



 CART算法是一种用于构建决策树的常用方法,适用于分类和回归问题。在分类问题中,CART通过基尼指数选择最优特征进行划分,而回归问题中则是基于最小化平方误差。文章详细介绍了CART算法的特征选择、模型生成、剪枝过程以及如何处理连续值。此外,还提供了实例分析,展示了如何用CART算法构建分类树和回归树,并讨论了剪枝策略,以平衡模型的复杂度和泛化能力。
CART算法是一种用于构建决策树的常用方法,适用于分类和回归问题。在分类问题中,CART通过基尼指数选择最优特征进行划分,而回归问题中则是基于最小化平方误差。文章详细介绍了CART算法的特征选择、模型生成、剪枝过程以及如何处理连续值。此外,还提供了实例分析,展示了如何用CART算法构建分类树和回归树,并讨论了剪枝策略,以平衡模型的复杂度和泛化能力。
决策树CART算法
1.CART算法
对于CART分类树连续值的处理问题,其思想和C4.5是相同的,都是将连续的特征离散化。唯一的区别在于在选择划分点时的度量方式不同,C4.5使用的是信息增益比,则CART分类树使用的是基尼系数。
CART(Classification and Regression Tree)算法包括三步走:选择特征、生成决策树、剪枝
之前的决策树一般都是多叉树

而CART是二叉树,怎么转换。
例如:对于
纹理这个特征而言,可以分为清晰、稍模糊、模糊三叉,但是如果把这个三叉树改成二叉树,就可以写成清晰和不清晰,接着在「不清晰」中,再分为模糊和稍模糊
2.特征选择-基尼指数
要想生成一棵决策树,首先应该选择最优特征。在CART算法中,是通过基尼指数来选择最优特征的,ID3和C4.5是使用信息增益和信息增益比。
2.1 基尼指数
假设有 K K K个类,样本点属于第 k k k类的概率为 p k p_k pk ,概率分布的基尼指数定义为: G i n i ( p ) = ∑ k = 1 K p k ( 1 − p k ) = 1 − ∑ k = 1 K p k 2 Gini(p)=\sum_{k=1}^Kp_k(1-p_k)=1-\sum_{k=1}^Kp_k^2 Gini(p)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2
显然,这就是样本点被错分的概率期望。如果整个样本集只有一个类别,那么基尼指数就是0,表示样本集纯度达到最高值。反正总共就一个类,那么任意抽取一个样本,自然就知道它的归属类别。
2.2 对于二类分类问题
如果样本点属于第一类的概率是
p
p
p,不属于的概率就是
1
−
p
1-p
1−p,代入到这个公式里就是:
G
i
n
i
(
p
)
=
p
(
1
−
p
)
+
(
1
−
p
)
(
1
−
(
1
−
p
)
)
=
2
p
(
1
−
p
)
\begin{aligned}Gini(p)&=p(1-p)+(1-p)(1-(1-p))\\&=2p(1-p)\end{aligned}
Gini(p)=p(1−p)+(1−p)(1−(1−p))=2p(1−p)
然而实际生活中概率
p
p
p无法知道,只能用估计值,所以有以下:
如果对给定的样本集合 D D D,可以分为两个子集 C 1 C_1 C1和 C 2 C_2 C2: G i n i ( p ) = 1 − ∑ k = 1 2 ( ∣ C k ∣ ∣ D ∣ ) 2 Gini(p)=1-\sum_{k=1}^2\left(\frac{|C_k|}{|D|}\right)^2 Gini(p)=1−k=1∑2(∣D∣∣Ck∣)2,其中 ∣ C k ∣ ∣ D ∣ \frac{|C_k|}{|D|} ∣D∣∣Ck∣就是 p p p的经验值。
