




 超级会员免费看
超级会员免费看

大家好,我是Ai学习的老章
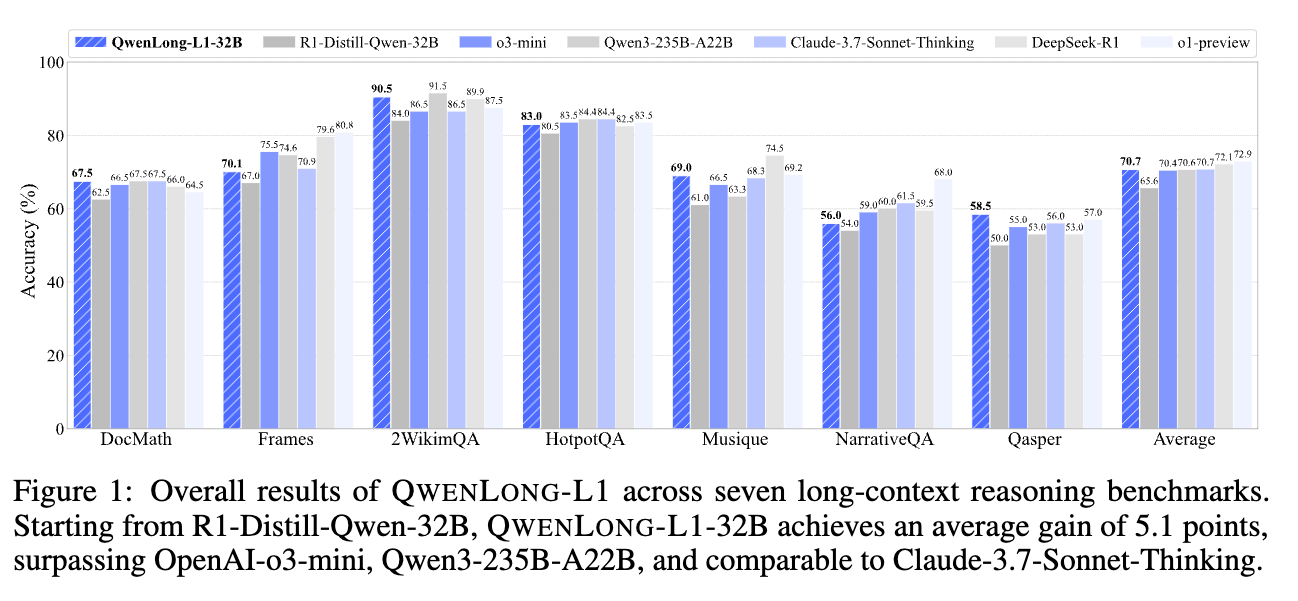
阿里又开源新模型了,这次是通义千问文档团队带来的 QwenLong-L1-32B——首个通过强化学习训练、专为长上下文推理设计的大语言模型。
解决的问题是:
大型推理模型(LRMs)通过强化学习(RL)展现出强大的推理能力,但局限于短上下文推理任务,这个 QwenLong-L1 框架,通过渐进式上下文扩展将短上下文 LRMs 适配至长上下文场景。

效果:
在七个长上下文文档问答基准测试上的实验表明,QwenLong - L1 - 32B 优于 OpenAI - o3 - mini 和 Qwen3 - 235B - A22B 等旗舰大推理模型,性能与 Claude - 3.7 - Sonnet - Thinking 相当,在当前最先进的大推理模型中表现领先。
框架通过强化学习训练中的渐

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 457
457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









