




 线程池是为解决频繁创建和销毁线程带来的资源浪费问题而引入的,它包含核心线程数、最大线程数、空闲线程存活时间等关键参数。Executors提供多种静态方法创建线程池,如newFixedThreadPool。ThreadPoolExecutor允许更细粒度的配置,包括线程工厂和拒绝策略。文章还提到了阿里巴巴的Java规范建议直接使用ThreadPoolExecutor创建线程池,以防止高并发下的资源过度消耗。
线程池是为解决频繁创建和销毁线程带来的资源浪费问题而引入的,它包含核心线程数、最大线程数、空闲线程存活时间等关键参数。Executors提供多种静态方法创建线程池,如newFixedThreadPool。ThreadPoolExecutor允许更细粒度的配置,包括线程工厂和拒绝策略。文章还提到了阿里巴巴的Java规范建议直接使用ThreadPoolExecutor创建线程池,以防止高并发下的资源过度消耗。
文章目录
6. 线程池
6.1 概念
线程的创建开销是很大的,如果在一个复杂的系统中,频繁的创建线程,销毁线程,回造成很大的资源浪费,更多的时间花费。所以为了解决这个问题,就引入了线程池。可以简单理解 线程池是一个容器,里面有很多已经创建的空闲线程,当有需要的时候,从这个容器中随机取出一个线程,执行完成之后,再次将线程扔回线程池,等待下一次的调用。这样避免了因为频繁创建,销毁导致的资源浪费问题。
6.2 创建线程池
线程池的创建大体上分两类:
- 通过 Executors 类
- 通过 ThreadPoolExecutor类创建
下面我们分别介绍一下如何使用两种方式创建线程池
6.2.1 Executors
使用 Executors 的静态方法就可以创建出ExecutorService对象,然后调用execute()/submit(),方法即可运行线程。
通过 ide 的代码提醒我们可以看到 Executors 支持以下几个静态方法创建ExecutorService对象:
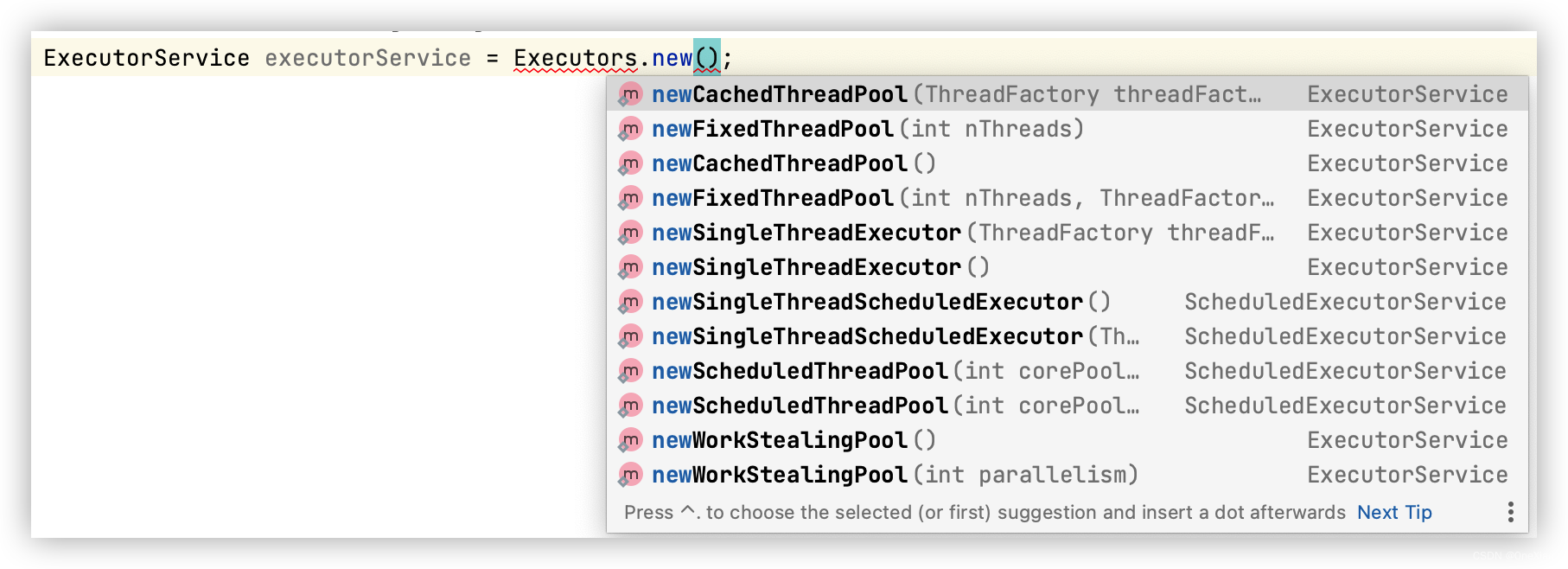
这里分别介绍几个方法
- newCacheThreadPool: 创建一个缓存线程池,当线程池中没有线程可用时候,创建新的线程,如果线程执行完成,且已经过期,则删除线程
- newFixedThreadPool:创建一个指定固定数量的线程池
- newSingleThreadExecutor:创建一个单个线程的线程池
- newSingleThreadScheduleExecutor:创建一个单个可以延迟执行线程的线程池。
- newScheduleThreadPool: 创建一个具有指定数量的延迟执行线程的线程池。
- newWorkStealingPool:创建一个抢占执行的线程池。
这里我们先简单了解一下创建的几种线程池。后续会根据参数不同逐一讲解。
