







1、页面解析
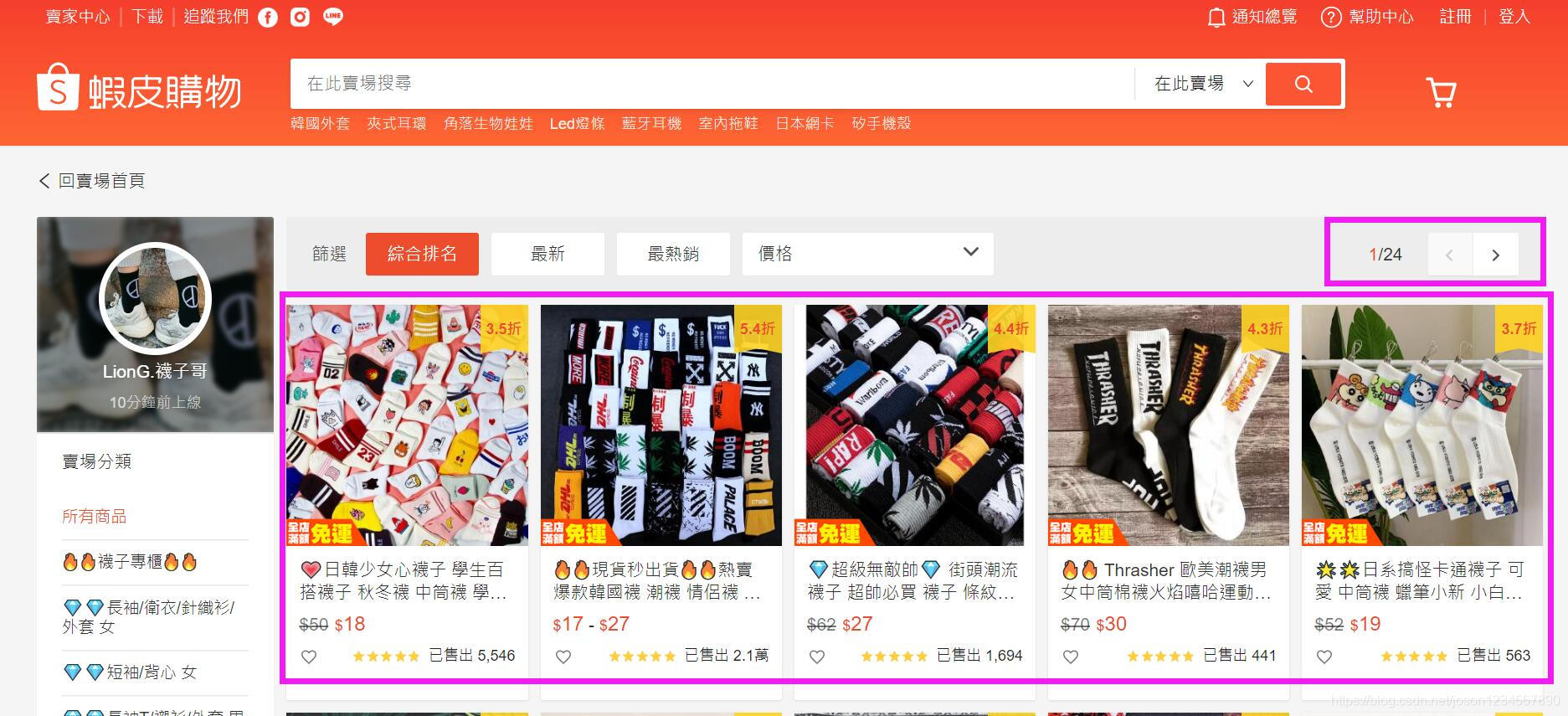
主要获取每一行单品数据信息,以及翻页的页码
观察URL组成:
https://xiapi.xiapibuy.com/api/v2/search_items/?
