




 原型网络是一种小样本学习方法,通过计算类别的平均特征(类中心)来表示类别,提高模型对噪声的鲁棒性。算法涉及N-wayK-shot任务,使用度量如欧式距离来决定样本归属。与MatchNetworks的主要区别在于度量方式和网络结构,原型网络在one-shot和few-shot场景下表现不同。实验表明,使用余弦相似度通常能取得更好的效果。
原型网络是一种小样本学习方法,通过计算类别的平均特征(类中心)来表示类别,提高模型对噪声的鲁棒性。算法涉及N-wayK-shot任务,使用度量如欧式距离来决定样本归属。与MatchNetworks的主要区别在于度量方式和网络结构,原型网络在one-shot和few-shot场景下表现不同。实验表明,使用余弦相似度通常能取得更好的效果。
1.论文和代码
- 论文链接:1703.05175.pdf
- 代码1
- 代码2
2.简介
小样本学习不仅仅训练和测试集的样本没有交集,类别也是没有交集的
论文一共做了两个任务:1.小样本;2. 零样本。
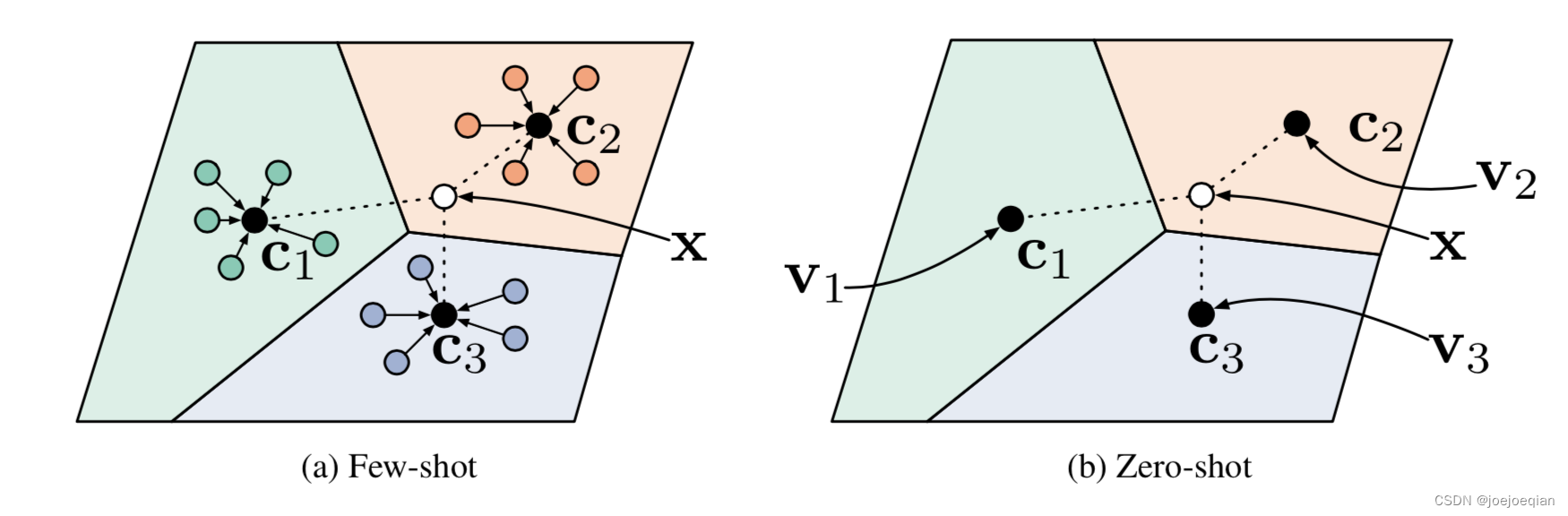
如图左边:
三种颜色代表三个类别(3-way), c 1 , c 2 , c 3 c_1,c_2,c_3 c1,c2,c3分别是三个类别的中心,用类中心表示类别的好处就是某个类别中某些数据存在一些噪声,用类中心来表示这个特征,比较robust,类中心对抗噪声的能力比单个样本生存的这个特征要强很多。
类中心(prototypes)用各类别下所有样本特征的平均值来计算的: v c = 1 ∣ S c ∣ ∑ ( x i , y i ) ∈ S c f θ ( x i ) v_c=\frac{1}{|S_c|}\sum_{(x_i,y_i)\in S_c} f_{\theta}(x_i) vc=∣Sc∣1(xi,yi)∈Sc∑fθ(xi)
X X X为是Query set,要确定它的类别,判断它的类别需要它分别计算与 c 1 , c 2 , c 3 c_1,c_2,c_3 c1,c2,c3之间的距离,哪一个距离越小,与哪个类别的相似度就越大,就归为哪一类。
基于度量的元学习,度量类别与类别之间的距离的一些指标(欧式距离或者余弦距离等)。
3.算法流程

3.1 名词解释及符号定义
- episode:表示一个N-way K-shot任务,N为类别数,K为每个类别的数量。 N C N_C NC为每个任务中类别的数量, N S + N Q N_S+N_Q NS+NQ每个类别样本的数量。这里就是 N C N_C NC-way N S N_S NS-shot N Q N_Q N
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2070
2070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









