




什么是shell
shell是一个命令解释器,在操作系统的最外层,将用户输入的命令翻译给操作系统.
什么是shell脚本
将系统命令堆积在一起,顺序执行;
特定的格式+特定的语法+系统命令 = 文件
shell的基本规范
- 存放固定目录:/scripts
- 开头加 #!/bin/bash 指定解析程序
- 脚本扩展名:.sh
shell的执行
1.脚本中第一行 #!/usr/bin/bash
脚本中如果不写,在执行过程中如果./方式执行(需要权限),默认调用bash命令翻译该文件
脚本中如果写了使用什么解释器翻译,那么使用./时则会调用对用的解释器执行
首先chmod +x 文件名 加可执行权限
再 ./文件名执行
2.bash 脚本 —无需权限,直接调用解释器翻译
3.sh 脚本
/bin/bash 脚本名
shell变量
变量名不能使用“横杠”,首个字符必须为字母
变量中有空格则使用双引号
使用 $变量名 可以得到变量值,${变量名}也可以
双引号会将变量的值解析,单引号会直接输出内容,不进行解析
readonly 加变量名 只读,后面不能修改
unset 加变量名 删除变量 后面不能用
字符串的长度: ${#变量的名字}
提取子字符串: ${字符串的名字:1:4}从第2个字符开始截取4个字符
系统环境变量
export- - - 打印系统环境变量
export 变量名=变量值 - - - 将变量设置为环境变量,同一个Bash中可以使用
运算符
使用反引号:`expr 1+2`
两个变量相加:`expr ${a}+${b}`
执行脚本时传入参数
read:执行脚本后等待参数的输入
bash 文件名 参数1 参数2 …
echo"#当前shell脚本的文件名:$0"
echo"#第1个shell脚本位置参数:$1"
echo"#第2个shell脚本位置参数:$2”
echo"#第3个shell脚本位置参数:$3"
echo“#所有传递的位置参数是:$*"
echo"#所有传递的位置参数是:$@"
echo“#总共传递的参数个数是:$#”
echo“#当前程序运行的PID是:$$"
echo"#上一个命令执行的返回结果:$?"
注:第十个参数及以上使用:${ 数字}
将命令执行的结果传递给变量
$() 括号中一定是命令
例:
$(date +%Y) - - - 2020
运算$((表达式))
$(($(date +%Y)+1 ))- - - 2021
批量创建文件 touch 文件路径/{文件名}.文件后缀
例:touch /root/{1…10}.txt
压缩解压
打包压缩文件 tar zcvf 文件路径/文件名.tar.gz 被压缩文件
嵌套命令
tar zcvf /root/etc.tar.gz $(find /etc -name “*.conf”)
查看打包文件 tar tf 压缩文件名 | less
less命令退出 :键盘q