根据上面他可以看到创建出来的都是ExecutorService,ExecutorService有两个方法 : execute()/submit(),分别介绍一下:
- execute() : 用于执行没有返回 的方法
- submit(): 可以执行没有返回,也可以执行有返回的方法
在前面我们介绍了 Runnable 是没有返回值的,Callable 是有返回值的,但是通过代码我们可以看到 submit 竟然可以提交 Runnable,这里的返回值,其实就是 Runnable 运行的状态。run 方法运行完成后返回 null。
6.2.2 ThreadPoolExecutor
上面介绍了Executors方式创建线程池,接下来我们说一下ThreadPoolExecutor,在说ThreadPoolExecutor之前,我们先看一下Executors的实现的部分源码

我们看到newFixedThreadPool 是基于 ThreadPoolExecutor 实现线程池的,从上述代码可以看到,只需要通过new ThreadPoolExecutor 对象的方式即可创建线程池。
我们看 一下ThreadPoolExecutor 类的构造方法,最少是五个,最多是七个
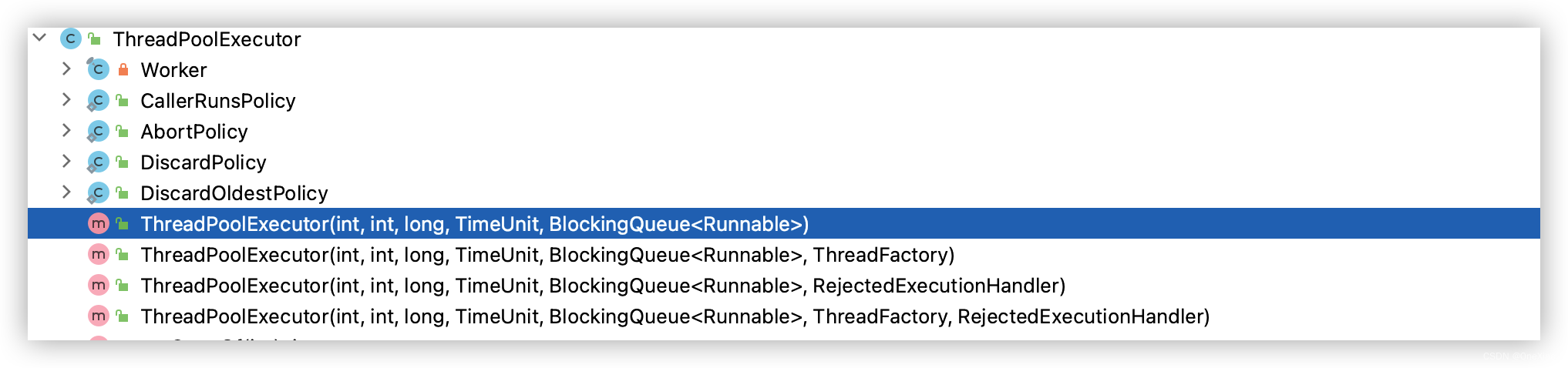
这里我们直接看最多参数的构造器,因为其他最终还是通过这个构造器创建的。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
从上面的代码可以看到七个参数分别为
- corePoolSize 核心线程数
- maximumPoolSize 最大线程数
- keepAliveTime 空闲线程等待工作的超时时间
- TimeUnit 时间单位
- BlockingQueue 阻塞队列
- ThreadFactory 线程工厂
- RejectedExecutionHandler 拒绝策略
当然还有一个重要的参数是 allowCoreThreadTimeOut,这个参数是用来控制核心线程池策略的,默认为 false 表示核心线程始终保持活跃,true 表示核心线程在 keepAliveTime作为超时等待
下面逐一讲解每个参数的作用
6.2.2.1 corePoolSize
核心线程数,核心线程就是始终活跃的线程,当任务提交之后,如果当前的线程数没有超过核心线程,则会创建线程运行任务,核心线程是不会因为是空闲状态终止被销毁。除非设置了allowCoreThreadTimeOut参数。
6.2.2.2 maximumPoolSize
最大线程数,从文本是就可以看出指的是当前线程池内最大容纳的线程数。
6.2.2.3 keepAliveTime