之所以单独把二分类的情况列出来,是因为在提出基尼指数的CART算法中用的就是这个,毕竟CART算法生成的是二叉决策树。但其实基尼指数完全可以用到多分类问题中。
如:对于特征A条件下,样本集D的基尼指数为
G i n i ( D , A ) = ∣ D 1 ∣ ∣ D ∣ G i n i ( D 1 ) + ∣ D 2 ∣ ∣ D ∣ G i n i ( D 2 ) Gini(D,A)=\frac{|D_1|}{|D|}Gini(D_1)+\frac{|D_2|}{|D|}Gini(D_2) Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
这里就是选定了特征A,并且将数据集中按照特征分成了两个数据集,再分别求它们对应的基尼指数。
2.3 例子
拿水蜜桃来举个例子。一共
10
10
10个桃子,其中
5
5
5个好吃,
5
5
5个不好吃。
那么可以计算出整个数据集的基尼指数:
G
i
n
i
(
D
)
=
2
p
(
1
−
p
)
=
2
∗
1
2
∗
1
2
=
0.5
Gini(D)=2p(1-p)=2*\frac{1}{2}*\frac{1}{2}=0.5
Gini(D)=2p(1−p)=2∗21∗21=0.5,分类:好吃和不好吃,两种。
第一个特征,选择甜度特征
按照阈值 ϵ = 0.2 \epsilon=0.2 ϵ=0.2分成两组。
假设,甜度大于 0.2 0.2 0.2的有 6 6 6个桃子,其中 5 5 5个好吃, 1 1 1个不好吃,甜度小于等于 0.2 0.2 0.2的有 4 4 4个桃子,都不好吃,那么我们就可以列出这样一个二叉树。数据集就被分成了 D 1 D_1 D1和 D 2 D_2 D2两个。这里我们把甜度特征标记为 A A A。
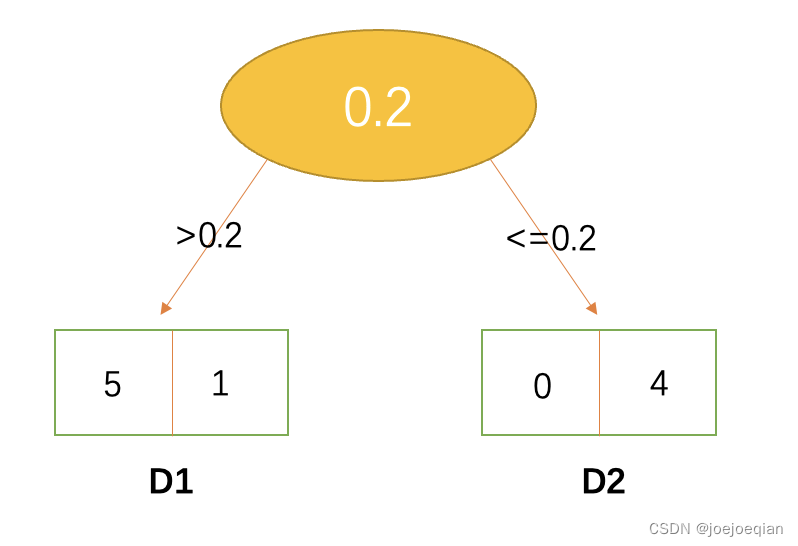
接着来计算甜度特征下的基尼指数。
计算
D
1
D_1
D1数据集的基尼指数:
G
i
n
i
(
D
1
)
=
2
∗
5
6
∗
1
6
=
10
36
Gini(D_1)=2*\frac{5}{6}*\frac{1}{6}=\frac{10}{36}
Gini(D1)=2∗65∗61=3610
接着计算
D
1
D_1
D1占比的权重为:
w
1
=
6
10
w_1=\frac{6}{10}
w1=106
计算
D
2
D_2
D2数据集的基尼指数:
G
i
n
i
(
D
2
)
=
2
∗
0
4
∗
4
4
=
0
Gini(D_2)=2*\frac{0}{4}*\frac{4}{4}=0
Gini(D2)=2∗40∗44=0
接着计算
D
2
D_2
D2占比的权重为:
w
2
=
4
10
w_2=\frac{4}{10}
w2=104
计算甜度特征下的基尼指数
G
i
n
i
(
D
,
A
)
=
6
10
∗
10
36
+
4
10
∗
0
=
0.17
Gini(D,A)=\frac{6}{10}*\frac{10}{36}+\frac{4}{10}*0=0.17
Gini(D,A)=106∗3610+104∗0=0.17
第二个特征,选择硬度特征,按照软硬分成两组。
假设,有5个硬桃子,其中2个好吃,3个不好吃,5个软桃子中,有3个好吃,2个不好吃。那么继续列出一个二叉树,这里我们把硬度特征标记为
B
B
B。
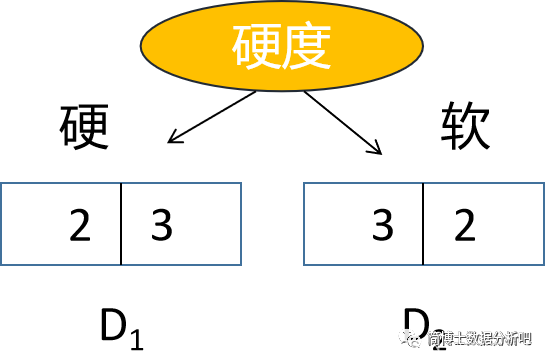
计算
D
1
D_1
D1数据集的基尼指数:
G
i
n
i
(
D
1
)
=
2
∗
2
5
∗
3
5
=
12
25
Gini(D_1)=2*\frac{2}{5}*\frac{3}{5}=\frac{12}{25}
Gini(D1)=2∗52∗53=2512