解压文件
tar -zxvf 压缩文件名 -C 解压路径 - - - 解压路径不写则默认本目录解压
read命令通过交互式方式传递变量
#!/bin/bash
read -p "请输入:" varfile
echo "要备份的为:" $varfile
例
#!/bin/bash
read -p "请输入IP:" var
ping -W1 -c1 $var &>/dev/null
rc=$?
if [ $rc -eq 0 ];then
echo "$var 能正常通信"
else
echo "$var 无法正常通信"
fi
man 命令 可得到命令的全部用法
&>/dev/null 输入到黑洞,不显示
例如ping -c2 www.baidu.com &>/dev/null 把ping 的结果输出du到一个黑洞
覆盖符:> 文件名
追加符:>> 文件名
字符串操作
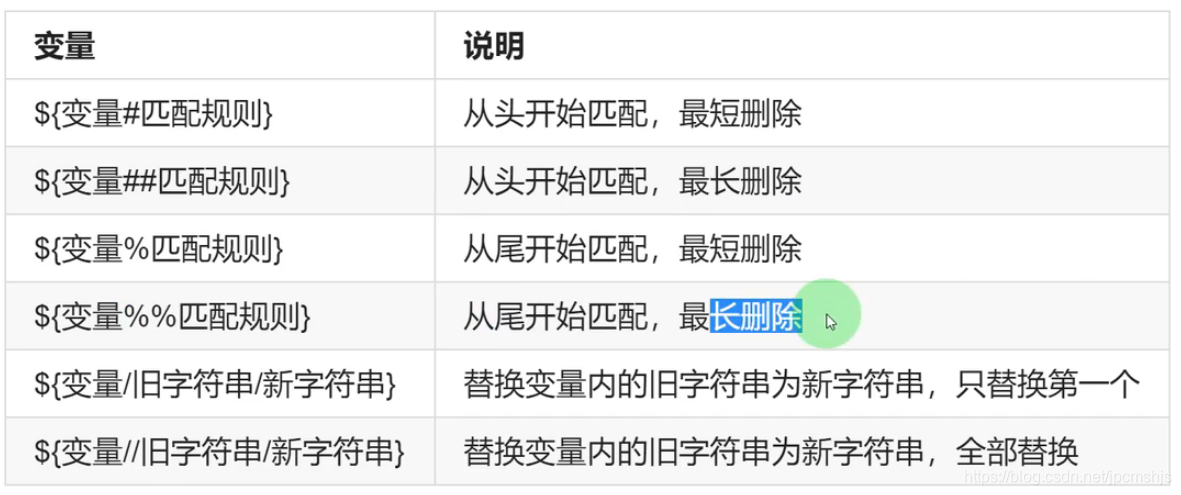
开启转义功能:-e “字符串”
version=$(cat /etc/redhat-release | awk '{print $(NF-1)}')
echo $version
#7.7.1908
echo ${version#*.}
#从头开始删除 删除第一个.前的任意值 7.1908
echo ${version##*.}
#从头开始删除,最长删除,删除最后一个.前的任意值1908
echo ${version%.*}
#从尾开始删除,删除倒数第一个.后的任意值7.7
echo ${version%%.*}
#从尾开始删除,删除最远.后的任意值 7
echo ${version/7/8}
#替换一个字符 8.7.1908
echo ${version//7/8}
#替换所有字符 8.8.1908
echo ${version//./_}
#7_7_1908
流程控制语句if
if [ 条件 ];then
条件成立执行
fi
if文件比对方式
参数说明示例
-e 如果文件或目录存在则为真 [ -e $file ]
-s 如果文件存在且至少有一个字符则为真[-s $file]
-d 如果文件存在且为目录则为真[-d $file]
-f 如果文件存在且为普通文件则为真[-s $file]
-r 如果文件存在且可读则为真[-r $file]
-w 如果文件存在且可写则为真[-w $file]
-x 如果文件存在且可执行则为真[-x $file]
在同一路径下,可写相对路径,不在时,写绝对路径
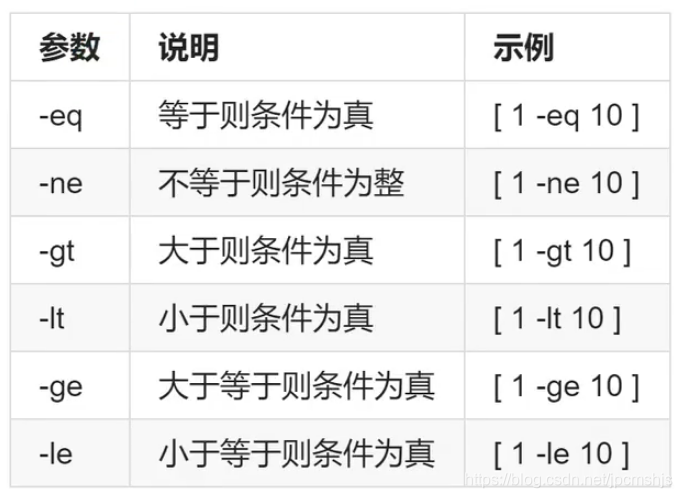
if整数比对
编写一个脚本,检测服务是否运行
#!/bin/bash
if [ $# -ne 1 ];then
echo "请输入一个服务名称"
exit
fi
systemctl status $1 &>/dev/null
rc=$?
