



一、边缘填充
为什么要进行边缘填充?我们以下图为例子


可以看到,左图在逆时针旋转45度之后原图的四个顶点在右图中已经看不到了,同时,右图的四个顶点区域其实是什么都没有的,因此我们需要对空出来的区域进行一个填充。右图就是对空出来的区域进行了像素值为(0,0,0)的填充,也就是黑色像素值的填充。除此之外,后续的一些图像处理方式也会用到边缘填充,这里介绍五个常用的边缘填充方法。
边界复制(BORDER_REPLICATE)
边界复制会将边界处的像素值进行复制,然后作为边界填充的像素值,如下图所示,可以看到四周的像素值都一样。
new_img=cv.warpAffine(img,M(w,h),cv.INTER_LANCZOS4,borderMode=cv.BORDER_REPLICATE)
边界反射(BORDER_REFLECT)
borderMode=cv.BORDER_REFLECT
边界常数(BORDER_CONSTANT)
当选择边界常数时,还要指定常数值是多少,默认的填充常数值为0,
borderValue=(0,0,255))
二、图像矫正(透视变换)
图像矫正的原理是透视变换,下面来介绍一下透视变换的概念。
听名字有点熟,我们在图像旋转里接触过仿射变换,知道仿射变换是把一个二维坐标系转换到另一个二维坐标系的过程,转换过程坐标点的相对位置和属性不发生变换,是一个线性变换,该过程只发生旋转和平移过程。因此,一个平行四边形经过仿射变换后还是一个平行四边形
而透视变换是把一个图像投影到一个新的视平面的过程,在现实世界中,我们观察到的物体在视觉上会受到透视效果的影响,即远处的物体看起来会比近处的物体小。透视投影是指将三维空间中的物体投影到二维平面上的过程,这个过程会导致物体在图像中出现形变和透视畸变。透视变换可以通过数学模型来校正这种透视畸变,使得图像中的物体看起来更符合我们的直观感受。通俗的讲,透视变换的作用其实就是改变一下图像里的目标物体的被观察的视角。
OpenCV里也提供了getPerspectiveTransform()函数用来生成该3*3的透视变换矩阵。
-
M=getPerspectiveTransform(src,dst)
在该函数中,需要提供两个参数:
src:原图像上需要进行透视变化的四个点的坐标,这四个点用于定义一个原图中的四边形区域。
dst:透视变换后,src的四个点在新目标图像的四个新坐标。
该函数会返回一个透视变换矩阵,得到透视变化矩阵之后,使用warpPerspective()函数即可进行透视变化计算,并得到新的图像。该函
数需要提供如下参数:
src:输入图像。
M:透视变换矩阵。这个矩阵可以通过getPerspectiveTransform函数计算得到。
dsize:输出图像的大小。它可以是一个Size对象,也可以是一个二元组。
flags:插值方法的标记。
borderMode:边界填充的模式。
太抽象了,举个例子。就以这个牛子为例


我要获取这个框里面的透视视角
先在画图软件去获取他的四个角的像素位置 。
M=getPerspectiveTransform(src,dst)
也就是这里的src,dst为变换后的坐标,自己设置
如果想占满原来屏幕大小就设置原图四个顶点。
这样我们得到M,透视矩阵
cv2.warpPerspective(src, M, dsize, flags, borderMode)
把图片,M带入进去,就可以得到新图片了。
import cv2 as cv
import numpy as np
img = cv.imread('./img/cow.png')
# 原图四点坐标
h, w = img.shape[:2]
point = np.float32([[178, 100], [487, 134], [124, 267], [473, 308]])
point2 = np.float32([[0, 0], [w, 0], [0, h], [w, h]])
M = cv.getPerspectiveTransform(point, point2)
img_copy = img.copy()
cv.line(img_copy, point[0].astype(np.int64).tolist(), point[1].astype(np.int64), (0, 0, 255), 2, cv.LINE_AA)
cv.line(img_copy, point[0].astype(np.int64).tolist(), point[2].astype(np.int64), (0, 0, 255), 2, cv.LINE_AA)
