



 文章详细介绍了softmax分类器的原理,包括其如何将向量转换为概率分布以及在神经网络中的应用。接着,阐述了计算softmax损失和数值梯度的步骤,以及如何通过交叉验证选择合适的超参数,如学习率和正则化强度。最后,对比了softmax与svm的区别和联系。
文章详细介绍了softmax分类器的原理,包括其如何将向量转换为概率分布以及在神经网络中的应用。接着,阐述了计算softmax损失和数值梯度的步骤,以及如何通过交叉验证选择合适的超参数,如学习率和正则化强度。最后,对比了softmax与svm的区别和联系。
目录
前言:
Softmax classifier是一种用于多分类问题的分类器,它是Logistic Regression的一种推广。它的原理是将一个K维的实数向量转换为一个K维的概率分布,每个元素都在0和1之间,并且和为1。它通常用作神经网络的最后一个激活函数,以输出每个类别的概率。
一、原理介绍

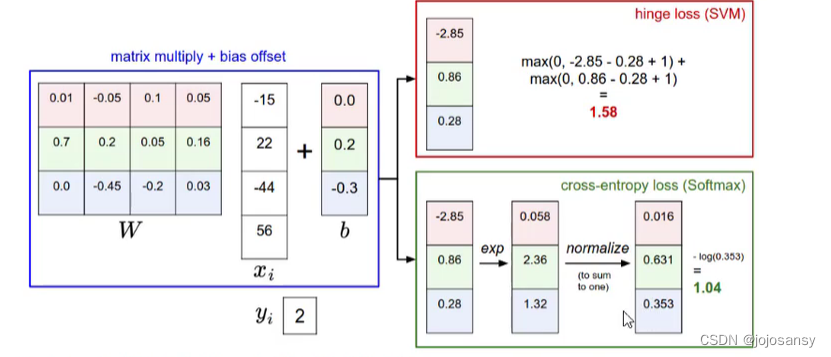
(绿色框是softmax的处理,把s矩阵每个元素用-e次幂处理,再用每个框内的元素依次除三个数的平均值得到处理之后的矩阵)
二、实现步骤
注:前面对数据的导入数据集的划分处理见上篇博客有明确的解释http://t.csdn.cn/IN4oI,本篇直接从核心代码剖析。
1.求softmax的损失和数值梯度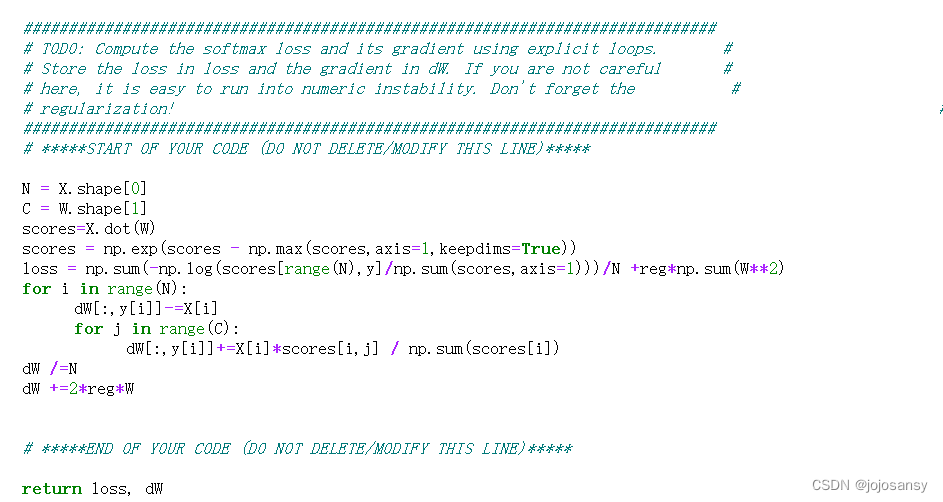
 (np.max(scores,axis=1)表示沿着第二个维度(即每一行)求最大值,返回一个一维数组,每个元素是对应行的最大值。keepdims=True表示保持输出数组的维度不变,即使它被缩减了。这样可以方便后续的运算或广播。例如,如果scores是一个二维数组,那么输出也是一个二维数组,只不过每一行只有一个元素。
(np.max(scores,axis=1)表示沿着第二个维度(即每一行)求最大值,返回一个一维数组,每个元素是对应行的最大值。keepdims=True表示保持输出数组的维度不变,即使它被缩减了。这样可以方便后续的运算或广播。例如,如果scores是一个二维数组,那么输出也是一个二维数组,只不过每一行只有一个元素。