if [ $rc -eq 0 ];then
echo "$1 服务正在运行"
else
echo "$1 服务没在运行"
fi
if字符串比较

if通配符[[ ]]
#!/bin/bash
read -p "请输入用户前缀" qz
if [[ ! $qz =~ ^[a-Z]+$ ]];then
echo "你输入的不是english"
exit
fi
read -p "请输入创建用户的后缀" hz
if [[ $hz =~ ^[0-9]+$ ]];then
user=${qz}${hz}
id $user &>/dev/null
if [ $? -eq 0 ];then
echo "用户名已存在 $user"
else
useradd $user
echo "用户创建成功 ${user}"
fi
else
echo "输入的不是数字"
fi
判断用户是否为root
if [ $UID -eq 0 ] && [ $USER == "root" ]
使用root用户清空/var/log/messages日志,并每次执行保留最近100行
#!/bin/bash
file=/var/log/messages
file_bak=/var/log/messages.bak
if [ $UID -eq 0 ] && [ $USER == "root" ];then
if [ -f $file ];then
tail -100 $file > $file_bak
cat $file_bak > $file
echo "==========备份成功============="
else
echo "文件不存在"
fi
fi
cat -n 查看文件并带有行号 文件名
awk ‘/.* Active/’- - -表示匹配行内包括“Active”的一行
awk ‘/.* Active/ {print $2}’- - - 表示打印第二个整体
{print $(NF)} - - - 打印最后一个整体
{print $(NF-1)} - - - 打印倒数第二个整体
安装netstat命令 - - - yum install net-tools
#1.判断服务是否存在#3.判断进程是否存在
ssh_status=$(systemctl status sshd|awk '/.*Active/ {print $2}')
if [ "$ssh_status" == "active" ];then
sleep 1
echo "服务检测的是 $ssh_status"
else
sleep 1
echo "服务检测的是 $ssh_status"
fi
#2.判断端口是否存在
netstat -lntp|grep "sshd" &>/dev/null
if [ $? -eq 0 ];then
sleep 1
echo "sshd服务端口存活"
else
sleep 1
echo "sshd服务端口不存活"
fi
#3.判断进程是否存在
ps axu |grep sshd|grep -v grep|grep -v "pts" &>/dev/null
if [ $? -eq 0 ];then
sleep 1
echo "sshd服务进程存在"
else
sleep 1
fi
查看版本信息
cat /etc/redhat-release
#!/bin/bash
version=$(cat /etc/redhat-release | awk '{print $(NF-1)}')
echo $version
if [ ${version%%.*} -eq "6" ];then
echo " ${version%%*.}"
else
echo " ${version%%.*}"
fi
if多分支
匹配1234
#!/bin/bash
read -p "请输入1-4 " install
if [[ ! $install =~ ^[1-4]$ ]];then
echo "请按规定输入"
exit
fi
if [ $install -eq 1 ];then
echo "1"
elif [ $install -eq 2 ];then
echo "2"
elif [ $install -eq 3 ];then
echo "3"
elif [ $install -eq 4 ];then
echo "4"
fi
脚本中使用action
#! /bin/bash
source /etc/init.d/functions
# 引入函数
action "服务" /bin/true
action "服务" /bin/false
执行效果

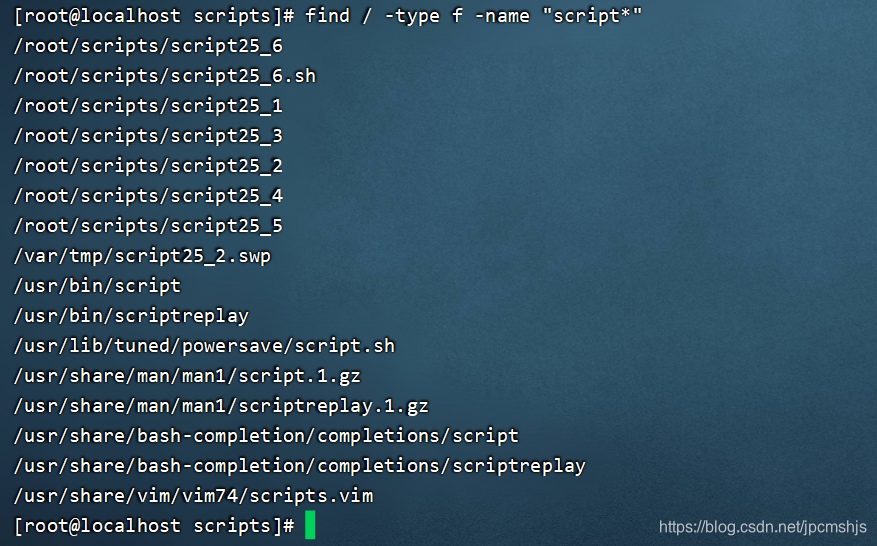
寻找文件
find / -type f -name “script*” - - - 在根目录下寻找文件名前缀为script的文件
执行效果
case用法
#!/bin/bash
source /etc/init.d/functions
#加锁
if [ -f /tmp/nginx.lock ];then
echo "此脚本正在执行,请稍后......"