GET参数:
by=pop&limit=30&match_id=178302698&newest=120&order=desc&page_type=shop&version=2
参数解释:
match_id:每个店铺对应的店铺id
limit:每一页显示商品数
newest:辅助参数,当前所在页乘以每页商品数得出
2、抓包请求调试
抓包观察数据,优先观察header和cookie
抓包看到cookie参数过多,没有办法一一解析,尝试不添加任何cookie进行二次请求
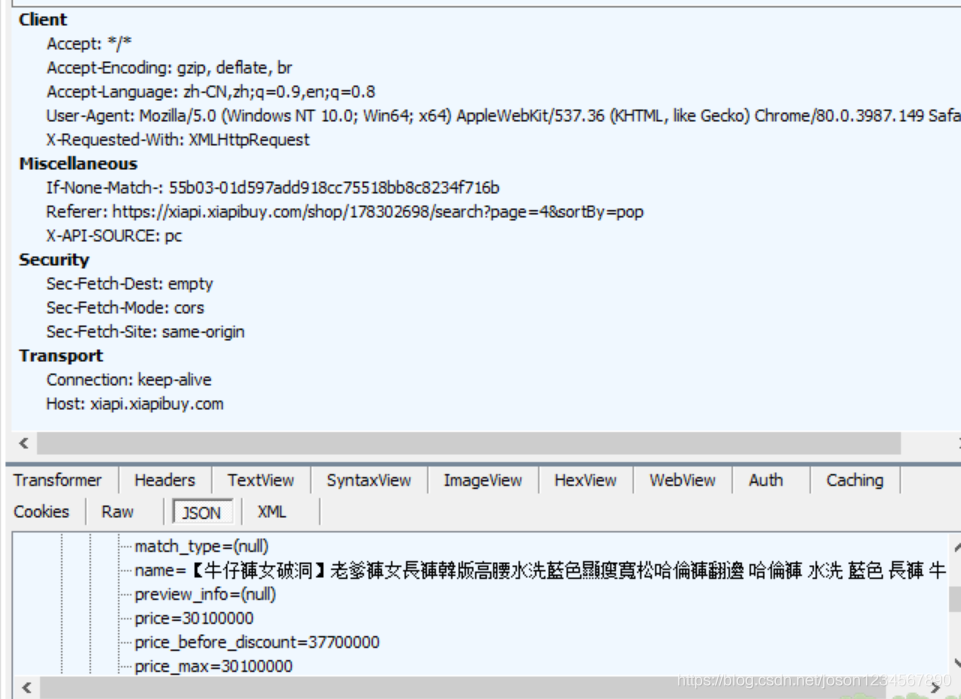
上述图是没有添加任何cookie的请求记录,可以看到数据是正常返回,所以cookie的参数可以暂时不用考虑。
观察headers,发现 If-None-Match 属于动态参数,每次翻页都动态生成,服务器主要是通过该参数与第一次请求的参数做匹配,如果是一致则直接返回缓存数据给到前端,我是搜索资料简单理解的,如有错误,请指正。
If-None-Match 既然是属于动态参数,优先考虑的是删除后是否可以正常访问,所以需要尝试第三次请求测试做进一步观察
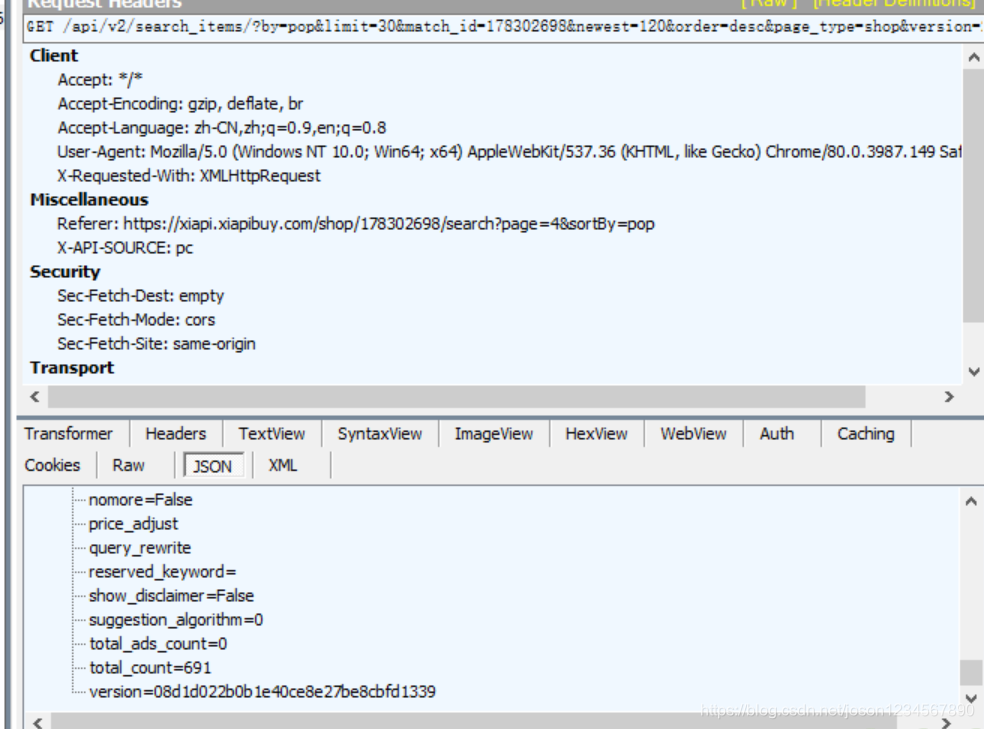
