




 本文介绍了深度学习模型压缩和稀疏化的最新工作,包括彩票假设、动态修剪和生长策略。重点讨论了《Rigging the Lottery》、《In-Time Over-Parameterization》和《Scheduled Grow-and-Prune》等方法,这些方法在训练过程中实现端到端的稀疏化。此外,还提到了针对BERT的Task-Agnostic Mask Training和Movement Pruning等技术,它们通过训练可调整的掩模和关注参数的运动来提高模型效率。
本文介绍了深度学习模型压缩和稀疏化的最新工作,包括彩票假设、动态修剪和生长策略。重点讨论了《Rigging the Lottery》、《In-Time Over-Parameterization》和《Scheduled Grow-and-Prune》等方法,这些方法在训练过程中实现端到端的稀疏化。此外,还提到了针对BERT的Task-Agnostic Mask Training和Movement Pruning等技术,它们通过训练可调整的掩模和关注参数的运动来提高模型效率。
文章目录
- 前言
- 《THE LOTTERY TICKET HYPOTHESIS: FINDING SPARSE, TRAINABLE NEURAL NETWORKS》ICLR 19
- 《Rigging the Lottery: Making All Tickets Winners》ICML 20
- 《Do We Actually Need Dense Over-Parameterization? In-Time Over-Parameterization in Sparse Training》ICML 21
- 《EFFECTIVE MODEL SPARSIFICATION BY SCHEDULED GROW-AND-PRUNE METHODS》ICLR 2022
- 《Learning to Win Lottery Tickets in BERT Transfer via Task-agnostic Mask Training》 NAACL 2022
- 《How fine can fine-tuning be? Learning efficient language models》AISTATS 2020
- 《Movement Pruning: Adaptive Sparsity by Fine-Tuning》 NIPS20
- 《SNIP: SINGLE-SHOT NETWORK PRUNING BASED ON CONNECTION SENSITIVITY》 ICLR19
- 《PROSPECT PRUNING: FINDING TRAINABLE WEIGHTS AT INITIALIZATION USING META-GRADIENTS》 ICLR 22
- 《DiSparse: Disentangled Sparsification for Multitask Model Compression》CVPR 22
- 《Cross-stitch Networks for Multi-task Learning》 CVPR 16
前言
ICLR 2019 best paper《THE LOTTERY TICKET HYPOTHESIS: FINDING SPARSE, TRAINABLE NEURAL NETWORKS》提出了彩票假设(lottery ticket hypothesis):“dense, randomly-initialized, feed-forward networks contain subnetworks (winning tickets) that—when trained in isolationreach test accuracy comparable to the original network in a similar number of iterations.”
而笔者在[文献阅读] Sparsity in Deep Learning: Pruning and growth for efficient inference and training in NN也(稀烂地)记录了这方面的工作。
本文打算进一步简述这方面最新的工作。另外,按照“when to sparsify”,这方面工作可被分为:Sparsify after training、Sparsify during training、Sparse training,而笔者更为关注后两者(因为是end2end的),所以本文(可能)会更加关注这两个子类别的工作。
《THE LOTTERY TICKET HYPOTHESIS: FINDING SPARSE, TRAINABLE NEURAL NETWORKS》ICLR 19

步骤:
- 初始化完全连接的神经网络θ,并确定裁剪率p
- 训练一定步数,得到θ1
- 从θ1中根据参数权重的数量级大小,裁剪掉p的数量级小的权重,并将剩下的权重重置成原来的初始化权重
- 继续训练
代码:
- tf:https://github.com/google-research/lottery-ticket-hypothesis
- pt:https://github.com/rahulvigneswaran/Lottery-Ticket-Hypothesis-in-Pytorch
《Rigging the Lottery: Making All Tickets Winners》ICML 20

步骤:
- 初始化神经网络,并预先进行裁剪。预先裁剪的方式考虑:
- uniform:每一层的稀疏率相同;
- 其它方式:层中参数越多,稀疏程度越高,使得不同层剩下的参数量总体均衡;
- 在训练过程中,每ΔT步,更新稀疏参数的分布。考虑drop和grow两种更新操作:
- drop:裁剪掉一定比例的数量级小的权重
- grow:从被裁剪的权重中,恢复相同比例梯度数量级大的权重
- drop\grow比例的变化策略:
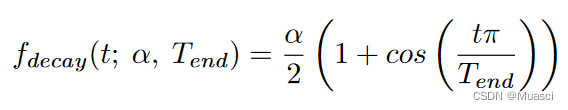
其中,α是初始的更新比例,一般设为0.3。
特点:
- 端到端
- 支持grow
代码:
- tf:https://github.com/google-re
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1499
1499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