exit
fi
touch /tmp/nginx.lock
rc=$1
case rc in
start)
if [ -f /var/run/nginx.pid ];then
action "nginx服务已经启动......" /bin/false
exit
else
/usr/sbin/nginx
if [ $? -eq 0 ];then
action "nginx服务启动成功......" /bin/true
fi
fi
;;
stop)
if [ -f /var/run/nginx.pid ];then
/usr/sbin/nginx -s stop
if [ $? -eq 0 ];then
action "nginx服务关闭成功......" /bin/true
else
action "nginx服务关闭失败......" /bin/false
fi
else
action "nginx服务未开启,不能进行关闭操作......" /bin/false
exit
fi
;;
reload)
if [ -f /var/run/nginx.pid ];then
/usr/sbin/nginx -s reload
if [ $? -eq 0 ];then
action "nginx服务重启成功......" /bin/true
else
action "nginx服务重启失败......" /bin/false
fi
else
action "nginx服务未开启,不能进行重启操作......" /bin/false
exit
fi
;;
esac
#解锁
rm -f /tep/nginx.lock
for循环
基本格式
for 变量 in 列表
do
使用变量
done
列表的分隔方式

使用for循环探测局域网中设备
#!/bin/bash
> /tmp/ip.log
#清空ip.log中的内容
for i in {1..254}
do
{
ip=192.168.1.$i
ping -c 1 -W 1 $ip &>/dev/null
if [ $? -eq 0 ];then
echo "$ip is ok"
echo "$ip is ok" >>/tmp/ip.log
else
echo "$ip is down"
fi
} &
#异步for循环
done
wait
echo "Scan IP is Done"
echo "--------------------------"
sed -n “行数p” - - - 文件名 取出文件中特定行内容
sed 行数d - - -删除指定的行内容
使用for循环实现数据库备份
#!/bin/bash
#获得数据库名称
db_name=$(mysql -uroot -p123456 -e "show databases;"|sed 1d |grep -v ".*_schema")
for i in $db_name
do
#创建数据库备份目录
DB_Path=/mysql_dump/$i
#如果目录不存在就创建
if [ ! -d ${DB_Path} ];then
mkdir -p ${DB_Path}
fi
#备份数据库
mysqldump -uroot -p219717 --single-transaction -B $i >${DB_Path}/${i}_database_$(date +%F).sql
echo "${i} 数据库 已经备份完成......"
done
使用for循环备份库和表
#!/bin/bash
#source /etc/init.d/functions
#获得数据库名称
db_name=$(mysql -uroot -p123456 -e "show databases;"|sed 1d |grep -v ".*_schema")
for i in $db_name
do
#创建数据库备份目录
DB_Path=/mysql_dump/$i
#如果目录不存在就创建
if [ ! -d ${DB_Path} ];then
mkdir -p ${DB_Path}
fi
#备份数据库
mysqldump -uroot -p219717 --single-transaction -B $i >${DB_Path}/${i}_database_$(date +%F).sql
#action "${i} 数据库 已经备份完成......" /bin/true
echo "${i} 数据库 已经备份完成................................................................."
#备份数据库中的表
table_name=$(mysql -uroot -p123456 -e "use ${i};show tables;"|sed 1d)
for j in $table_name
do
mysqldump -uroot -p123456 --single-transaction $i $j >${DB_Path}/${i}_${j}_table_$(date +%F).sql
echo "${i} 数据库 ${j} 数据表 已经备份完成......"
done
done
while循环

while读入文件方式
while read line - - - line->变量名 默认 按行取值
do
echo $line
done<文件名
函数
定义函数


调用函数
使用函数名直接调用
函数的传参
使用$进行传参
函数的返回值
return状态码(1-255)
数组
普通数组
声明:info=(linux age name)
取值:${数组名[索引号]}
关联数组
声明:declare -A 数组名
例:declare -A info
info=([name]=xxx [age]=18 [skill]=code)
取值:${info[age]}
取所有值: ${info[@]}或者 ${info[*]}
取所有索引: ${!info[@]}或者 ${!info[*]}
取数组长度: ${#info[@]}
#!/bin/bash
declare -A info_sex
while read line
do
type=$(echo ${line}|awk '{print $2}')
let info_sex[$type]++
done<sex.txt
for i in ${!info_sex[@]}
do
echo "索引名称为:${i} 索引对应的次数为 ${info_sex[$i]}"
