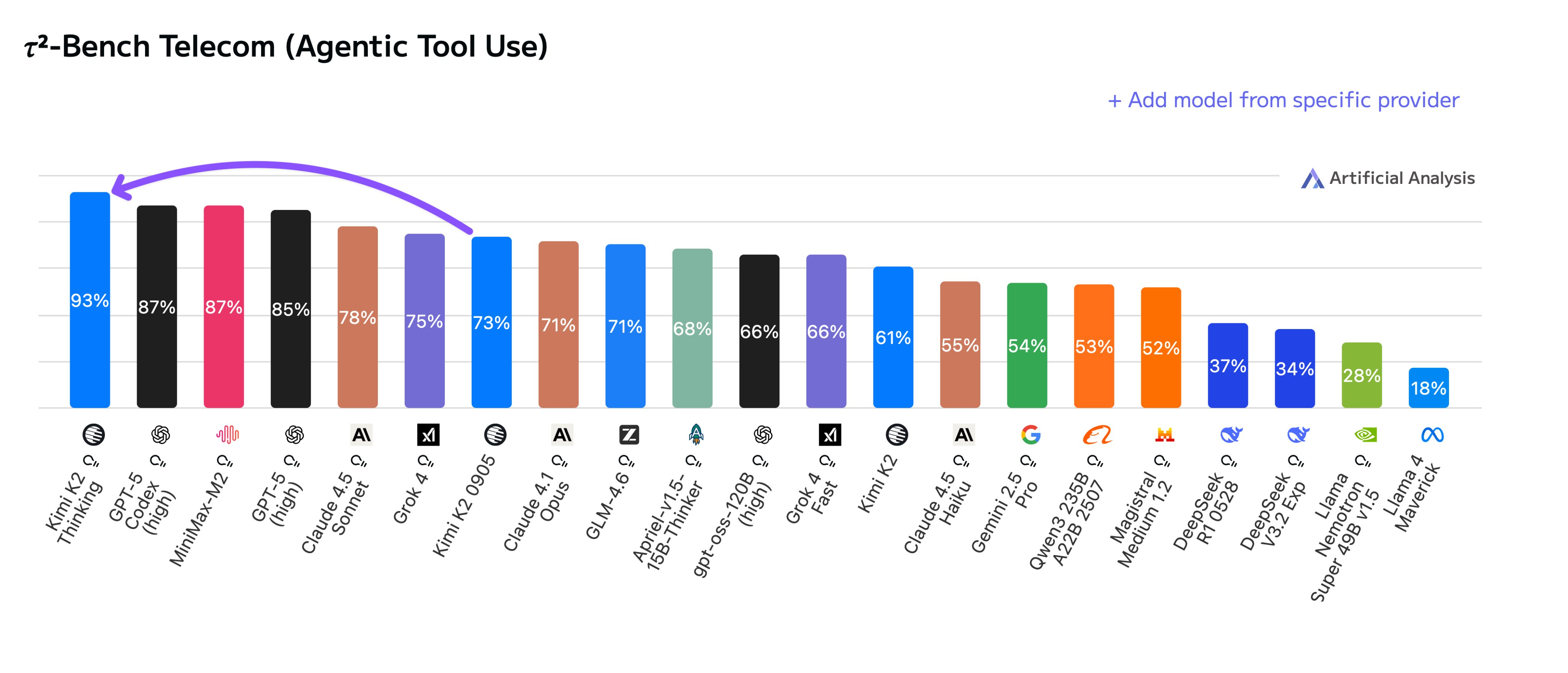
artificialanalysis.ai 也对 Kimi K2 Thinking 做了基准测试,结果也十分优秀
➤ Kimi K2 Thinking 在 𝜏²-Bench Telecom 代理工具使用基准测试中获得了 93% 的成绩,这是一个 agentic tool 基准测试,模型作为客户服务代理进行操作。在长期代理上下文中的工具使用是 Kimi K2 Instruct 的强项,而新的 Thinking 变体在此方面取得了显著进步。
K2 Thinking 本地部署
K2 Thinking 的模型文件只有 594GB
K2 Instruct 和 K2 Instruct 0905 的大小则超过 1TB,为何 Thinking 之后 594GB 呢?
这是因为 K2 Thinking 使用 INT4 精度而非 FP8,Moonshot 在后训练阶段使用量化感知训练来实现这一点,这意味着推理和训练的效率提升。使用 INT4 的一个潜在原因是,Blackwell 的 NVIDIA GPU 不支持 FP4,因此 INT4 更适合在较陈旧的硬件上实现效率提升。
vLLM 0Day 支持 K2 Thinking 的部署,命令如下
# 安装
uv venv
source .venv/bin/activate
uv pip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightly --extra-index-url https://download.pytorch.org/whl/cu129 --index-strategy unsafe-best-match # for xformers
# 部署
vllm serve moonshotai/Kimi-K2-Thinking \
--trust-remote-code \
--tensor-parallel-size 8 \
--enable-auto-tool-choice \
--tool-call-parser kimi_k2 \
--reasoning-parser kimi_k2 \
## `--reasoning-parser` 标志指定用于从模型输出中提取推理内容的推理解析器。

要启动 Kimi-K2-Thinking 需要 8 个 141GB 的 H200/H20,成本还是蛮高的,不过即便再量化,估计向下空间也不大了吧?已经 int4 了,还能怎样。
推荐使用 解码上下文(DCP)并行部署,添加 --decode-context-parallel-size number 来启用解码上下文并行:
vllm serve moonshotai/Kimi-K2-Thinking \
--trust-remote-code \
--tensor-parallel-size 8 \
--decode-context-parallel-size 8 \
--enable-auto-tool-choice \
--tool-call-parser kimi_k2 \
--reasoning-parser kimi_k2 \
配合 DCP 后,优势显著(43% 更快的 Token 生成,26% 更高的吞吐量),同时几乎没有缺点(中位数延迟改善微乎其微)
| 指标 | TP8 | TP8+DCP8 | 变更 | 改进 (%) |
|---|---|---|---|---|
| 请求吞吐量 (req/s) | 1.25 | 1.57 | +0.32 | +25.6% |
| 输出标记吞吐量 (tok/s) | 485.78 | 695.13 | +209.35 | +43.1% |
| 平均 TTFT(秒) | 271.2 | 227.8 | -43.4 | +16.0% |
| 中位数 TTFT(秒) | 227.4 | 227.1 | -0.3 | +0.1% |
后面我会拿之前的用例详细测试一下,同时也把 Claude code 后台模型改成 K2 Thinking 多用一用
如有能再量化同时保障效果不打大折扣,把部署成本控制在 4 卡就好了,我也可以本地部署试试了。



















 275
275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









