









单表查询
查询所有字段的所有行:
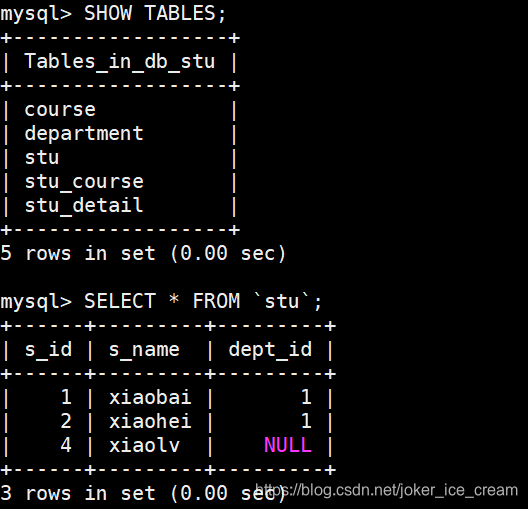
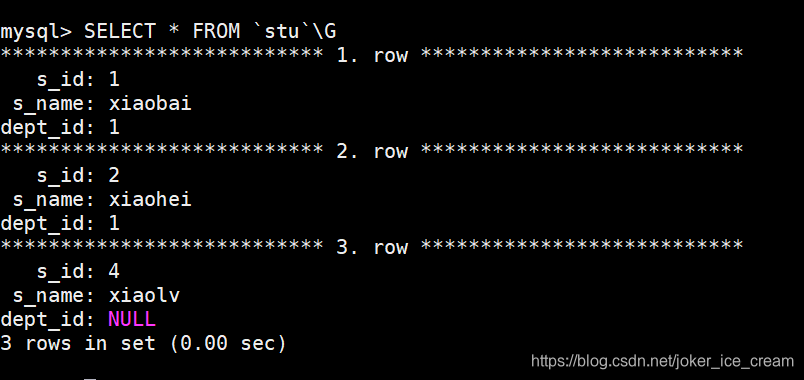
用 ’ \G ’ 代替 ‘ ; ’,表示格式化,数据量大的时候可以这样用,更清晰。
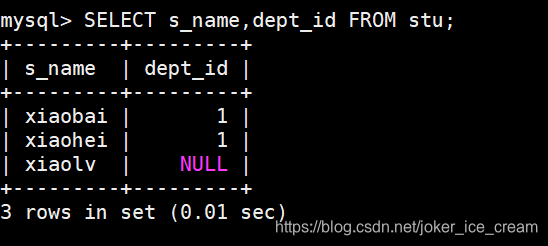
查询部分字段的所有行
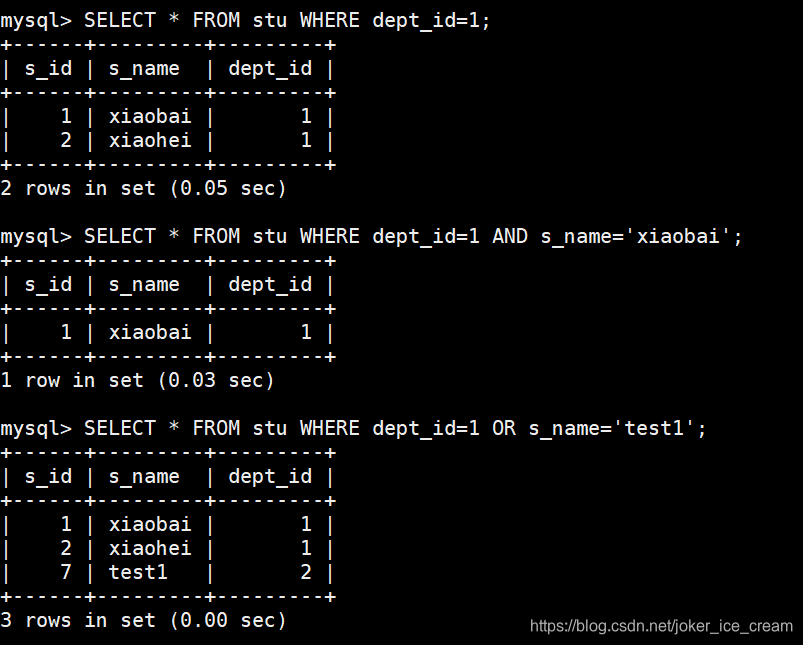
带条件查询,查询所有字段的部分行
条件查询
SELECT col_name FROM tb_name WHERE 条件
查询条件可以是大于等于不等于(>,=,<>)等等(模糊查询),也可以是更加复杂的判断都是可以的。
精确查询
AND 需要满足所有条件才会被查询出来;