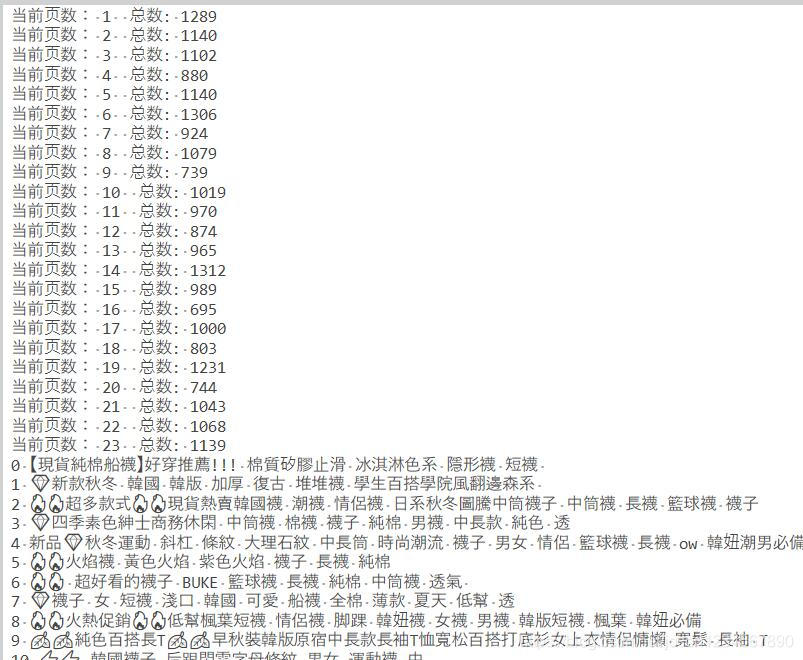 通过多次观察得出,就算不添加 If-None-Match 数据也是可以正常返回的,不过存在异常,一些关键字段会返回NULL,以及 Total_count 的数据每次都会不同。
通过多次观察得出,就算不添加 If-None-Match 数据也是可以正常返回的,不过存在异常,一些关键字段会返回NULL,以及 Total_count 的数据每次都会不同。
返回的Response是一个json格式,里面的total_count参数代表全店的商品数,在后面需要直接判断需要翻页的页数,属于关键参数,必须准确获取到。
3、JS代码断点调试
最常见也是最简单粗暴的方法是直接搜索参数名称,对全站文件检索,看下参数是怎样动态形成的。
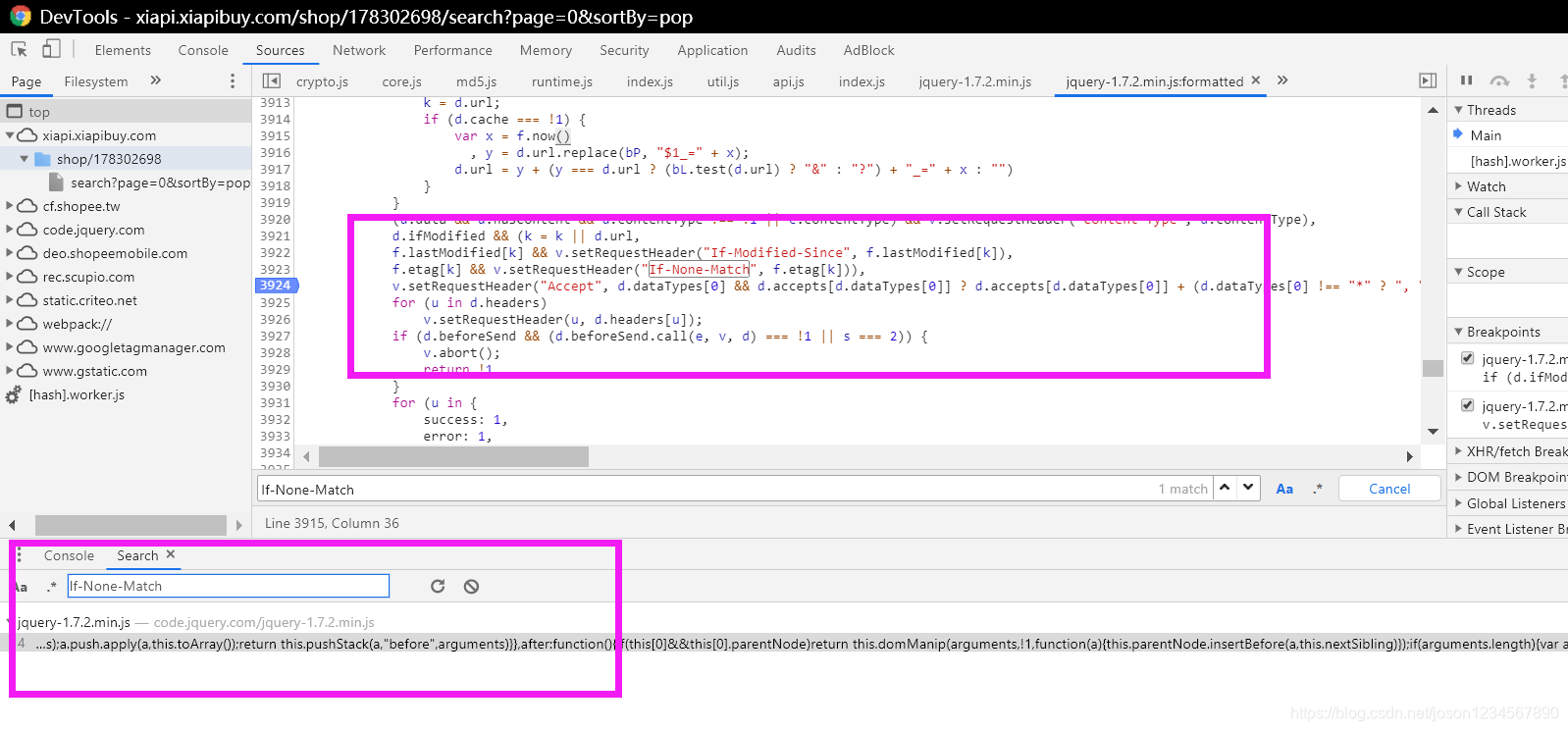
观察上图,直接搜索参数名称 If-None-Match 只有一个返回结果,显示在jquery-1.7.2.min.js文件中出现了这个关键字,其中的代码是一个历遍对比匹配的功能,并没有涉及到参数的生成,而且这个js文件不是网站的静态资源,是通过https://code.jquery.com 站点直接引用过来的,不是网站自己的东西,就没有修改权,所以可以判断,这个文件对我们没有实际帮助意义直接忽略!
既然直接搜索参数名称,没有作用,尝试第二种方式
