



大家好,我是 Ai 学习的老章

前文介绍过
vLLM v0.13.0 来了,对 DeepSeek 深度优化 全模态大模型部署,vLLM-Omni 来了,100% 开源
本文介绍一个母亲最强大的文生图模型——Z-Image-Turbo 的本地部署
Z-Image Turbo 是阿里云通义-MAI 团队(与阿里云万和 Qwen 团队无关)发布的首款模型,超越了 FLUX.2、HunyuanImage 3.0 (Fal) 和 Qwen-Image。
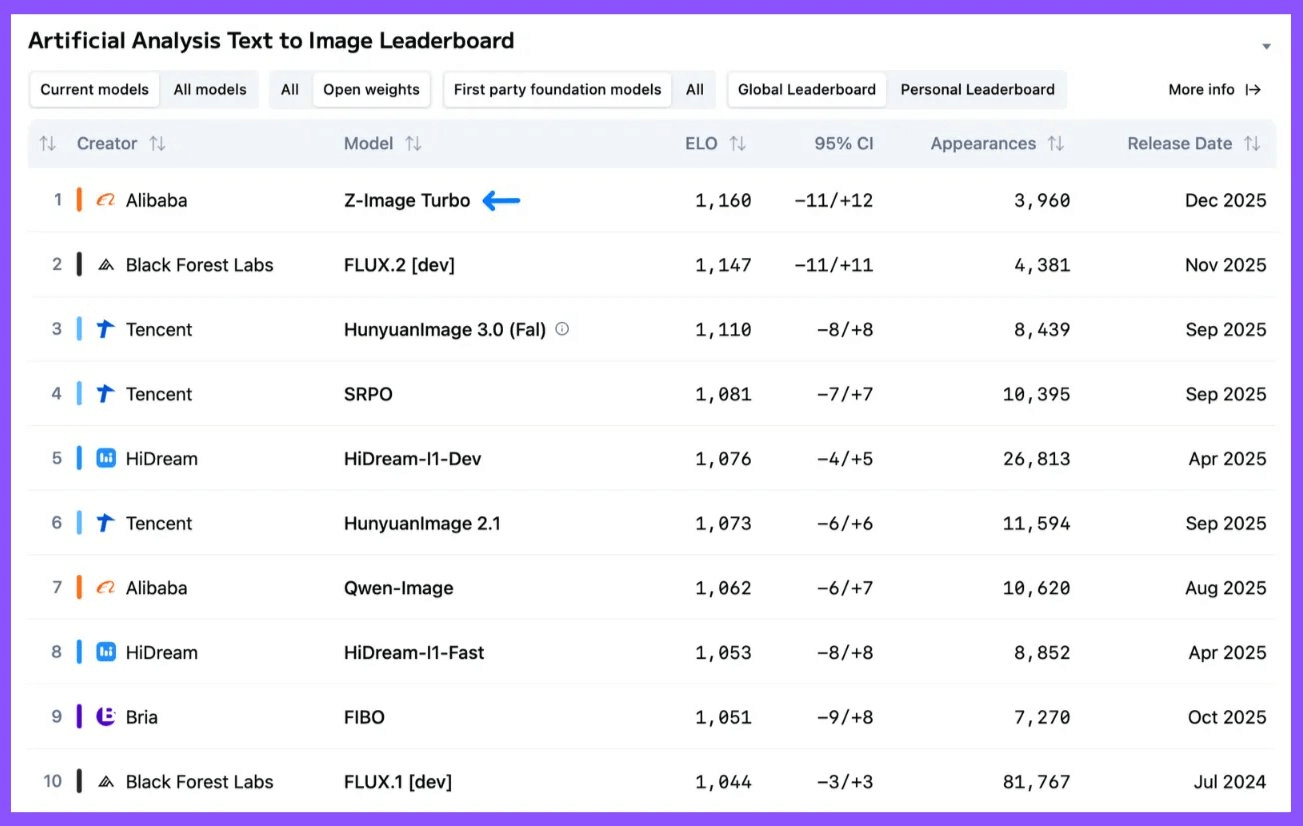
Z-Image Turbo 在阿里云上的价格为每千张图像 5 美元,是目前最便宜的图像模型之一,比 FLUX.2(每千张图像 12 美元)、HiDream-I1-Dev(每千张图像 26 美元)和 Qwen-Image(每千张图像 20 美元)都要便宜。它是一个 6B 参数模型,仅需 16GB 内存即可在消费级硬件上运行。
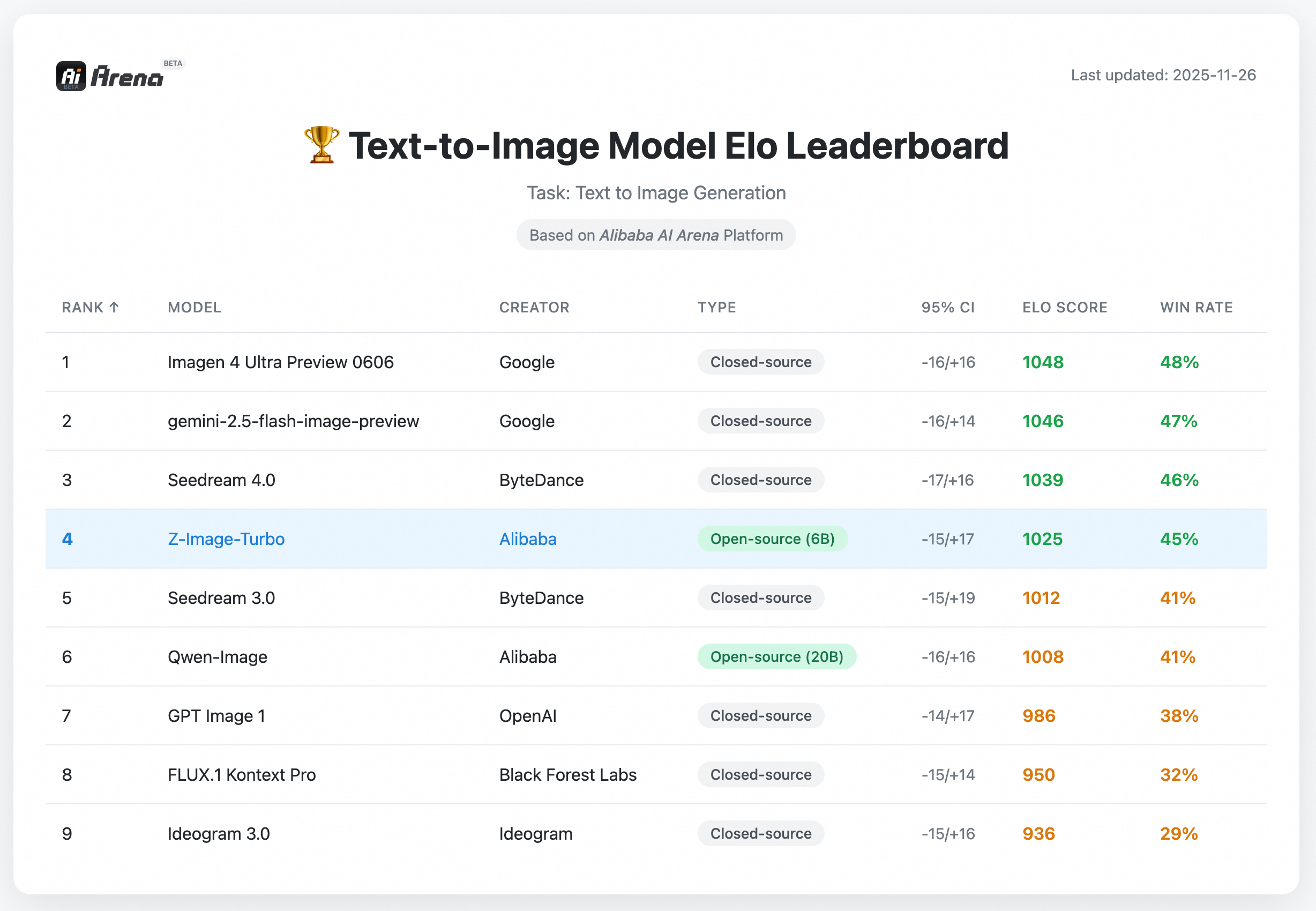
版本问题
Z-Image 是一个强大的、高效的图像生成模型,具有 6B 参数。目前有三个变体:
-
🚀 Z-Image-Turbo – Z-Image 的精简版,仅用 8 NFEs(函数评估次数)就能与领先竞争对手匹敌或超越。它在企业级 H800 GPU 上提供 ⚡️亚秒级推理延迟⚡️,并且可以在 16G 显存的消费设备上轻松运行。它擅长生成逼真的图像、双语文本渲染(英文和中文),并具有强大的指令遵循能力。 -
🧱 Z-Image-Base – 非精简的基础模型,旨在解锁社区驱动的微调和自定义开发的全部潜力。 -
✍️ Z-Image-Edit – 专门针对图像编辑任务进行微调的 Z-Image 变体。它支持创意性的图像到图像生成,并具有令人印象深刻的指令跟随能力,允许根据自然语言提示进行精确编辑。