OR 只需要满足其中一个条件即可被查询出来
模糊查询
% 是通配符,后面不限制字符个数,要想限制字符个数,用下划线替代%,一个下划线代表一个字符,两个下划线代表两个字符。
LIKE 是关键字
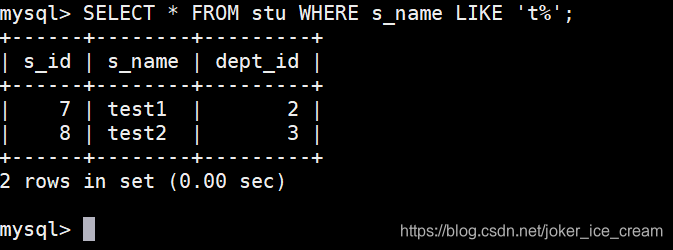
查询以 ’ t ’ 开头的数据。
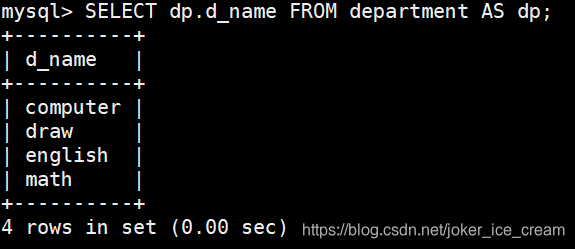
取别名
SELECT col_name AS new_name FROM tab_name AS new_name2
如果列名或者表名太长,可以给它们取一个别名,可以方便取使用
多表查询
内连接
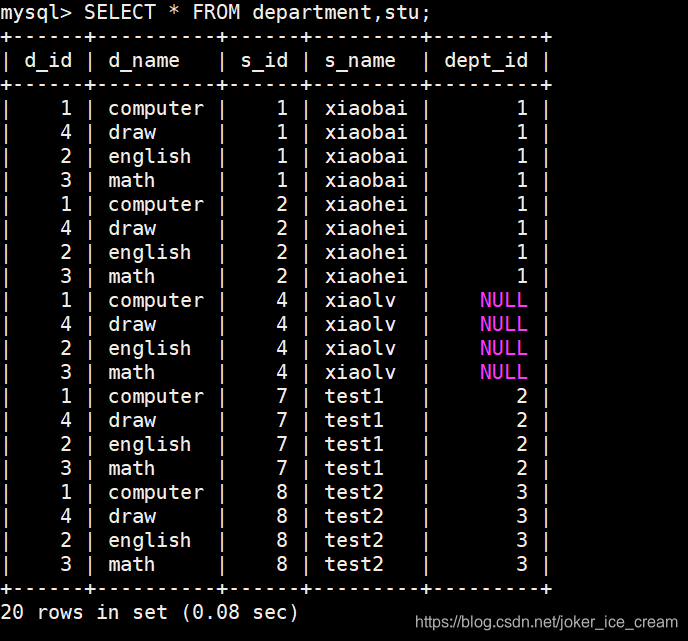
无条件连接,连接出来的称为笛卡尔集
第一种方式,逗号连接
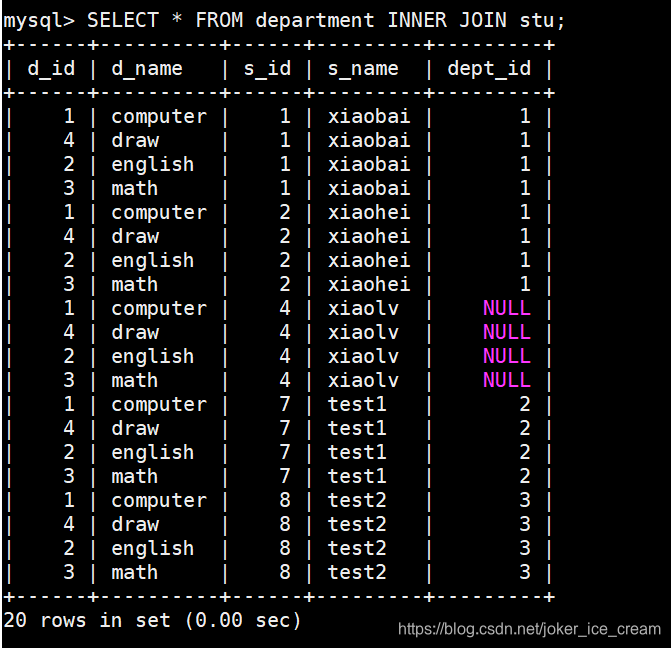