在GET请求的时候设定断点,单步调试观察。
前面说过URL的组成部分 https://xiapi.xiapibuy.com/api/v2/search_items/,其中涵盖后缀 search_items 关键字,尝试搜索关键字看封装的请求函数里面是有所发现。
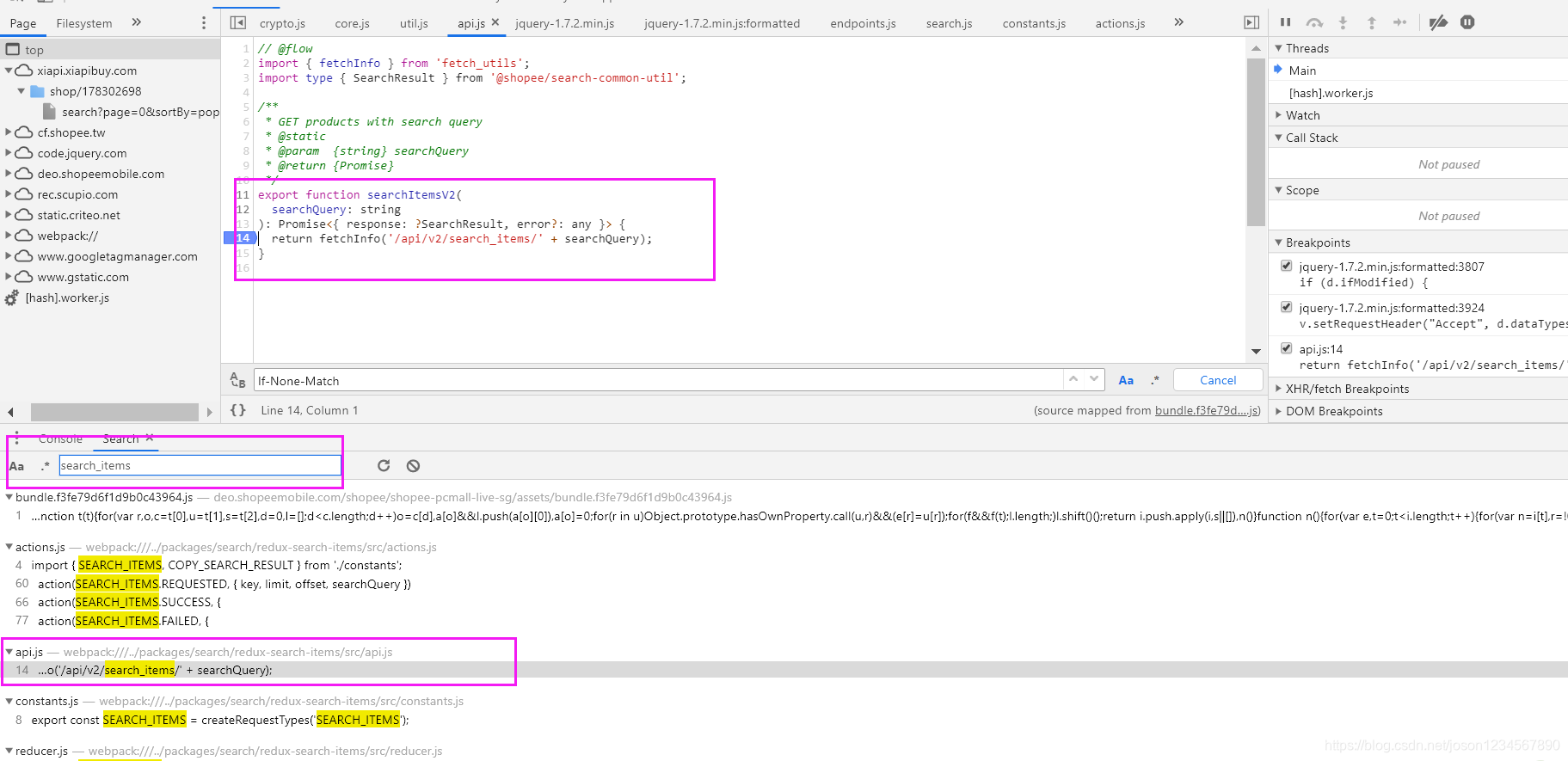
搜索等到的结果很多,仔细对比后,一个名为api.js的文件成功引起了我的注意。
就是一个请求返回的封装,对该函数设定断点,然后进行单步调试观察。
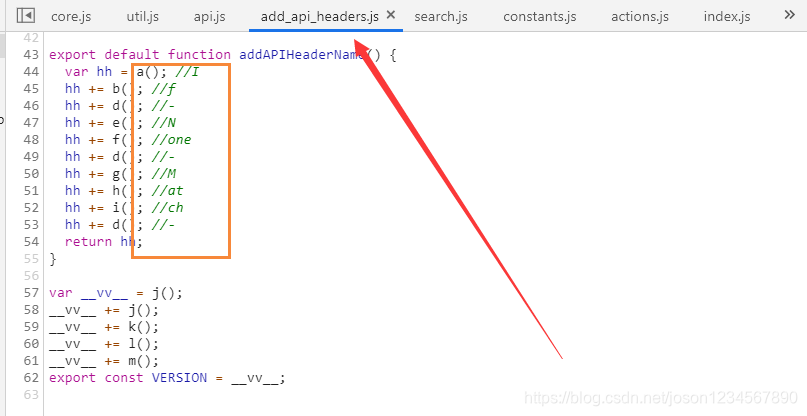
多次对比发现,找到关键所在,add_api_headers.js 文件成功找到了该headers关键字的组成,它是把关键字拆分开单个字母单词,然后进行拼接,也是一开始搜索的时候并没有发现它的关键原因。
继续进行单步调试,距离目标值不远了。。。。
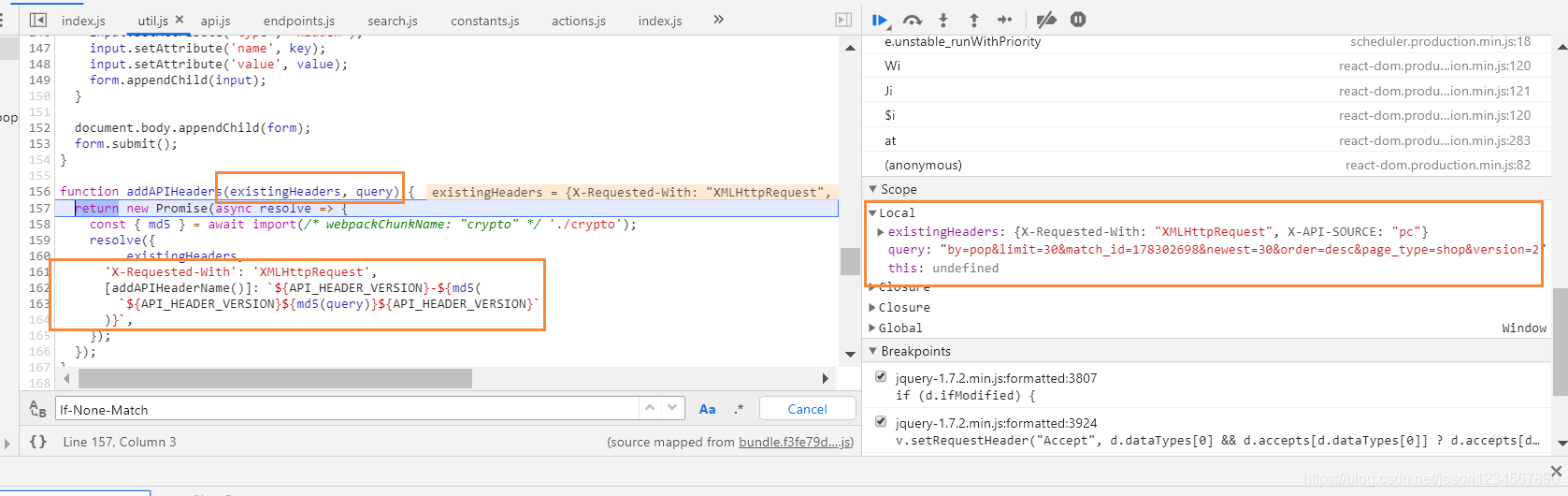
功夫不负有心人,多次断点调试观察后终于发现目标所在,代码可以直接看出参数的构成:
API_HEADER_VERSION + md5(query) +API_HEADER_VERSION
API_HEADER_VERSION是固定值,55b03