cv.line(img_copy, point[2].astype(np.int64).tolist(), point[3].astype(np.int64), (0, 0, 255), 2, cv.LINE_AA)
cv.line(img_copy, point[1].astype(np.int64).tolist(), point[3].astype(np.int64), (0, 0, 255), 2, cv.LINE_AA)
new_img = cv.warpPerspective(img_copy, M, (img.shape[1], img.shape[0]))
cv.imshow('img', img)
cv.imshow('new_img', new_img)
cv.imshow('img_copy', img_copy)
cv.waitKey(0)
cv.destroyAllWindows()

变换后我们的牛子就这样了
三、图像色彩空间转换
OpenCV中,图像色彩空间转换是一个非常基础且重要的操作,就是将图像从一种颜色表示形式转换为另一种表示形式的过程。通过将图像从一个色彩空间转换到另一个色彩空间,可以更好地进行特定类型的图像处理和分析任务。常见的颜色空间包括RGB、HSV、YUV等。
3.1RGB颜色空间
RGB颜色模型基于笛卡尔坐标系,如下图所示,RGB原色值位于3个角上,二次色青色、红色和黄色位于另外三个角上,黑色位于原点处,白色位于离原点最远的角上。因为黑色在RGB三通道中表现为(0,0,0),所以映射到这里就是原点;而白色是(255,255,255),所以映射到这里就是三个坐标为最大值的点。
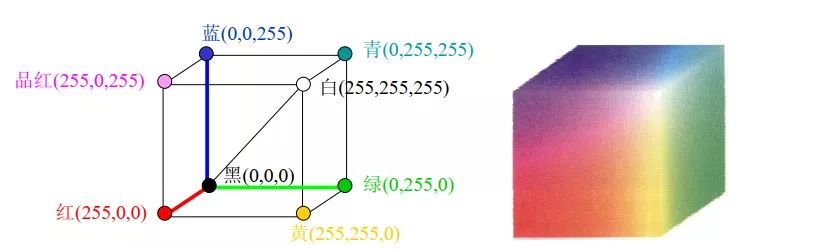
RGB颜色空间可以产生大约1600万种颜色,几乎包括了世界上的所有颜色,也就是说可以使用RGB颜色空间来生成任意一种颜色。
注意:在OpenCV中,颜色是以BGR的方式进行存储的,而不是RGB,这也是上面红色的像素值是(0,0,255)而不是(255,0,0)的原因。
颜色加法
你可以使用OpenCV的cv.add()函数把两幅图像相加,或者可以简单地通过numpy操作添加两个图像,如res = img1 + img2。两个图像应该具有相同的大小和类型。
OpenCV加法和Numpy加法之间存在差异。OpenCV的加法是饱和操作,而Numpy添加是模运算。
即Opencv会对超过最大值时取最大值即255,numpy直接相加会取模%(max+1 )
颜色加权加法
cv2.addWeighted(src1,alpha,src2,deta,gamma)
这其实也是加法,但是不同的是两幅图像的权重不同,这就会给人一种混合或者透明的感觉。图像混合的计算公式如下:
g(x) = (1−α)f0(x) + αf1(x)
通过修改 α 的值(0 → 1),可以实现非常炫酷的混合。
现在我们把两幅图混合在一起。第一幅图的权重是0.7,第二幅图的权重是0.3。函数cv2.addWeighted()可以按下面的公式对图片进行混合操作。
dst = α⋅img1 + β⋅img2 + γ
这里γ取为零。
import cv2 as cv
import numpy as np
x = np.uint8([[255]])
y = np.uint8([[10]])
# # cv.add()饱和操作
# print(cv.add(x, y))
# print(x+y)
pig = cv.imread('./img/pig.png')
pig1 = cv.resize(pig, (480, 480))
cao = cv.imread('./img/cao.png')
cao1 = cv.resize(cao, (480, 480))
img = cv.add(pig1, cao1) #opencv的加法
img1 = pig1 + cao1 #numpy数组运算
# 颜色加权加法 cv.addweighted(src1,α,src2,β,r)
img2 = cv.addWeighted(pig1, 0.7, cao1, 0.3, 0)
cv.imshow('img2', img2)
cv.imshow('img', img)
cv.imshow('img1', img1)
cv.waitKey(0)
cv.destroyAllWindows()



猪哥依次为cv,numpy,加权。可以看出numpy对于溢出就变的很离谱,本来应该量的地方,因为溢出,变为低值暗淡。
HSV颜色空间