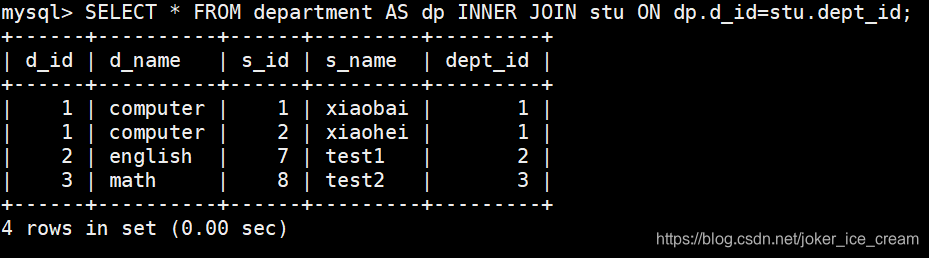
第二种方式,INNER JOIN连接
条件连接
逗号连接
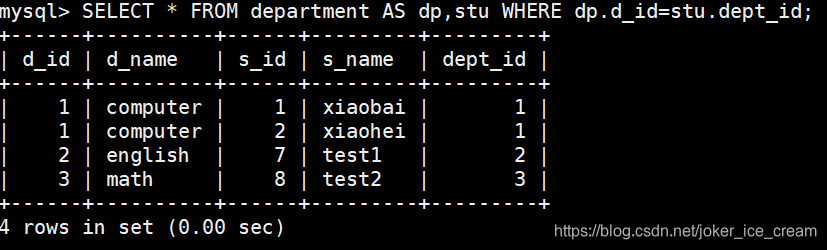
INNER JOIN 连接
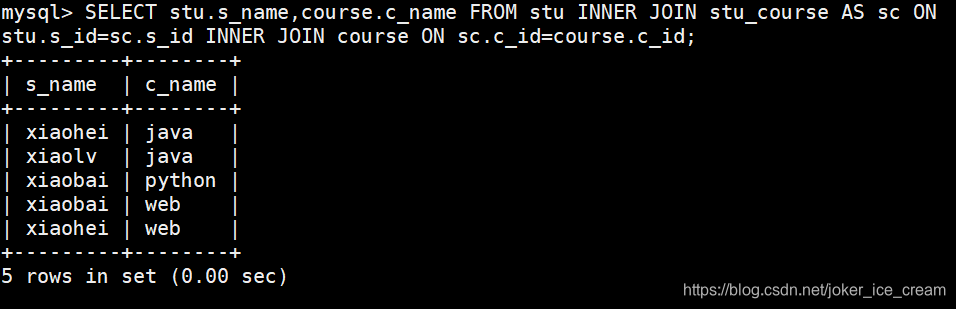
用INNER JOIN 可以连接n个表,下面演示连接三个表的方法:
先连接两个表:
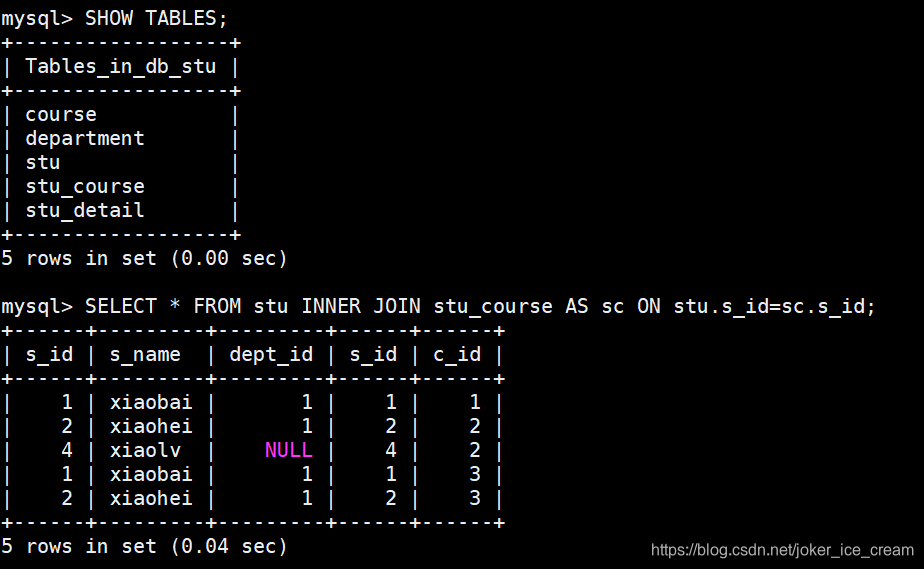
连接三个表:
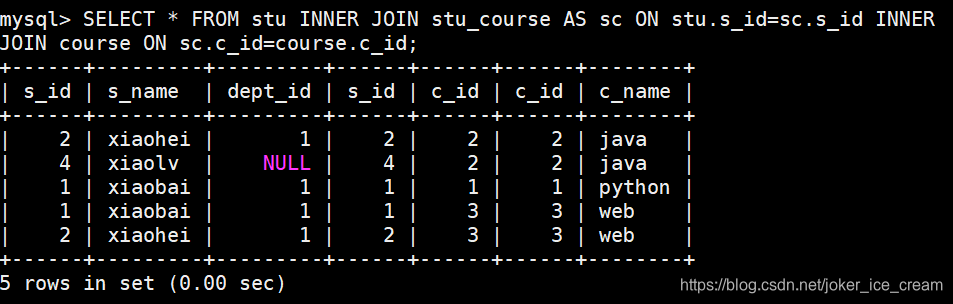
修改 * 来实现部分显示:
外连接
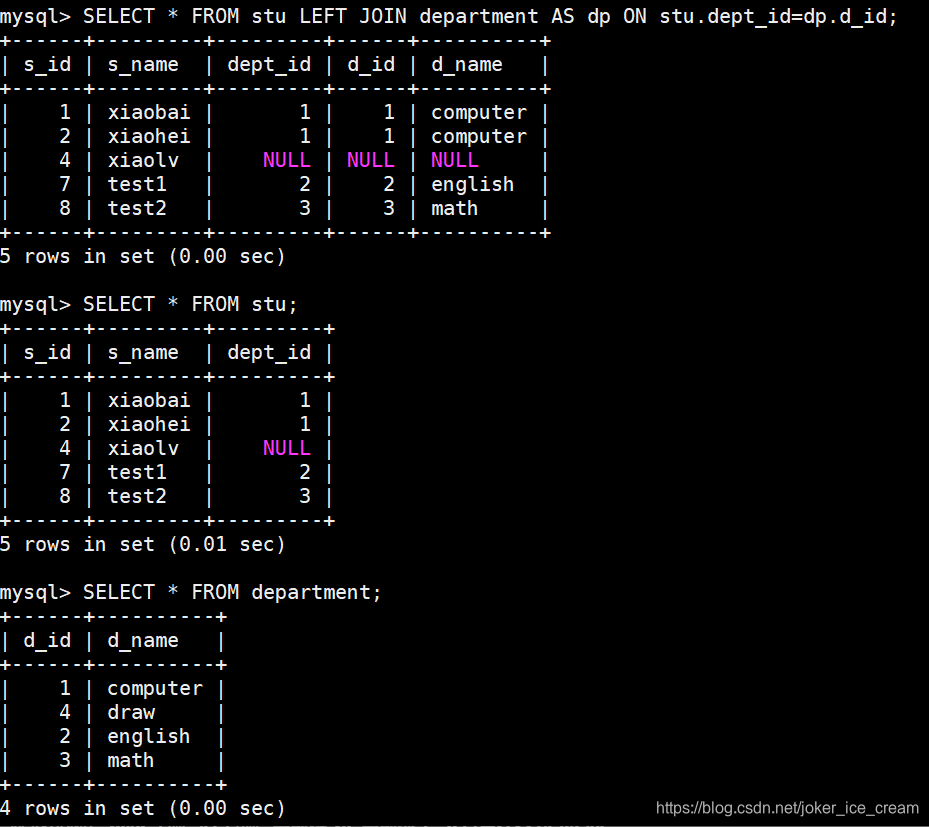
左连接
