







文章目录
前言
笔者尝试复现LaSS工作,由于该工作所做的第一步就是训练一个多语言机器翻译模型,故记录在此,本文主要内容是数据准备的步骤。
数据准备
实验使用iwslt 14中的8个以英语为中心的语言对,完成16个方向的多语言机器翻译。目前使用该数据集是因为其数据量相对较小,模型训练速度较快,笔者觉得比较适合用于机器翻译上手、比较不同模型性能的优劣。数据集的统计信息如下图所示:
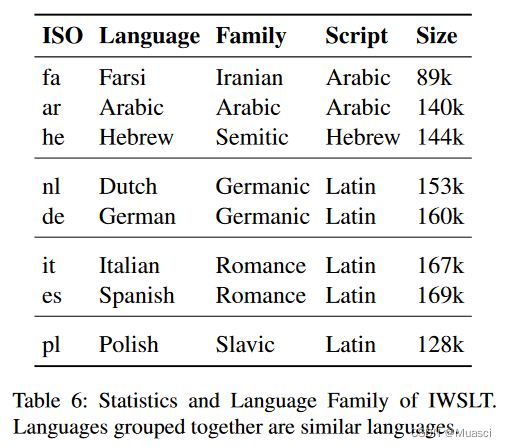
下面介绍数据的下载和预处理。假设现在的所在目录为/data/syxu/data/data_store/iwslt14
数据下载
从https://wit3.fbk.eu/2014-01链接中下载得到2014-01.tgz文件夹,保存至当前目录,tar zxvf 2014-01.tgz进行文件解压缩。2014-01中的内容如下:
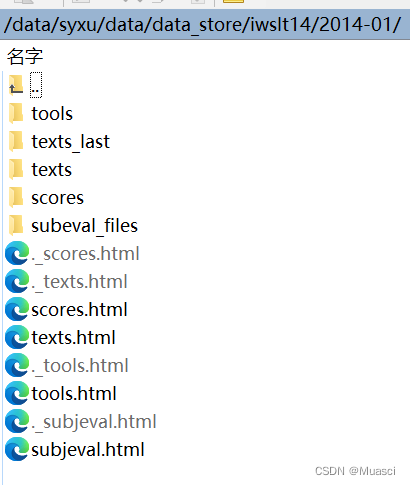
使用cp -r 2014-01/texts/*/en/*-en.tgz .将需要使用到的压缩文件提取到当前目录,得到:
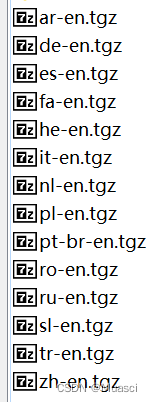
数据预处理(iwslt14_preprocess_subwordnmt_old_version)
bash prepare-iwslt14.sh
数据预处理部分的脚本代码参照LaSS和multilingual-kd-pytorch。
具体来说,首先在当前目录下创建预处理脚本文件:prepare-iwslt14.sh和preprocess_multilingual.py,这两个文件各自的代码如下:
- prepare-iwslt14.sh
#!/usr/bin/env bash
#
# Adapted from https://github.com/facebookresearch/MIXER/blob/master/prepareData.sh
echo 'Cloning Moses github repository (for tokenization scripts)...'
git clone https://github.com/moses-smt/mosesdecoder.git
echo 'Cloning Subword NMT repository (for BPE pre-processing)...'
git clone https://github.com/rsennrich/subword-nmt.git
SCRIPTS=mosesdecoder/scripts
TOKENIZER=$SCRIPTS/tokenizer/tokenizer.perl
LC=$SCRIPTS/tokenizer/lowercase.perl
CLEAN=$SCRIPTS/training/clean-corpus-n.perl
BPEROOT=subword-nmt
BPE_TOKENS=30000
prep=iwslt14.tokenized
tmp=$prep/tmp
orig=orig
rm -r $orig
rm -r $tmp
rm -r $prep
mkdir -p $orig $tmp $prep
for src in ar de es fa he it nl pl; do
tgt=en
lang=$src-en
echo "pre-processing train data..."
for l in $src $tgt; do
if [[ ! -f $src-en.tgz ]]; then
wget https://wit3.fbk.eu/archive/2014-01//texts/$src/en/$src-en.tgz
fi
cd $orig
tar zxvf ../$src-en.tgz
cd ..