这个代码对应的是原理图红色框的计算过程以及上面紫色图片中的处理数据让数据变得更加稳定的方法,通俗讲就是把列表的每个数减去列表中最大的数再进行幂次运算,再除平均值处理,来防止指数爆炸的情况出现。
loss这段代码的目的是计算一个叫做scores的二维数组(或矩阵)中每一行元素与对应标签y中的元素之间的交叉熵损失,并将所有损失相加得到总和。交叉熵损失是一种常用于机器学习分类问题中评估预测结果与真实结果之间差异的指标。具体来说,这段代码做了以下几个步骤:
使用scores[range(N),y]选取scores中每一行与y中对应元素相同列索引的元素,得到一个一维数组。
使用np.sum(scores,axis=1)对scores中每一行元素求和,得到一个一维数组。
使用scores[range(N),y]/np.sum(scores,axis=1)将第一步得到的数组除以第二步得到的数组,得到一个一维数组,表示每个样本预测正确类别的概率。
使用-np.log()对第三步得到的数组取负对数,得到一个一维数组,表示每个样本的交叉熵损失。使用sum()对第四步得到的数组求和,得到一个标量,表示所有样本的总交叉熵损失。)
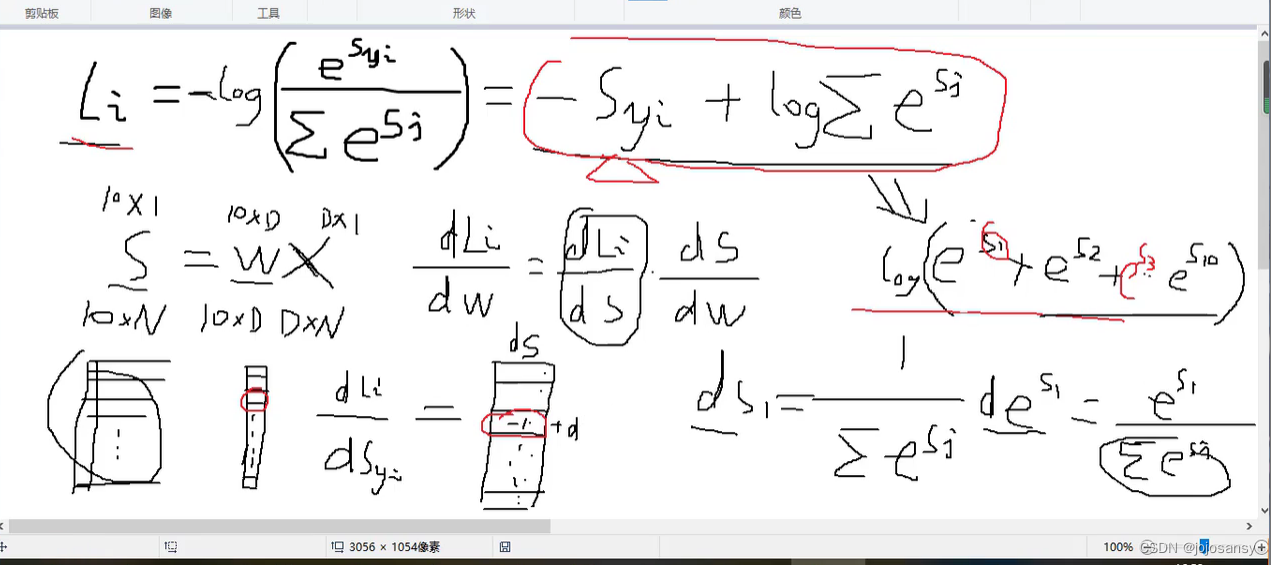
(梯度求导的原理图,依然是利用链式法则进行求导,基本思维与上篇博客一样)
2.交叉验证得到合适的超参数
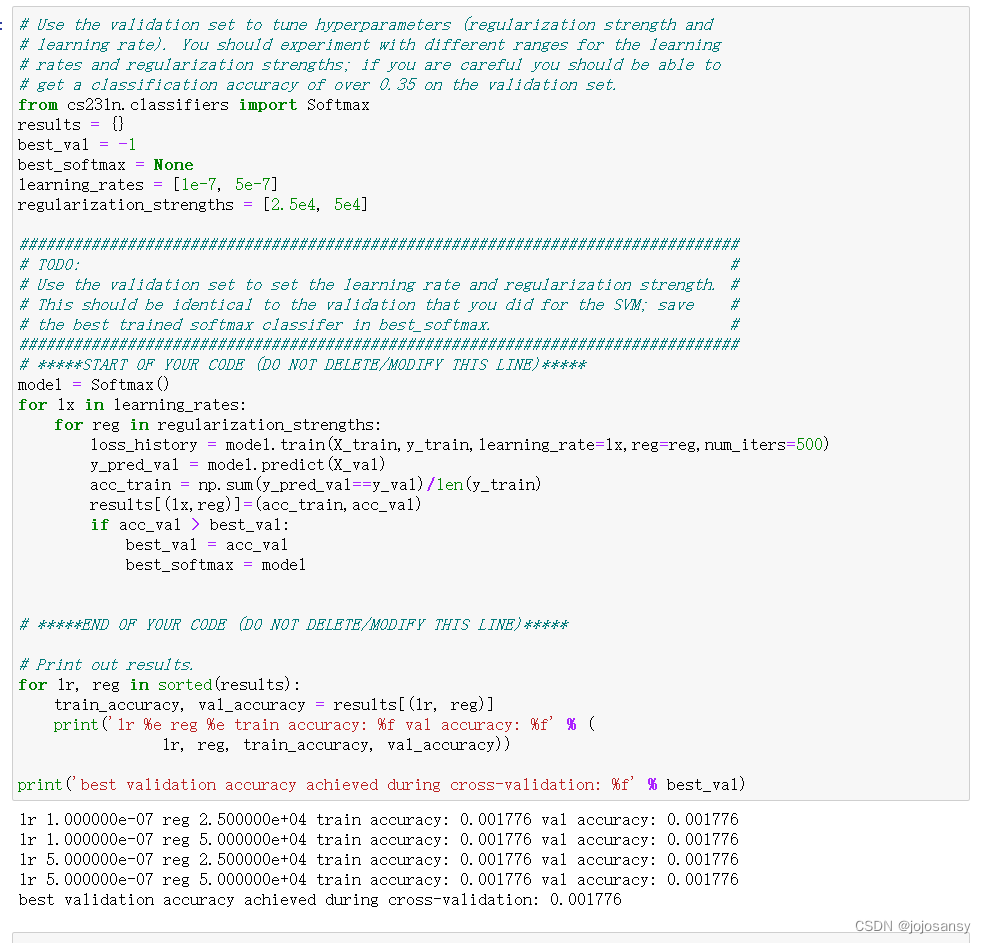
这段代码的目的是在训练集X_train和y_train上训练模型,并在验证集X_val和y_val上评估模型的准确率,同时调整两个超参数:学习率(learning_rate)和正则化强度(reg)。学习率是控制模型更新步长的参数,正则化强度是控制模型复杂度和防止过拟合的参数。
具体来说,这段代码做了以下几个步骤:
- 使用for循环遍历两个列表learning_rates和regularization_strengths中的所有组合,分别赋值给变量lx和reg。