以左边的表为主,返回左表当中全部所有的数据,右表没有匹配到的会以NULL值补全
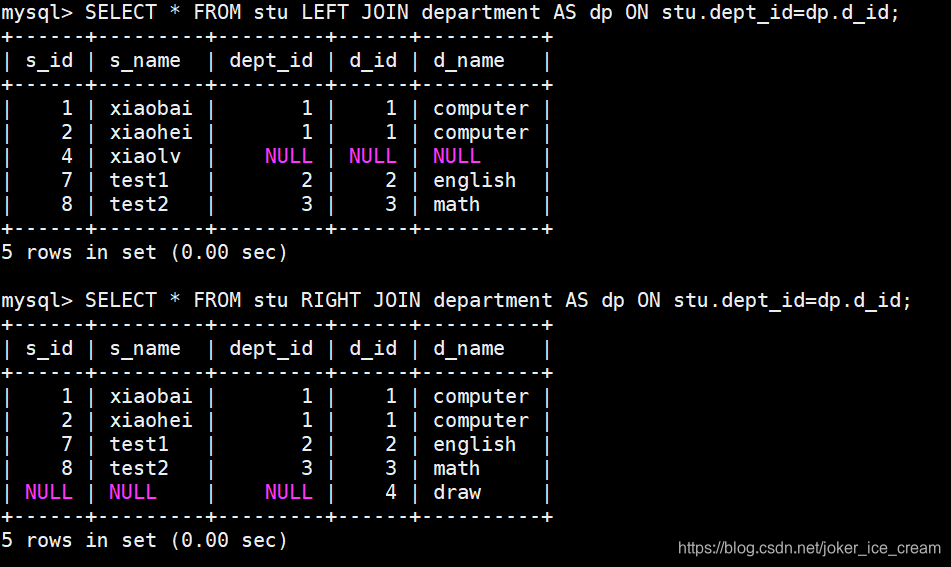
右连接
以右边的表为主,返回右表当中全部所有的数据,左表没有匹配到的会以NULL值补全

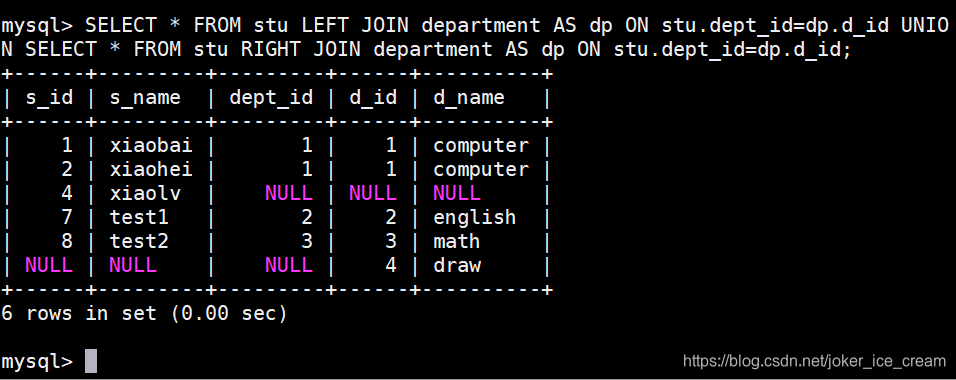
全连接
合并两个或者多个查询语句的结果集,并消除重复的行
左连接和右连接之后分别是:
将左右连接查询后全连接:
本来有十行,通过全连接去重后剩6行。
子表查询
在一个SQL语句中还有一个SQL语句
把查询到的数据当做一个表来使用:
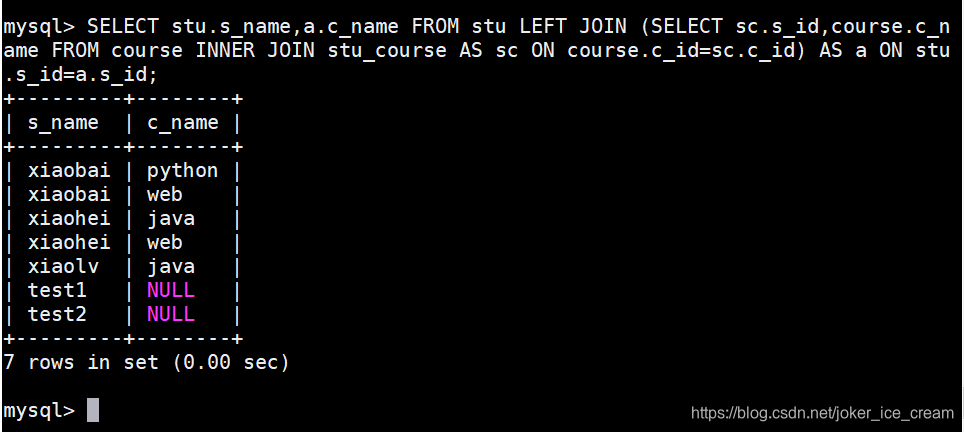
把查询到的数据当做一个SQL语句的条件来使用:
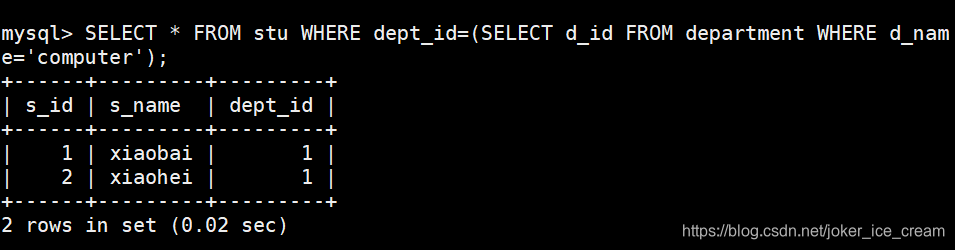
与下面的语句功能相同:
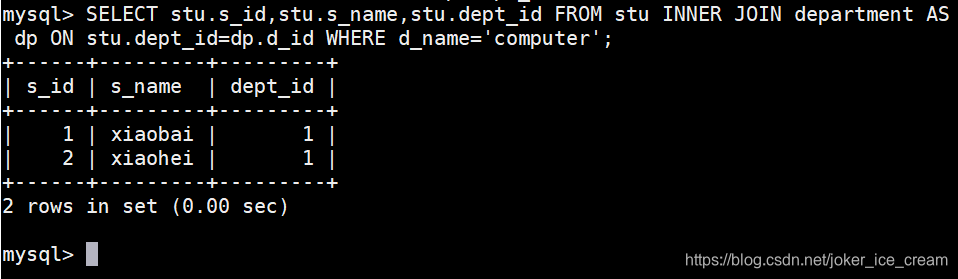
排序
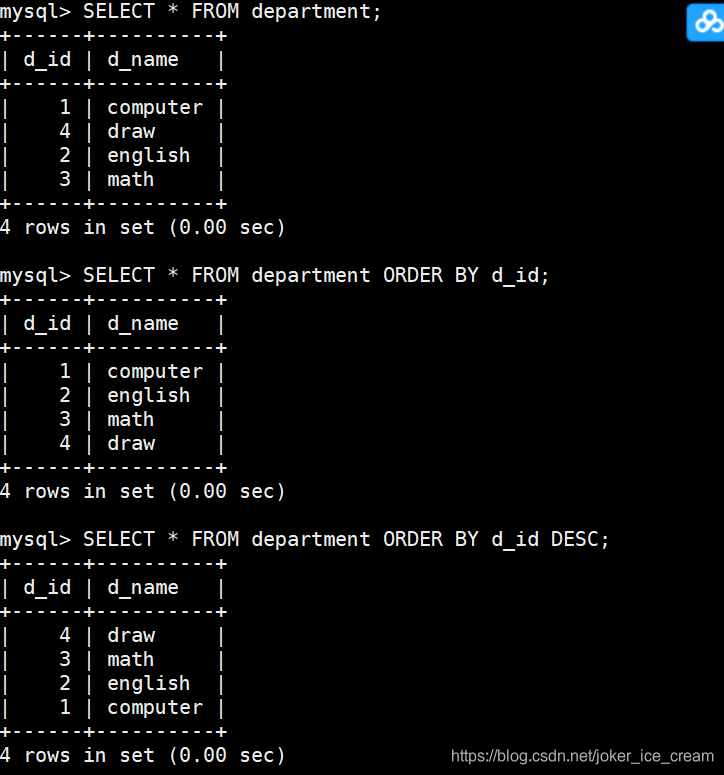
对查询出来的结果进行排序,ASC升序(默认) DESC降序
SELECT * FROM `students` s JOIN `student_details` sd ON s.`s_id`=sd.`stu_id` ORDER BY s.`s_id` DESC;
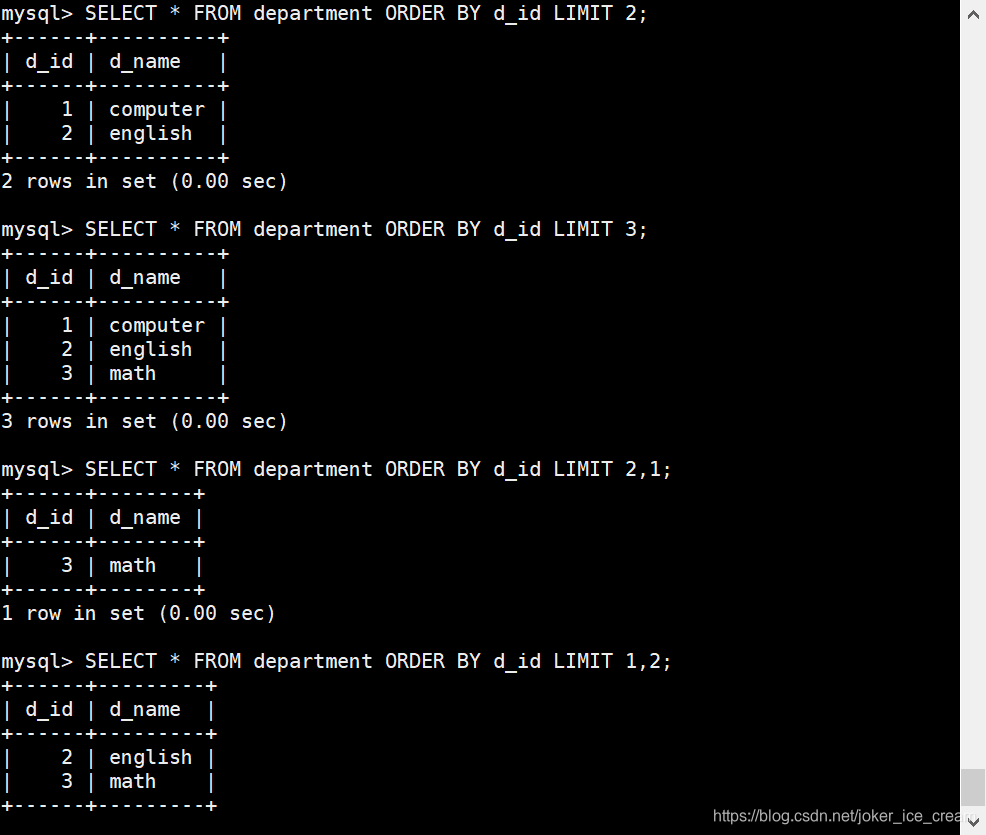
限制行数
对查询出来的结果限制显示的行数
SELECT * FROM `students` s JOIN `student_details` sd ON s.`s_id`=sd.`stu_id` ORDER BY s.`s_id` DESC LIMIT 3;