Z-Image-Turbo 能力一览
编辑

现实

渲染


本地部署
下载完整模型库
modelscope download --model Tongyi-MAI/Z-Image-Turbo --local_dir ./dir
vLLM-Omni 部署
安装好环境后,可以使用 vllm-omni 拉起兼容 OpenAI API 协议的 API
vllm serve Qwen/Qwen-Image --omni --port 8091
没有显卡也可以直接调用 API
import requests
import time
import json
from PIL import Image
from io import BytesIO
base_url = 'https://api-inference.modelscope.cn/'
api_key = "<MODELSCOPE_TOKEN>" # ModelScope Token
common_headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
response = requests.post(
f"{base_url}v1/images/generations",
headers={**common_headers, "X-ModelScope-Async-Mode": "true"},
data=json.dumps({
"model": "Tongyi-MAI/Z-Image-Turbo", # ModelScope Model-Id, required
# "loras": "<lora-repo-id>", # optional lora(s)
# """
# LoRA(s) Configuration:
# - for Single LoRA:
# "loras": "<lora-repo-id>"
# - for Multiple LoRAs:
# "loras": {"<lora-repo-id1>": 0.6, "<lora-repo-id2>": 0.4}
# - Upto 6 LoRAs, all weight-coefficients must sum to 1.0
# """
"prompt": "A golden cat"
}, ensure_ascii=False).encode('utf-8')
)
response.raise_for_status()
task_id = response.json()["task_id"]
while True:
result = requests.get(
f"{base_url}v1/tasks/{task_id}",
headers={**common_headers, "X-ModelScope-Task-Type": "image_generation"},
)
result.raise_for_status()
data = result.json()
if data["task_status"] == "SUCCEED":
image = Image.open(BytesIO(requests.get(data["output_images"][0]).content))
image.save("result_image.jpg")
break
elif data["task_status"] == "FAILED":
print("Image Generation Failed.")