HSV颜色空间指的是HSV颜色模型,这是一种与RGB颜色模型并列的颜色空间表示法。RGB颜色模型使用红、绿、蓝三原色的强度来表示颜色,是一种加色法模型,即颜色的混合是添加三原色的强度。而HSV颜色空间使用色调(Hue)、饱和度(Saturation)和亮度(Value)三个参数来表示颜色,色调H表示颜色的种类,如红色、绿色、蓝色等;饱和度表示颜色的纯度或强度,如红色越纯,饱和度就越高;亮度表示颜色的明暗程度,如黑色比白色亮度低。
HSV颜色模型是一种六角锥体模型,如下图所示:
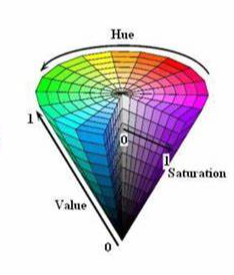 色调H:
色调H:
使用角度度量,取值范围为0°~360°,从红色开始按逆时针方向计算,红色为0°,绿色为120°,蓝色为240°。它们的补色是:黄色为60°,青色为180°,紫色为300°。通过改变H的值,可以选择不同的颜色
饱和度S:
饱和度S表示颜色接近光谱色的程度。一种颜色可以看成是某种光谱色与白色混合的结果。其中光谱色所占的比例越大,颜色接近光谱色的程度就越高,颜色的饱和度就越高。饱和度越高,颜色就越深而艳,光谱色的白光成分为0,饱和度达到最高。通常取值范围为0%~100%,其中0%表示灰色或无色,100%表示纯色,通过调整饱和度的值,可以使颜色变得更加鲜艳或者更加灰暗。
明度V:
明度表示颜色明亮的程度,对于光源色,明度值与发光体的光亮度有关;对于物体色,此值和物体的透射比或反射比有关。通常取值范围为0%(黑)到100%(白),通过调整明度的值,可以使颜色变得更亮或者更暗。
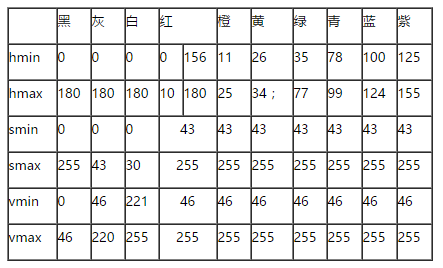
一般对颜色空间的图像进行有效处理都是在HSV空间进行的,然后对于基本色中对应的HSV分量需要给定一个严格的范围,下面是通过实验计算的模糊范围(准确的范围在网上都没有给出)。
H: 0— 180
S: 0— 255
V: 0— 255
此处把部分红色归为紫色范围:
为什么有了RGB颜色空间我们还是需要转换成HSV颜色空间来进行图像处理呢?
-
符合人类对颜色的感知方式:人类对颜色的感知是基于色调、饱和度和亮度三个维度的,而HSV颜色空间恰好就是通过这三个维度来描述颜色的。因此,使用HSV空间处理图像可以更直观地调整颜色和进行色彩平衡等操作,更符合人类的感知习惯。
-
颜色调整更加直观:在HSV颜色空间中,色调、饱和度和亮度的调整都是直观的,而在RGB颜色空间中调整颜色不那么直观。例如,在RGB空间中要调整红色系的颜色,需要同时调整R、G、B三个通道的数值,而在HSV空间中只需要调整色调和饱和度即可。
-
降维处理有利于计算:在图像处理中,降维处理可以减少计算的复杂性和计算量。HSV颜色空间相对于RGB颜色空间,减少了两个维度(红、绿、蓝),这有利于进行一些计算和处理任务,比如色彩分割、匹配等。
因此,在进行图片颜色识别时,我们会将RGB图像转换到HSV颜色空间,然后根据颜色区间来识别目标颜色
import cv2 as cv
import numpy as np
img = cv.imread('./img/pig.png')
hsv = cv.cvtColor(img, cv.COLOR_BGR2HSV)#转hsv
cv.imshow('hsv', hsv)
cv.waitKey(0)
cv.destroyAllWindows()
四、灰度实验
将彩色图像转换为灰度图像的过程称为灰度化,这种做法在图像处理和计算机视觉领域非常常见。
灰度图与彩色图最大的不同就是:彩色图是由R、G、B三个通道组成,而灰度图只有一个通道,也称为单通道图像,所以彩色图转成灰度图的过程本质上就是将R、G、B三通道合并成一个通道的过程。本实验中一共介绍了三种合并方法,分别是最大值法、平均值法以及加权均值法。
灰度图
每个像素只有一个采样颜色的图像,这类图像通常显示为从最暗黑色到最亮的白色的灰度,尽管理论上这个采样可以任何颜色的不同深浅,甚至可以是不同亮度上的不同颜色。灰度图像与黑白图像不同,在计算机图像领域中黑白图像只有黑色与白色两种颜色;但是,灰度图像在黑色与白色之间还有许多级的颜色深度。灰度图像经常是在单个电磁波频谱如可见光内测量每个像素的亮度得到的,用于显示的灰度图像通常用每个采样像素8位的非线性尺度来保存,这样可以有256级灰度。
1.最大值法
对于彩色图像的每个像素,它会从R、G、B三个通道的值中选出最大的一个,并将其作为灰度图像中对应位置的像素值。
例如三通道彩色图其中一个像素(123,112,189),那么使用最大值法,转为灰度图对应的灰色单通道像素为(189)。
import cv2 as cv
import numpy as np
img = cv.imread('./img/pig.png')
shape = img.shape
print(shape, type(shape))