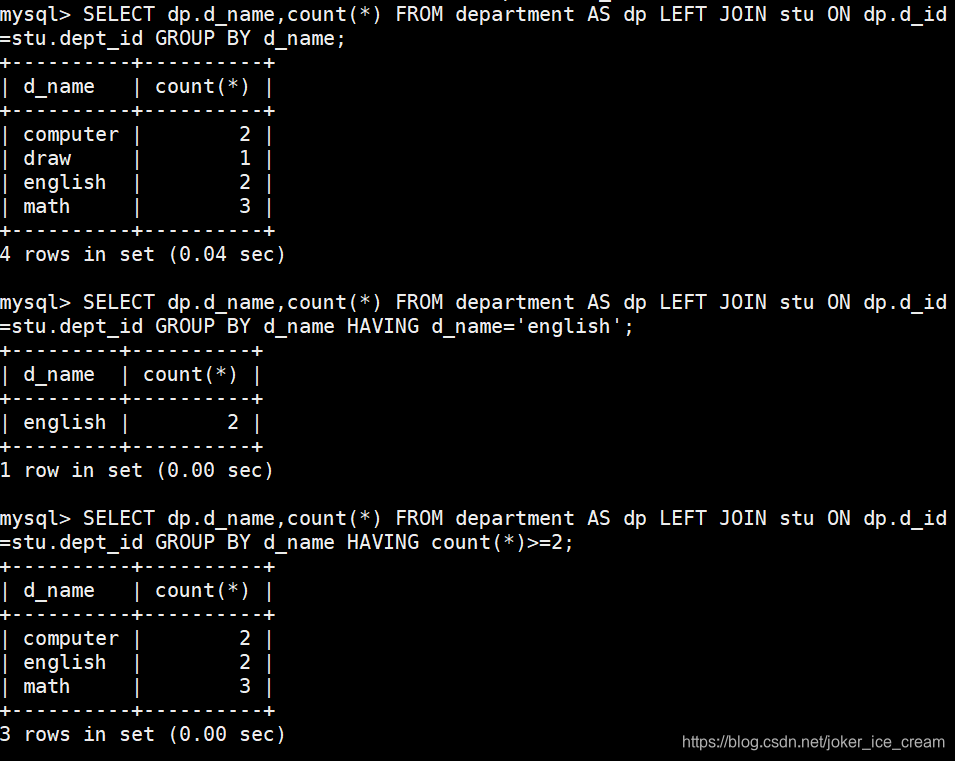
分组查询
分组是个常见的操作,常用于分组统计,使用GROUP BY后,会按照GROUP BY后面的字段进行分组,且必须是明确的字段,不能是*,因此SELECT后面也不能是*.其次可以使用 HAVING 可以对分组之后的结果进行筛选,注意:HAVING 后的字段必须是SELECT后出现过的
SELECT d.`d_id`,d.`name`,COUNT(*) FROM `department` d LEFT JOIN `students` s ON d.`d_id`=s.`dept_id` GROUP BY d.`d_id`,d.`name`;
SELECT d.`d_id`,d.`name`,COUNT(*) FROM `department` d LEFT JOIN `students` s ON d.