f=train.tags.$lang.$l
tok=train.tags.$lang.tok.$l
cat $orig/$lang/$f | \
grep -v '<url>' | \
grep -v '<talkid>' | \
grep -v '<keywords>' | \
sed -e 's/<title>//g' | \
sed -e 's/<\/title>//g' | \
sed -e 's/<description>//g' | \
sed -e 's/<\/description>//g' | \
perl $TOKENIZER -threads 8 -l $l > $tmp/$tok
echo ""
done
perl $CLEAN -ratio 1.5 $tmp/train.tags.$lang.tok $src $tgt $tmp/train.tags.$lang.clean 1 175
for l in $src $tgt; do
perl $LC < $tmp/train.tags.$lang.clean.$l > $tmp/train.tags.$lang.$l
done
echo "pre-processing valid/test data..."
for l in $src $tgt; do
for o in `ls $orig/$lang/IWSLT14.TED*.$l.xml`; do
fname=${o##*/}
f=$tmp/${fname%.*}
echo $o $f
grep '<seg id' $o | \
sed -e 's/<seg id="[0-9]*">\s*//g' | \
sed -e 's/\s*<\/seg>\s*//g' | \
sed -e "s/\’/\'/g" | \
perl $TOKENIZER -threads 8 -l $l | \
perl $LC > $f
echo ""
done
done
echo "creating train, valid, test..."
for l in $src $tgt; do
awk '{if (NR%23 == 0) print $0; }' $tmp/train.tags.$src-$tgt.$l > $tmp/valid.en-$src.$l
awk '{if (NR%23 != 0) print $0; }' $tmp/train.tags.$src-$tgt.$l > $tmp/train.en-$src.$l
cat $tmp/IWSLT14.TED.dev2010.$src-$tgt.$l \
$tmp/IWSLT14.TEDX.dev2012.$src-$tgt.$l \
$tmp/IWSLT14.TED.tst2010.$src-$tgt.$l \
$tmp/IWSLT14.TED.tst2011.$src-$tgt.$l \
$tmp/IWSLT14.TED.tst2012.$src-$tgt.$l \
> $tmp/test.en-$src.$l
done
TRAIN=$tmp/train.all
BPE_CODE=$prep/code
rm -f $TRAIN
for l in $src $tgt; do
cat $tmp/train.en-$src.$l >> $TRAIN
done
done
echo "learn_bpe.py on ${TRAIN}..."
python $BPEROOT/learn_bpe.py -s $BPE_TOKENS < $TRAIN > $BPE_CODE
for src in ar de es fa he it nl pl; do
for L in $src $tgt; do
for f in train.en-$src.$L valid.en-$src.$L test.en-$src.$L; do
echo "apply_bpe.py to ${f}..."
python $BPEROOT/apply_bpe.py -c $BPE_CODE < $tmp/$f > $prep/$f
done
done
done
rm -r text
mkdir -p text/train_data
mkdir -p text/valid_data
mkdir -p text/test_data
cp iwslt14.tokenized/train.en-* text/train_data/
cp iwslt14.tokenized/valid.en-* text/valid_data/
cp iwslt14.tokenized/test.en-* text/test_data/
cd ..
python iwslt14/preprocess_multilingual.py --pref=iwslt14/ --joined-dictionary
- preprocess_multilingual.py
#!/usr/bin/env python3
# Copyright (c) 2017-present, Facebook, Inc.
# All rights reserved.
#
# This source code is licensed under the license found in the LICENSE file in
# the root directory of this source tree. An additional grant of patent rights
# can be found in the PATENTS file in the same directory.
"""
Data pre-processing: build vocabularies and binarize training data.