- 使用model.train()方法在训练集上训练模型,传入学习率lx,正则化强度reg和迭代次数num_iters作为参数。得到一个叫做loss_history的列表,记录了每次迭代的损失值。
- 使用model.predict()方法在验证集上预测标签,得到一个叫做y_pred_val的数组。
- 使用np.sum()函数计算预测标签与真实标签相等的个数,并除以训练集长度得到训练集准确率acc_train。
- 使用results字典保存每一组超参数对应的训练集准确率和验证集准确率。
- 如果当前验证集准确率acc_val大于之前最好的验证集准确率best_val,则更新best_val,并将当前模型赋值给best_softmax。
3.可视化数据

总结:
softmax和svm是两种不同的分类器,它们都可以用于多分类问题,但是有一些区别和联系。
softmax是一种基于概率的分类器,它将每个类别的得分转换为一个概率分布,然后根据正确类别的负对数概率来计算损失。softmax的优点是输出更加直观,并且可以从概率上解释。softmax的缺点是它对异常值敏感,并且可能导致过拟合。
svm是一种基于间隔的分类器,它只要求正确类别的得分高于其他类别的得分一定的边界,然后根据边界内其他类别的得分之和来计算损失。svm的优点是它对异常值不敏感,并且可以防止过拟合。svm的缺点是输出不太直观,并且不能从概率上解释。
svm能够得到其他非标签的概率为0,但是softmax不可能其他非标签为0
softmax和svm之间还有一些联系,例如:
- 它们都可以用线性函数或非线性函数来表示每个类别的得分。
- 它们都可以用梯度下降或其他优化方法来更新参数。
- 它们都可以用正则化项来控制模型复杂度。
- 它们都可以用交叉验证或其他方法来选择超参数。

















 1820
1820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