query 就是我们请求的URL组成的后半部分,然后字符串进行md5的加密处理。
# Python 字符串 MD5 加密
def md5_convert(string):
m = hashlib.md5()
m.update(string.encode())
return m.hexdigest()
所有请求参数已经具备,正式开始撸码吧!
4、Python请求代码
def spider(self):
result = dict()
url = 'https://xiapi.xiapibuy.com/api/v2/search_items/?'
s = requests.session()
page = 0
while True:
query = 'by=pop&limit=30&match_id={}&newest={}&order=desc&page_type=shop&version=2'.format(
self.MATCH_ID, page * 30)
query_md5 = md5_convert(query)
If_None_Match = self.API_HEADER_VERSION + query_md5 + self.API_HEADER_VERSION
If_None_Match = self.API_HEADER_VERSION + '-' + md5_convert(If_None_Match)
try:
response = requests.get(url + query, headers=headers)
items = response.json()['items']
if items:
print('当前页数:', page + 1, ' 总数:', response.json()['total_count'])
while items:
item = items.pop()
result[str(item['itemid'])] = {
'name': item['name'],
'price': item['price']
}
else:
break
except Exception as err:
print(err)
break
page += 1

5、总结
在很多实际操作中,可能并没有那么顺利,当然,文章简短,当中的过程很多也是已经被简化,一开始由于没抓准关键点,在断点调试中费了不少时间,学海无涯,与大家一起共勉吧。上述总结两点,多点耐心,擦亮眼睛。


















 728
728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