done
使用while循环查找自定义用户
#!/bin/bash
i=0
while read line
do
User_id=$(echo $line|awk -F ":" '{print $3}')
User_Shell=$(echo $line|awk -F ":" '{print $NF}')
if [ $User_id -ge 1000 -a $User_Shell == "/bin/bash" ];then
let i++
fi
done</etc/passwd
echo "一共有$i个自定义用户"
正则表达式
过滤筛选作用
\ 转义符
^ 匹配字符串的开始
$ 匹配字符串的结尾
^$ 表示空行
. 匹配除换行符外的任意单个字符
[ ] 匹配包含在[字符]之中的任意一个字符
[^] 匹配[ ^] 之外的任意一个字符
? 匹配之前的项一次或零次
+ 匹配之前的项一次或多次
* 匹配之前的项零次或多次 .* 表示匹配所有
() 匹配表达式,创建一个用于匹配的字串
| 匹配两边的任意一项
{n} 匹配之前的项n次,n是可以为0的正整数
{n,} 匹配之前的项,至少匹配n次
{n,m} 匹配之前的项至少n次,最多m次
特定字符
[0-9]
[a-z]
[A-Z]
[a-Z]
sed文本处理
sed [options] ’ conmand’ file
选项
-n - - - 取消默认的输出,不写则完全输入加上本要输出的内容
-i - - - 将修改后的内容保存到文件
-r - - - 扩展正则,可以对/不进行转义
sed 命令参数
a 在当前行后添加一行或多行
sed -i ‘30a xxx’ passwd - - - 追加xxx在passwd文件的第30行
c 在当前行进行替换修改
sed -i ‘1c xxx’ test - - - 将test文件的第一行内容替换为xxx
sed -i ‘/^.inet./c yyy’ test - - -将正则匹配到的内容替换为yyy
d 在当前行进行删除操作
sed -i ‘3d’ test - - -删除 test文件中的第3行
sed -i ‘11,$d’ test - - - 删除第11行到最后一行
sed -i ‘$d’ test - - - 删除最后一行
sed -i /正则表达式/ test - - - 删除匹配的内容
i 在当前行之前插入文本
p 打印匹配的行或指定行
sed -n ‘/halt/p’ passwd - - - -打印匹配的行
sed -n ‘2p’ test - - - 打印第二行内容
sed -n ‘$p’ test - - - 打印最后一行
sed匹配替换 不改变文本内容
替换命令s 标志g行内全局替换i忽略大小写
sed ‘s/inet/alice/’ test.txt - - - 替换每行出现的第一个inet
sed ‘s/^ *inet/alice…/’ test.txt - - - 替换正则匹配的内容
sed ‘s/inet/alice…/g’ test.txt - - - 匹配包含有inet的行进行替换(行内全部)
sed ‘s#aa#TTT#g’ test.txt - - - 匹配每行的aa换成TTT
sed ‘s#aa#TTT#gi’ test.txt - - - 匹配每行的aa忽略大小写换成TTT
sed ‘s#/etc/test/123#/dev/null#g’ 1.txt - - - 匹配到/etc/test/123,替换为/dev/null,/不用转义
#!/ 都可用
awk
- awk将文件中的每一行作为输入,并将每一行赋给变量$0,以换行符结束
- awk开始进行字段分解,每个字符存储在已编号的变量中,从$1开始,默认空格分隔
- awk默认字段分隔符是由内部FS变量来确定,可以使用-F修订
- awk行处理时使用了print函数打印分割后的字段
- awk在打印后的字段加上空格,因为$1,$3之间有一个逗号
- awk输出之后,将从文件中获取另一行,并将其存储在$0中,覆盖原来的内容
[root@localhost ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
[root@localhost ~]# awk 'BEGIN {print 1/2} {print "ok"} END {print "over"}' /etc/hosts
0.5
ok
ok
over
awk ‘BEGIN {print 1/2} {print “ok”} END {print “over”}’ /etc/hosts
BEGIN {print 1/2} - - -行处理前
{print “ok”} - - - 进行行处理 ,,,文本中有两行,所以打印两次ok
END {print “over”} - - - 行处理后
awk -F: ‘{print $1}’ /etc/passwd 以冒号为分隔符,打印每一行的第一个元素
awk ‘BEGIN{FS=":"} /root/{print $1}’ /etc/passwd 以冒号分隔,将匹配到root的行第一个元素打印
awk ‘$10 ~ 404 {code[$10]++}’ file - - - 匹配行第十个元素为404,将元素放入数组
awk -F “[: ]” ‘{print $2}’ file - - - 将冒号和空格都作为分隔符
awk -F “[: ]+” ‘{print $2}’ file - - -将冒号空格,一个/连续多个冒号,一个/连续多个空格都视为分隔符
awk ‘{print NF}’ file - - - 打印最后一个元素的位置
awk ‘{print $NF}’ file - - - 打印最后一个元素的内容
awk ‘{print $(NF-1)}’ file - - - 打印最后一个元素前面的内容
awk ‘{print NR}’ file - - - 打印行号
awk ‘NR==3{print $0}’ file - - - 打印第三行内容
awk ‘NR!=3{print $0}’ file - - - 打印除第三行外的内容
FNR - - - 处理多个文件,行号单独排序
awk判断语句
awk -F: ‘{ if(判断条件) {成功执行} else { 不成功执行} END {行处理完成后执行}}’ 文件

















 4943
4943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