`d_id`=s.`dept_id` GROUP BY d.`d_id`,d.`name` HAVING COUNT(*)>1;
MYSQL函数
字段处理,去重处理
SELECT s.`name`,IFNULL(sd.`id_card`,430) FROM `students` s LEFT JOIN `student_details` sd ON s.`s_id`=sd.`stu_id`; #处理NULL
SELECT DISTINCT `name` FROM `students` ; # 字段去重
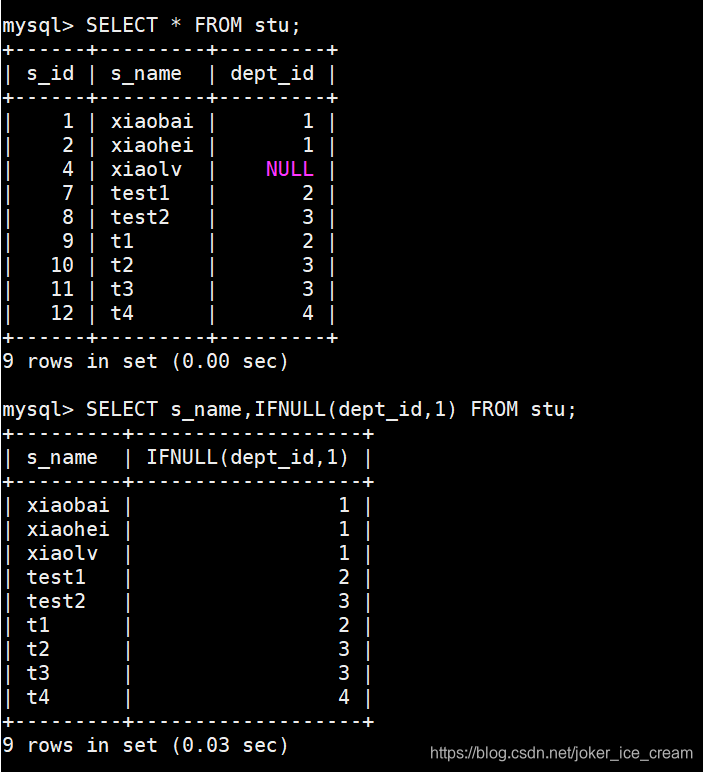
去除空值,将所有的NULL设置为某个值
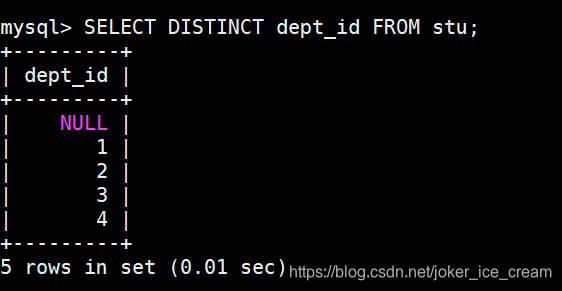
DISTINCT(distinct)去重
