






 提出一种新的级联卷积神经网络架构,能够在较少的人工注释下进行物体检测任务的学习。该方法通过两阶段和三阶段级联网络结构,利用图像级别的标签和对象建议来训练模型。
提出一种新的级联卷积神经网络架构,能够在较少的人工注释下进行物体检测任务的学习。该方法通过两阶段和三阶段级联网络结构,利用图像级别的标签和对象建议来训练模型。
TITLE: Weakly Supervised Cascaded Convolutional Networks
AUTHOR: Ali Diba, Vivek Sharma, Ali Pazandeh, Hamed Pirsiavash, Luc Van Gool
ASSOCIATION: KU Leuven, Sharif Tech., UMBC, ETH Zürich
FROM: arXiv:1611.08258
CONTRIBUTIONS
A new architecture of cascaded networks is proposed to learn a convolutional neural network handling the task without
expensive human annotations.
METHOD
This work trains a CNN to detect objects using image level annotaion, which tells what are in one image. At training stage, the input of the network are 1) original image, 2) image level labels and 3) object proposals. At inference stage, the image level labels are excluded. The object proposals can be generated by any method, such as Selective Search and EdgeBox. Two differenct cascaded network structures are proposed.
Two-stage Cascade
The two-stage cascade network structure is illustrated in the following figure.
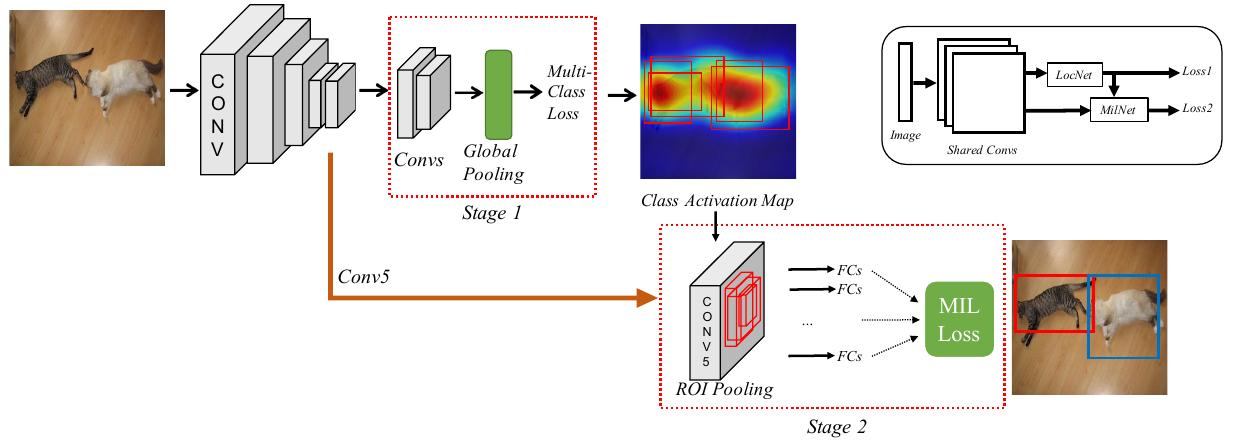
The first stage is a location network, which is a fully-convolutional CNN with a global average pooling or global maximum pooling. In order to learn multiple classes for single image, an independent loss function for each class is used. The class activation maps are used to select candidate boxes.
The second stage is multiple instance learning network. Given a bag for instances
xc={xj|j=1,...,n}
and a label set
yc={yi|yi∈{0,1},i=1,..,C}
, where each
x
is one of the condidate boxes,
Im my understanding, only the boxes with the most confidence in each category will be punished if they are wrong. Besides, the equations in the paper have some mistakes.
Three-stage Cascade
The three-stage cascade network structure adds a weak segmentation network between the two stages in the two-stage cascade network. It is illustrated in the following figure.
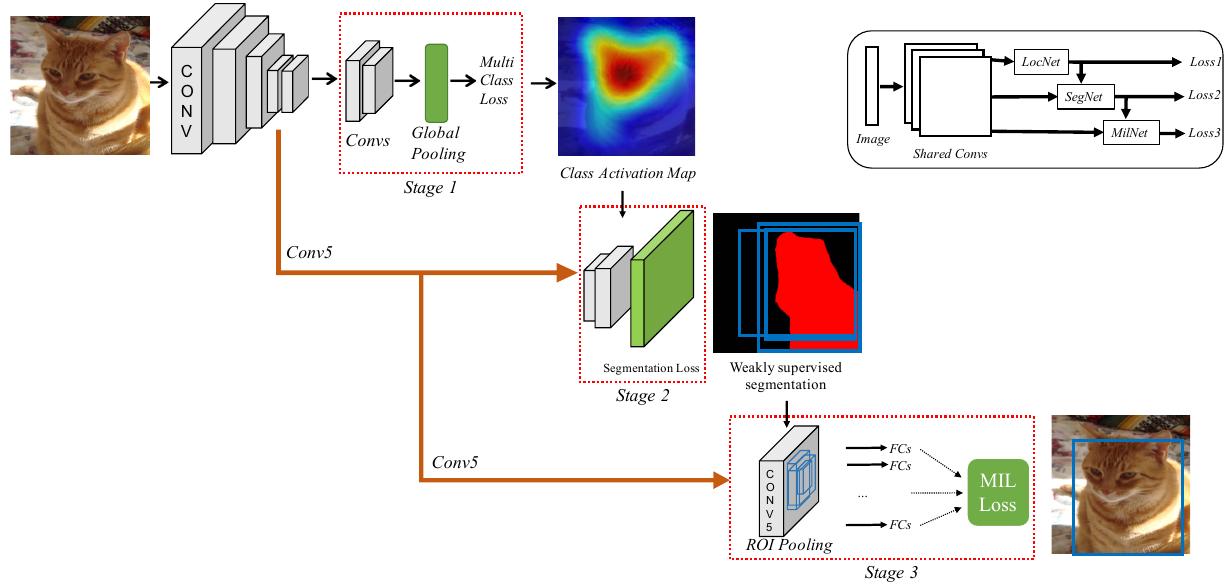
The weak segmentation network uses the results of the first stage as supervision signal.
sic
is defined as the CNN score for pixel
i
and class
Considering
y
as the label set for image
where Gi is the supervision map for the segmentation from the first stage.
SOME IDEAS
This work requires little annotation. The only annotation is the image level label. However, this kind of training still needs complete annotation. For example, we want to detect 20 categories, then we need a 20-d vector to annotate the image. What if we only know 10/20 categories’ status in one image?

















 2240
2240


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