等待工作的空闲线程超时,当超过了核心线程数,或者设置了allowCoreThreadTimeOut,线程使用这个超时,其他情况下进入等待。这里的超时单位是纳秒(nanos)。抽象点说 线程执行完任务,回到池子里面,这时候核心线程池内因为有别人捷足先登/或者标记核心线程可以销毁,进而发现自己是多余的那个,那么就会在这个超时之后销毁。
6.2.2.4 TimeUnit
用来指定空闲线程的时间单位。keepAliveTimeOut 的单位。
6.2.2.5 BlockingQueue
新任务提交之后,会进入对应的队列。任务调度器会从该队列中取出任务,然后去执行,JDK 默认给了四种队列
-
ArrayBlockingQueue
基于数组的有界队列,当线程数超过核心线程数时,新提交的任务就会进入此队列,如果队列已满,则创建新线程。当线程数超过最大线程数时,则执行拒绝策略
-
LinkedBlockingQuene
基于链表的无界序列,和上面队列一样,不过因为序列是无界的,所以会一直往队列里面添加任务,此处的链表默认的 size 是 int 最大值。
-
SynchronousQuene
无缓存的队列,每一个插入队列的任务都需要等待前一个任务取出,否则进入等待。
-
PriorityBlockingQueue
具有优先级的阻塞队列,优先级通过Comparator指定
6.2.2.6 ThreadFactory、
线程工厂,可以通过线程工厂指定线程名,以及其他线程属性
6.2.2.7 RejectedExecutionHandler
拒绝策略,当线程池内的任务队列满了,已经超出最大线程数了,这时候新提交的任务就会进入拒绝策略。JDK 提供了四种,因为代码都很少,直接贴出源码,然后逐一分析。
首先四个类都是实现了RejectedExecutionHandler接口,这个接口只有一个方法,定义如下:
public interface RejectedExecutionHandler {
/**
* Method that may be invoked by a {@link ThreadPoolExecutor} when
* {@link ThreadPoolExecutor#execute execute} cannot accept a
* task. This may occur when no more threads or queue slots are
* available because their bounds would be exceeded, or upon
* shutdown of the Executor.
*
* <p>In the absence of other alternatives, the method may throw
* an unchecked {@link RejectedExecutionException}, which will be
* propagated to the caller of {@code execute}.