字符串截取
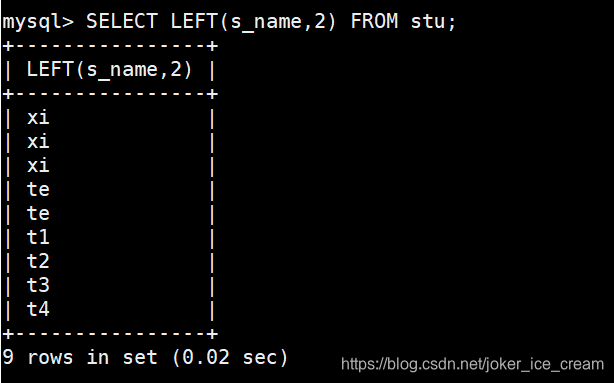
截取左边的两个字符:
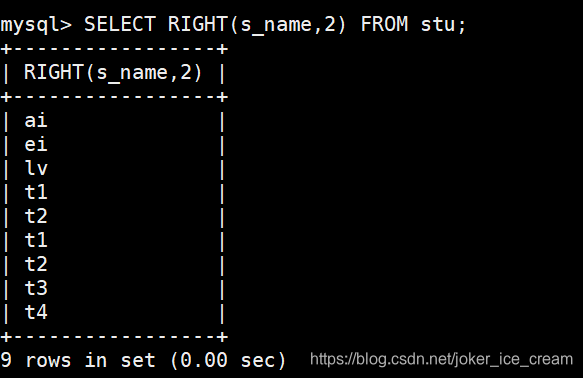
截取右边的两个字符:
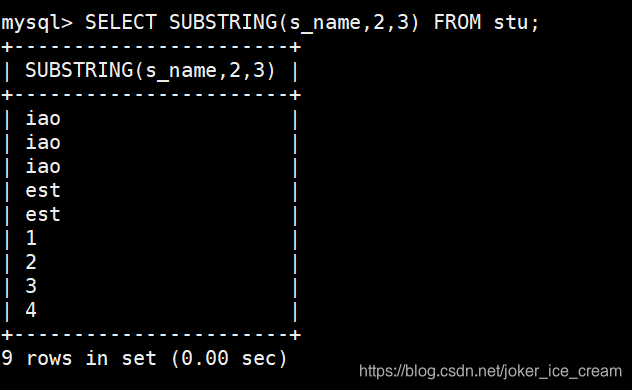
从第二个开始,截取三个字符:
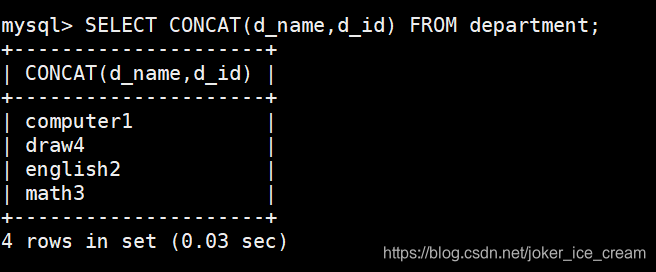
字符串拼接
SQL优化
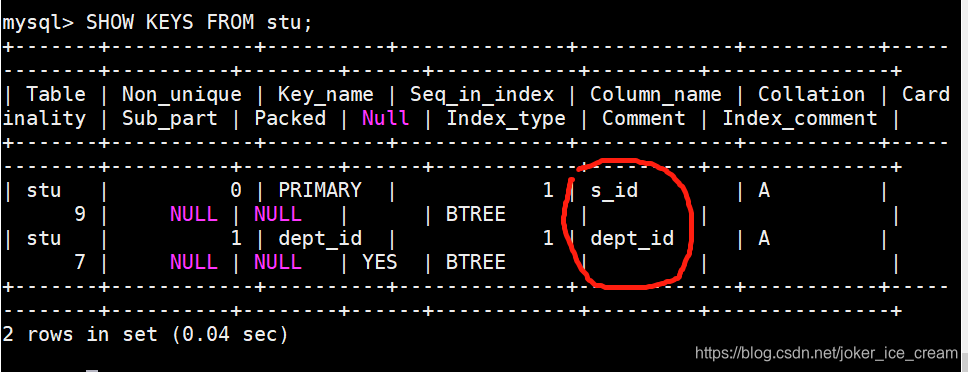
显示索引,一般在主外键创建的时候会自动创建索引,增加查询速度。






















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