break
time.sleep(5)
前端
官方提供的有前端
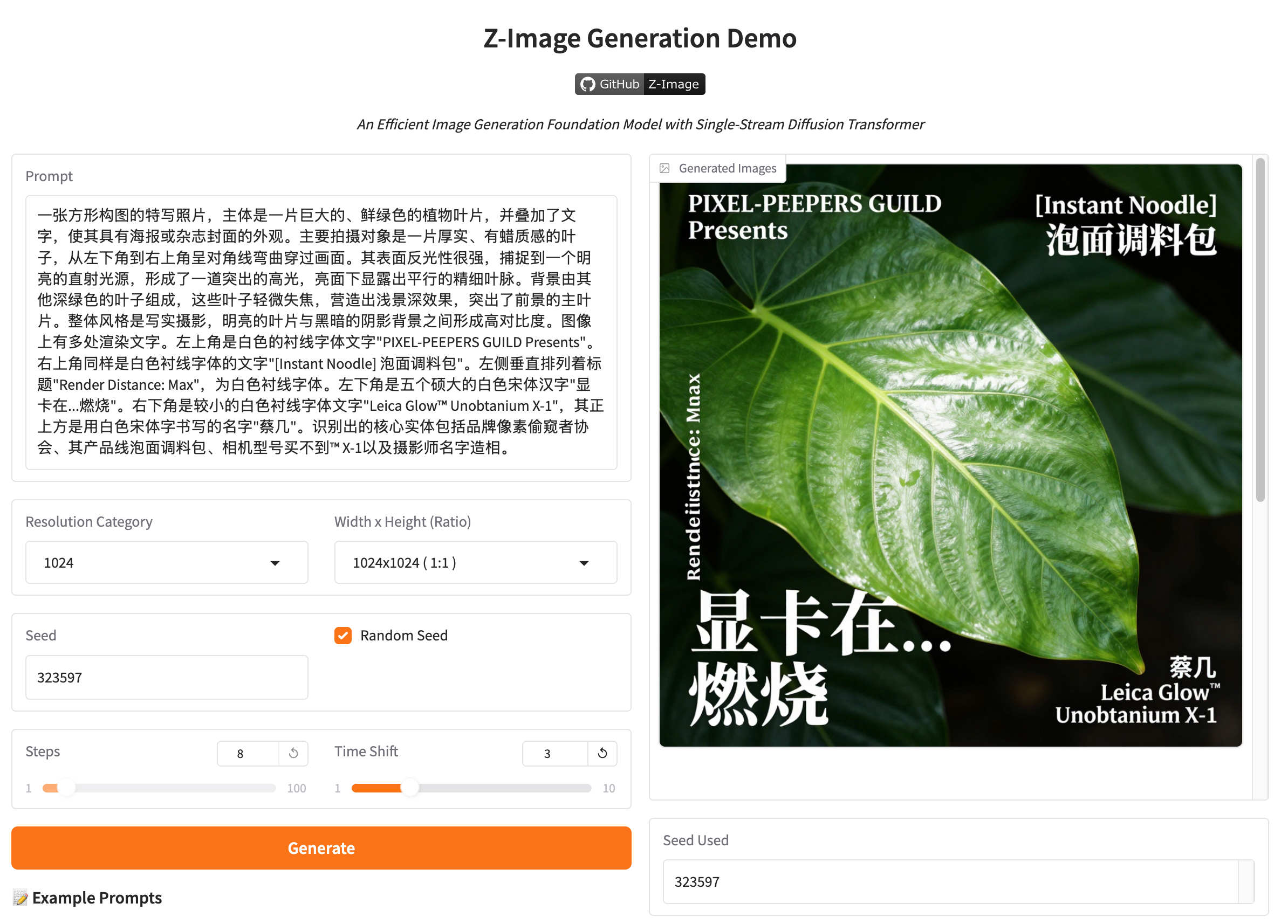
看上去是基于 Gradio 开发的,完整代码:https://huggingface.co/spaces/Tongyi-MAI/Z-Image-Turbo/tree/main
Clone 下来可以自己部署
社区有开源的基于 Z-Image-Turbo 的前端,比官方版功能更多
项目地址:https://github.com/ratszhu/Z-Image-Turbo-Carto
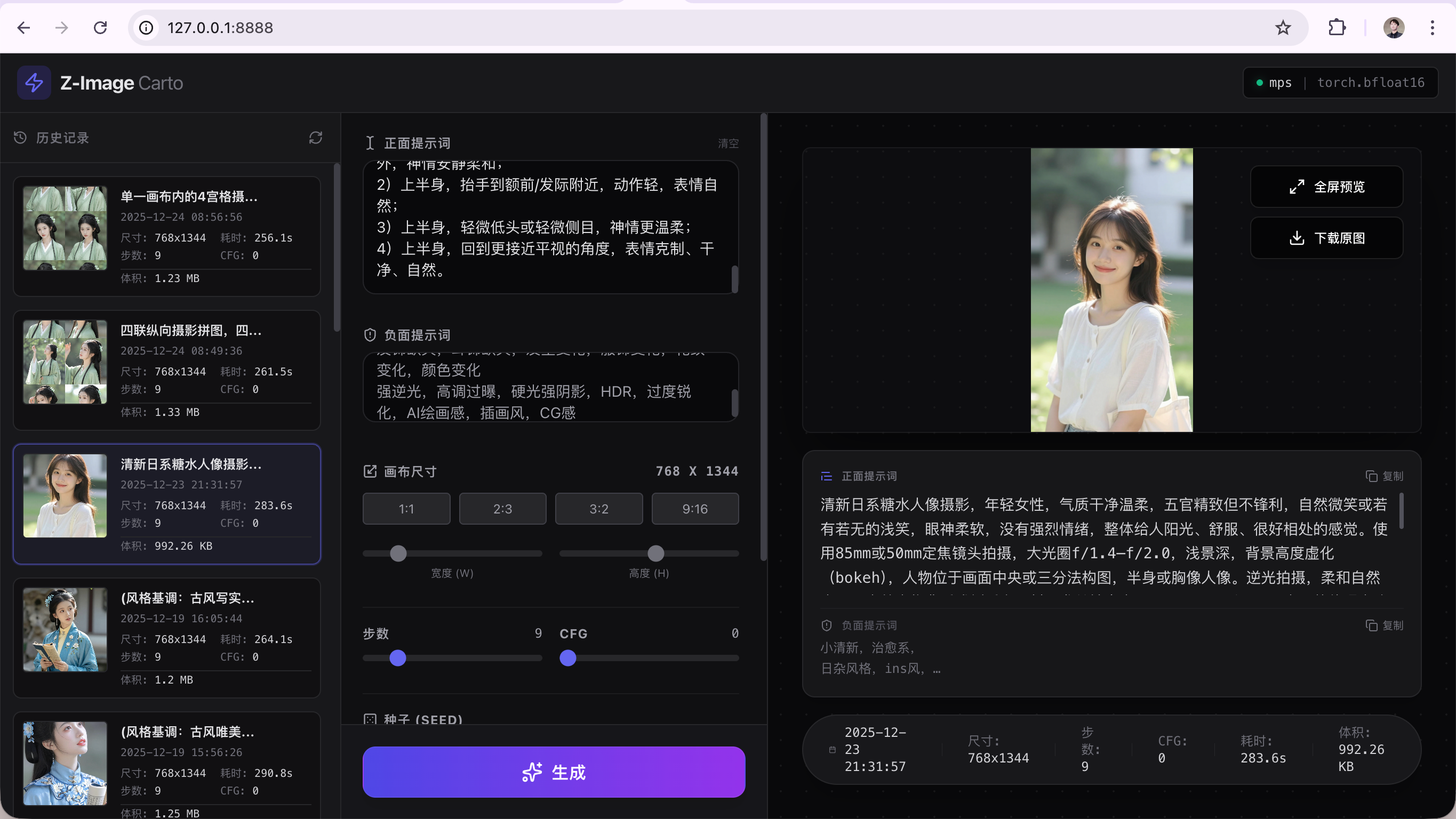
1. 环境准备
-
操作系统:macOS (Apple Silicon) 或 Windows 10/11 (NVIDIA GPU)。 -
Python:推荐 Python 3.10 或 3.11。 -
⚠️ 警告:请勿使用 Python 3.13,目前 PyTorch 对其支持尚不稳定。
-
2. 安装依赖
在项目根目录下打开终端:
# 1. 创建虚拟环境 (推荐)
python -m venv venv
# Mac/Linux 激活:
source venv/bin/activate
# Windows 激活:
.\venv\Scripts\activate
# 2. 安装依赖 (使用清华源加速)
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
3. 模型准备
请确保项目根目录下存在以下文件(或在 config.py 中修改路径):
-
基础模型: ./Z-Image-Model-
从 Hugging Face 下载 Tongyi-MAI/Z-Image-Turbo完整文件夹。
-
-
LoRA 文件: ./Technically_Color_Z_Image_Turbo_v1_renderartist_2000.safetensors-
用于画质增强。
-
4. 启动应用
python main.py
等待终端显示: 🚀 Z-Image Studio 全栈版已启动! 👉 请访问: http://127.0.0.1:8888



















 234
234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