*
* @param r the runnable task requested to be executed
* @param executor the executor attempting to execute this task
* @throws RejectedExecutionException if there is no remedy
*/
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
根据注释我们知道,这个方法就是拒绝的实现。
-
AbortPolicy
public static class AbortPolicy implements RejectedExecutionHandler { public AbortPolicy() { } public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { throw new RejectedExecutionException("Task " + r.toString() + " rejected from " + e.toString()); } }这个看上去就很简单了,拒绝策略就是抛出异常
-
DiscardPolicy
public static class DiscardPolicy implements RejectedExecutionHandler { public DiscardPolicy() { } public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { } }这个更简单啥也不干
-
CallerRunsPolicy
public static class CallerRunsPolicy implements RejectedExecutionHandler { public CallerRunsPolicy() { } public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { if (!e.isShutdown()) { r.run(); } } }这个有点意思,如果线程池还活着,直接执行Runnable 的 run 方法,好家伙直接不启线程直接干了
-
DiscardOldestPolicy
public static class DiscardOldestPolicy implements RejectedExecutionHandler { public DiscardOldestPolicy() { } public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { if (!e.isShutdown()) { e.getQueue().poll(); e.execute(r); } } }这个就更绝了,从类名也看出来了,忽略最早的任务,然后将当前任务加入执行队列。
6.3 拓展
在阿里巴巴的 Java 规范中明确指出了,建议使用 ThreadPoolExecutor 方式去创建现场池,而在ThreadPoolExecutor源码我们可以看到下面的注释:
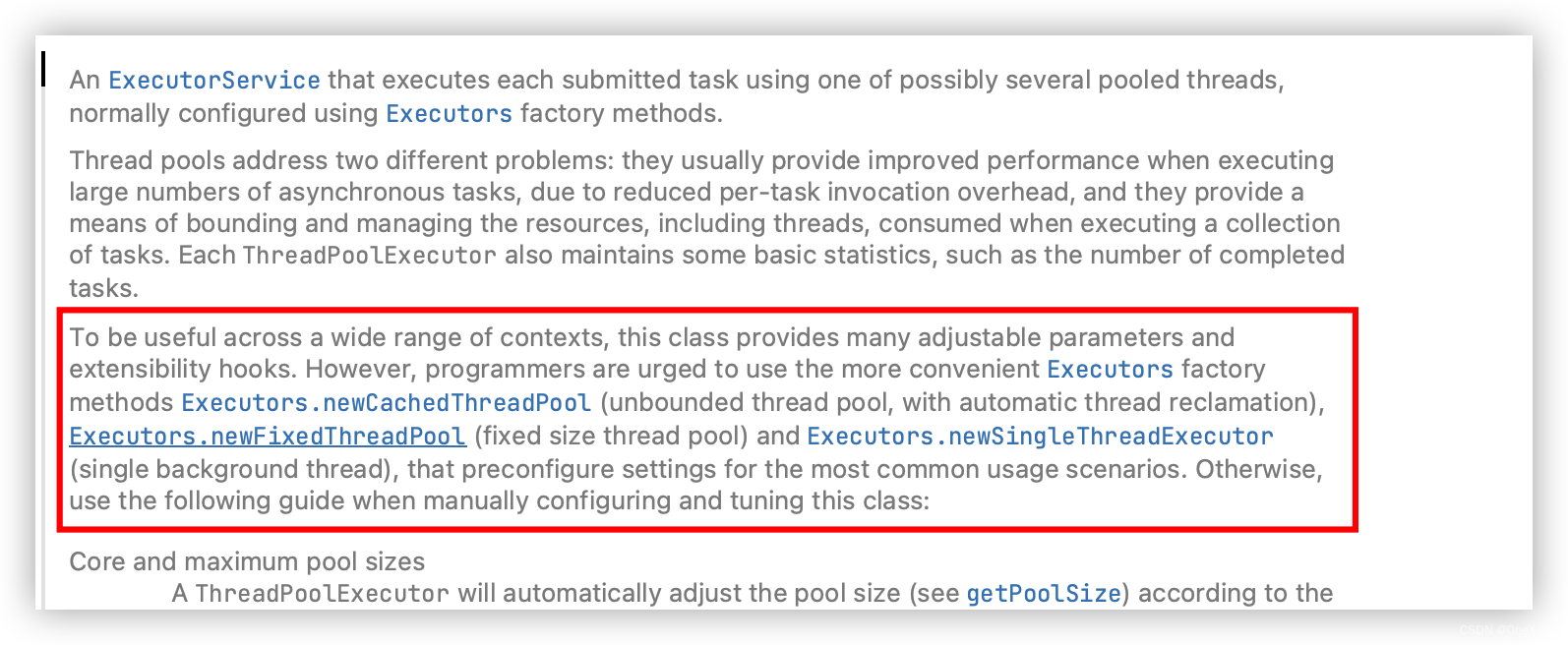
注释中支出建议程序员使用 Executors 这个类的静态方法创建线程池,因为 JDK 认为这些已经够用了。阿里巴巴的规范之所以不建议使用是因为高并发场景下,如果使用这些无界队列,可能存在创建超过线程,导致 OOM。
所以在高并发场景,我们尽量去规范线程池的使用,因为这样也方便我们了解线程池的原理。
当然作为 Android 开发,高并发的场景很少,所以我们直接使用 JDK 推荐的用法就可以啦,但是各个参数和线程池的原理也要掌握哦!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