"""
import argparse
import glob
import json
import random
from collections import Counter
from itertools import zip_longest
import os
import shutil
from fairseq.data import indexed_dataset, dictionary
from fairseq.tokenizer import Tokenizer, tokenize_line
from multiprocessing import Pool, Manager, Process
def get_parser():
parser = argparse.ArgumentParser()
parser.add_argument('--pref', metavar='FP', default=None, help='data prefix')
parser.add_argument('--no-dict', action='store_true', help='do not build dictionary')
parser.add_argument('--nwordssrc', metavar='N', default=65536, type=int, help='number of target words to retain')
parser.add_argument('--padding-factor', metavar='N', default=8, type=int,
help='Pad dictionary size to be multiple of N')
parser.add_argument('--joined-dictionary', action='store_true', help='Generate joined dictionary for en-xx')
parser.add_argument('--expert', default='', type=str)
parser.add_argument('--workers', metavar='N', default=4, type=int, help='number of parallel workers')
# parser.add_argument('--workers', metavar='N', default=os.cpu_count(), type=int, help='number of parallel workers')
return parser
def main(args):
print(args)
random.seed(1)
destdir = os.path.join(args.pref, 'data-bin' + ('' if args.expert == '' else '/' + args.expert))
os.makedirs(destdir, exist_ok=True)
dict_path = os.path.join(destdir, 'dict.txt')
textdir = os.path.join(args.pref, 'text')
train_dir = os.path.join(textdir, 'train_data')
test_dir = os.path.join(textdir, 'test_data')
valid_dir = os.path.join(textdir, 'valid_data')
# if args.expert != '':
# train_files = glob.glob('{}/train.{}-en.*.e'.format(train_dir, args.expert)) + \
# glob.glob('{}/train.en-{}.*.e'.format(train_dir, args.expert))
# pass
# else:
train_files = glob.glob('{}/train.*-*.*'.format(train_dir))
train_files = [f for f in train_files if len(f.split('.')) in [3, 5]]
test_files = glob.glob('{}/test.*-*.*'.format(test_dir))
test_files = [f for f in test_files if len(f.split('.')) in [3, 5]]
valid_files = glob.glob('{}/valid.*-*.*'.format(valid_dir))
valid_files = [f for f in valid_files if len(f.split('.')) in [3, 5]]
lng_pairs = set([f.split('/')[-1].split(".")[1] for f in (train_files + test_files + valid_files)])
print(train_files, test_files, valid_files, lng_pairs)
def build_dictionary(filenames):
d = dictionary.Dictionary()
for filename in filenames:
Tokenizer.add_file_to_dictionary(filename, d, tokenize_line, args.workers)
return d
tgt_dict_path = os.path.join(destdir, 'dict.tgt.txt')
if not args.no_dict:
if args.joined_dictionary:
src_dict = build_dictionary(train_files)
src_dict.finalize(
nwords=args.nwordssrc,
padding_factor=args.padding_factor
)
dict_path = os.path.join(destdir, 'dict.txt')
# create dict for every language
for lng_pair in lng_pairs:
src, tgt = lng_pair.split('-')
tmp_src_dict_path = os.path.join(destdir, f'dict.{src}.txt')
tmp_tgt_dict_path = os.path.join(destdir, f'dict.{tgt}.txt')
if not os.path.exists(tmp_src_dict_path):
src_dict.save(tmp_src_dict_path)
if not os.path.exists(tmp_tgt_dict_path):
src_dict.save(tmp_tgt_dict_path)
src_dict.save(dict_path)
print(src_dict)
else:
print("| build en dict.")
src_dict = build_dictionary([f for f in train_files if f.replace('.tok.bpe', '').endswith('.en')])
src_dict.finalize(
nwords=args.nwordssrc,
padding_factor=args.padding_factor
)
src_dict.save(dict_path)
print("| build xx dict.")
tgt_dict = build_dictionary([f for f in train_files if not f.replace('.tok.bpe', '').endswith('.en')])
tgt_dict.finalize(
nwords=args.nwordssrc,
padding_factor=args.padding_factor
)
tgt_dict.save(tgt_dict_path)
def make_binary_dataset(input_prefix, output_prefix, lng_pair, lang, num_workers):
if not args.joined_dictionary and lang != 'en':
dict = dictionary.Dictionary.load(tgt_dict_path)
else:
dict = dictionary.Dictionary.load(dict_path)
print('| [{}] Dictionary: {} types'.format(lang, len(dict) - 1))
n_seq_tok = [0, 0]