# 创建一个全0矩阵,宽高等于原图
my_gray = np.zeros((shape[0], shape[1]), dtype=np.uint8)
# 遍历原图,拿到三个通道中的最大值
for i in range(shape[0]):
for j in range(shape[1]):
my_gray[i, j] = max(img[i, j])
cv.imshow('gray', img)
cv.imshow('my_gray', my_gray)
cv.waitKey(0)
cv.destroyAllWindows()
2.平均值法
对于彩色图像的每个像素,它会将R、G、B三个通道的像素值全部加起来,然后再除以三,得到的平均值就是灰度图像中对应位置的像素值。
import cv2 as cv
import numpy as np
img = cv.imread('./img/pig.png')
my_gray = np.zeros((img.shape[0], img.shape[1]), dtype=np.uint8)
for i in range(img.shape[0]):
for j in range(img.shape[1]):
my_gray[i][j] = np.uint8(
np.mean([float(img[i, j, 0]), float(img[i, j, 1]), float(img[i, j, 2])]))
cv.imshow('img', img)
cv.imshow('my_gray', my_gray)
cv.waitKey(0)
cv.destroyAllWindows()
这里必须转换为浮点进行加法,否则溢出报错。uint8为8位二进制255,所以先转换再加,最后转回uint8
3.加权均值法
对于彩色图像的每个像素,它会按照一定的权重去乘以每个通道的像素值,并将其相加,得到最后的值就是灰度图像中对应位置的像素值。本实验中,权重的比例为: R乘以0.299,G乘以0.587,B乘以0.114,这是经过大量实验得到的一个权重比例,也是一个比较常用的权重比例。
所使用的权重之和应该等于1。这是为了确保生成的灰度图像素值保持在合理的亮度范围内,并且不会因为权重的比例不当导致整体过亮或过暗。
import cv2 as cv
import numpy as np
R = 0.299
G = 0.587
B = 0.114
img = cv.imread('./img/pig.png')
my_gray = np.zeros((img.shape[0], img.shape[1]), dtype=np.uint8)
for i in range(img.shape[0]):
for j in range(img.shape[1]):
my_gray[i][j] = np.uint8(round(img[i][j][0]*B + img[i][j][1]*G + img[i][j][2]*R))
cv.imshow('img', img)
cv.imshow('my_gray', my_gray)
cv.waitKey(0)
cv.destroyAllWindows()
五、图像二值化处理
将某张图像的所有像素改成只有两种值之一
二值图像
一幅二值图像的二维矩阵仅由0、1两个值构成,“0”代表黑色,“1”代白色。由于每一像素(矩阵中每一元素)取值仅有0、1两种可能,所以计算机中二值图像的数据类型通常为1个二进制位。二值图像通常用于文字、线条图的扫描识别(OCR)和掩膜图像的存储。
其操作的图像也必须是灰度图。也就是说,二值化的过程,就是将一张灰度图上的像素根据某种规则修改为0和maxval(maxval表示最大值,一般为255,显示白色)两种像素值,使图像呈现黑白的效果,能够帮助我们更好地分析图像中的形状、边缘和轮廓等特征。
-
简便:降低计算量和计算需求,加快处理速度。
-
节约资源:二值图像占用空间远小于彩色图。
-
边缘检测:二值化常作为边缘检测的预处理步骤,因为简化后的图易于识别出轮廓和边界。
1.阈值法(THRESH_BINARY)
通过自己设置阈值,小于阈值的变为0,大于阈值的变为maxval
2.反阈值法(THRESH_BINARY_INV)
顾名思义,和阈值法反着来。小于阈值的设置为maxval,大于阈值的变为0
3.截断阈值法(THRESH_TRUNC)
截断阈值法,指将灰度图中的所有像素与阈值进行比较,像素值大于阈值的部分将会被修改为阈值,小于等于阈值的部分不变。
换句话说,经过截断阈值法处理过的二值化图中的最大像素值就是阈值
4.低阈值零处理(THRESH_TOZERO)
低阈值零处理,字面意思,就是像素值小于等于阈值的部分被置为0(也就是黑色),大于阈值的部分不变。