replaced = Counter()
def merge_result(worker_result):
replaced.update(worker_result['replaced'])
n_seq_tok[0] += worker_result['nseq']
n_seq_tok[1] += worker_result['ntok']
input_file = f'{input_prefix}.{lng_pair}.{lang}.tok.bpe'
if not os.path.exists(input_file):
input_file = f'{input_prefix}.{lng_pair}.{lang}'
if not os.path.exists(input_file):
print("| {} not found".format(input_file))
return
if args.expert:
input_file = input_file + '.e'
offsets = Tokenizer.find_offsets(input_file, num_workers)
pool = None
if num_workers > 1:
pool = Pool(processes=num_workers - 1)
for worker_id in range(1, num_workers):
fn_without_ext = f"{output_prefix}{worker_id}.{lng_pair}.{lang}"
pool.apply_async(binarize, (input_file, dict, fn_without_ext,
offsets[worker_id],
offsets[worker_id + 1]), callback=merge_result)
pool.close()
ds = indexed_dataset.IndexedDatasetBuilder(f"{output_prefix}.{lng_pair}.{lang}.bin")
merge_result(Tokenizer.binarize(input_file, dict, lambda t: ds.add_item(t),
offset=0, end=offsets[1]))
if num_workers > 1:
pool.join()
for worker_id in range(1, num_workers):
temp_file_path = f"{output_prefix}{worker_id}.{lng_pair}.{lang}"
ds.merge_file_(temp_file_path)
os.remove(indexed_dataset.data_file_path(temp_file_path))
os.remove(indexed_dataset.index_file_path(temp_file_path))
ds.finalize(f"{output_prefix}.{lng_pair}.{lang}.idx")
print('| [{}] {}: {} sents, {} tokens, {:.3}% replaced by {}'.format(
lang, input_file, n_seq_tok[0], n_seq_tok[1],
100 * sum(replaced.values()) / n_seq_tok[1], dict.unk_word))
def make_all(lng_pair, lang):
make_binary_dataset(
os.path.join(train_dir, 'train'),
os.path.join(destdir, 'train'),
lng_pair, lang, num_workers=args.workers)
make_binary_dataset(
os.path.join(test_dir, 'test'),
os.path.join(destdir, 'test'),
lng_pair, lang, num_workers=1)
make_binary_dataset(
os.path.join(valid_dir, 'valid'),
os.path.join(destdir, 'valid'),
lng_pair, lang, num_workers=1)
lngs = set()
for lng_pair in lng_pairs:
src_and_tgt = lng_pair.split('-')
if len(src_and_tgt) != 2:
continue
src, tgt = src_and_tgt
print("| building: ", src, tgt)
lngs.add(src)
lngs.add(tgt)
make_all(lng_pair, src)
make_all(lng_pair, tgt)
lngs = list(lngs)
lngs.sort()
json.dump(lngs, open(os.path.join(destdir, 'all_lngs.json'), 'w'))
def binarize(filename, dict, fn_without_ext, offset, end):
ds = indexed_dataset.IndexedDatasetBuilder(f"{fn_without_ext}.bin")
def consumer(tensor):
ds.add_item(tensor)
res = Tokenizer.binarize(filename, dict, consumer, offset=offset, end=end)
ds.finalize(f"{fn_without_ext}.idx")
return res
if __name__ == '__main__':
parser = get_parser()
args = parser.parse_args()
main(args)
上述代码的大致预处理流程为:
- 分词:
perl $TOKENIZER -threads 8 -l $l > $tmp/$tok - 清理:
perl $CLEAN -ratio 1.5 $tmp/train.tags.$lang.tok $src $tgt $tmp/train.tags.$lang.clean 1 175 - 小写化:
perl $LC < $tmp/train.tags.$lang.clean.$l > $tmp/train.tags.$lang.$l - 为测试数据进行同样的:分词、小写化
- 创建训练、验证、测试集
- 使用所有训练数据学习bpe:
python $BPEROOT/learn_bpe.py -s $BPE_TOKENS < $TRAIN > $BPE_CODE - 对所有文件进行bpe:
python $BPEROOT/apply_bpe.py -c $BPE_CODE < $tmp/$f > $prep/$f - 创建词典&二值化:
python iwslt14/preprocess_universal.py --pref=iwslt14/ --joined-dictionary
另外需要特别说明的是,preprocess_multilingual.py需要用到fairseq库, 而如果直接在当前环境pip install fairseq,得到最新版本是跑不了这些代码的。方法有二:1. pip install fairseq==0.6.1(没有尝试);2. git clone https://github.com/RayeRen/multilingual-kd-pytorch ; cp -r multilingual-kd-pytorch/fairseq .。
最终得到data-bin文件夹,用于模型的训练。
(关于以上预处理流程中涉及到的代码的大致解析,请见[机器翻译] 常见预处理代码解析)
模型训练
看LaSS。
补充
补充一:Key error while accessing batch_iterator.first_batch
如果遇到该错误,则是因为上面的preprocess_multilingual.py与你使用的fairseq版本不对应,可以尝试[机器翻译] multilingual fairseq-preprocess中的方法。
参考
https://github.com/NLP-Playground/LaSS
https://github.com/RayeRen/multilingual-kd-pytorch/blob/master/data/iwslt/raw/prepare-iwslt14.sh
https://blog.youkuaiyun.com/jokerxsy/article/details/125054739


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