5.超阈值零处理(THRESH_TOZERO_INV)
超阈值零处理就是将灰度图中的每个像素与阈值进行比较,像素值大于阈值的部分置为0(也就是黑色),像素值小于等于阈值的部分不变。
import cv2 as cv
import numpy as np
gry = cv.imread('./img/flower.png', cv.IMREAD_GRAYSCALE)
# 二值化:阈值法
_, img = cv.threshold(gry, 127, 255, cv.THRESH_BINARY)
# 反阈值法
_, img2 = cv.threshold(gry, 127, 255, cv.THRESH_BINARY_INV)
# 截断阈值法
_, img3 = cv.threshold(gry, 127, 255, cv.THRESH_TRUNC)
# 低阈值0处理 低于阈值的变为0
_, img4 = cv.threshold(gry, 127, 255, cv.THRESH_TOZERO)
# 超阈值零处理,超过的设为0,小于的不变
_, img5 = cv.threshold(gry, 127, 255, cv.THRESH_TOZERO_INV)
img3 = cv.resize(img3, (400, 400))
img = cv.resize(img, (400, 400))
img2 = cv.resize(img2, (400, 400))
img4 = cv.resize(img4, (400, 400))
img5 = cv.resize(img5, (400, 400))
# cv.imshow('img', img)
cv.imshow('gry', gry)
cv.imshow('img2', img2)
cv.imshow('img3', img3)
cv.imshow('img4', img4)
cv.imshow('img5', img5)
cv.waitKey(0)
cv.destroyAllWindows()
六、图像掩膜
掩膜(Mask)是一种在图像处理中常见的操作,它用于选择性地遮挡图像的某些部分,以实现特定任务的目标。掩膜通常是一个二值化图像,并且与原图像的大小相同,其中目标区域被设置为1(或白色),而其他区域被设置为0(或黑色),并且目标区域可以根据HSV的颜色范围进行修改,如下图就是制作黄色掩膜的过程:
import cv2 as cv
import numpy as np
img = cv.imread('./img/demo.png')
img_hsv = cv.cvtColor(img, cv.COLOR_BGR2HSV)
cv.resize(img, (640, 480))
color_lower = np.array([26, 43, 46])
color_higher = np.array([34, 255, 255])
mask = cv.inRange(img_hsv, color_lower, color_higher)
cv.imshow('mask', mask)
cv.imshow('img', img)
cv.imshow('img_hsv', img_hsv)
cv.waitKey(0)
cv.destroyAllWindows()



依次为原图,hsv,掩膜
与运算
我们在高中时学过逻辑运算中的“与”运算,其规则是当两个命题都是真时,其结果才为真。而在图像处理中,“与”运算被用来对图像的像素值进行操作。具体来说,就是将两个图像中所有的对应像素值一一进行“与”运算,从而得到新的图像。从上面的图片我们可以看出,掩膜中有很多地方是黑色的,其像素值为0,那么在与原图像进行“与”运算的时候,得到的新图像的对应位置也是黑色的,如下图所示:

yellow = cv.bitwise_and(img, img, mask=mask)
cv.imshow('yellow', yellow)
cv.waitKey(0)
cv.destroyAllWindows()
这样就可以筛选了
颜色替换
由于掩膜与原图的大小相同,并且像素位置一一对应,那么我们就可以得到掩膜中白色(也就是像素值为255)区域的坐标,并将其带入到原图像中,即可得到原图中的红色区域的坐标,然后就可以修改像素值了,这样就完成了颜色的替换,如下图所示:
img[mask == 255] = [0, 0, 255]
原图黄色的地方就变为红色了。

















 1253
1253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