接着计算
D
1
D_1
D1占比的权重为:
w
1
=
5
10
w_1=\frac{5}{10}
w1=105
计算
D
2
D_2
D2数据集的基尼指数:
G
i
n
i
(
D
2
)
=
2
∗
3
5
∗
2
5
=
12
25
Gini(D_2)=2*\frac{3}{5}*\frac{2}{5}=\frac{12}{25}
Gini(D2)=2∗53∗52=2512
接着计算
D
2
D_2
D2占比的权重为:
w
2
=
5
10
w_2=\frac{5}{10}
w2=105
计算甜度特征下的基尼指数:
G
i
n
i
(
D
,
B
)
=
1
2
∗
12
25
+
1
2
∗
12
25
=
0.48
Gini(D,B)=\frac{1}{2}*\frac{12}{25}+\frac{1}{2}*\frac{12}{25}=0.48
Gini(D,B)=21∗2512+21∗2512=0.48
通过比较可以看出:
G
i
n
i
(
D
,
A
)
<
G
i
n
i
(
D
,
B
)
Gini(D,A)<Gini(D,B)
Gini(D,A)<Gini(D,B)
按照甜度分类时,分类的确定性更胜一筹,那么就可以用这个特征作为最优特征。
这就是用基尼指数来找到最优特征的方法,通过对数据集中不同特征进行基尼指数的遍历计算,就能得出最小时对应的特征,这就完成了CART算法中的第一步。
2.4 CART分类树算法解读
输入:数据集
D
D
D,特征集
A
A
A,停止条件阈值
ϵ
\epsilon
ϵ
输出:CART分类决策树
第一步,从根节点出发,构建二叉树
第二步,计算现有特征下对数据集 D D D基尼指数,选择最优特征
假设特征集 A A A中 A 1 , A 2 , ⋯ , A n A_1,A_2,\cdots,A_n A1,A2,⋯,An个特征,那么我们先选出 A 1 A_1 A1特征,假设这个特征里,有 a 11 , a 12 , ⋯ , a 1 m 1 a_{11},a_{12},\cdots,a_{1m_1} a11,a12,⋯,a1m1 个值,那么对数据集 D D D按照每一个 a 1 i a_{1i} a1i特征值来分成 D 1 D_1 D1和 D 2 D_2 D2两个数据集,并且计算一下对应的基尼指数,选择基尼指数最小的那个特征值 a 1 i a_{1i} a1i作为最优切分点。
以此类推,得出每个特征下的最优切分点,也就是最优的特征值。接着比较在最优切分下每个特征的基尼指数,选择基尼指数最小的那个特征,就是最优特征。
第三步,根据最优特征和最优切分点,生成两个子节点,并将数据集分配到对应的子节点中。
按照最优切分点来分成二叉树。
第四步,分别对两个子节点继续递归调用上面的步骤,直到满足条件,即生成CART分类决策树。
这里的条件,一般就是阈值 ,当基尼指数小于这个阈值时,意味着样本基本上属于一类,或者就是没有更多的特征了,那么就完成了CART分类决策树的生成。
2.5 例题:分类树(分类问题)
训练集
D
D
D,特征集分别是
A
1
A_1
A1年龄,
A
2
A_2
A2是否有工作,
A
3
A_3
A3是否有自己的房子,
A
4
A_4
A4信贷情况。
类别为
y
1
=
是
y_1=是
y1=是,
y
2
=
否
y_2=否
y2=否
贷款申请样本数据表:
| ID | 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别 |
|---|---|---|---|---|---|
| 1 | 青年 | 否 | 否 | 一般 | 否 |
| 2 | 青年 | 否 | 否 | 好 | 否 |
| 3 | 青年 | 是 | 否 | 好 | 是 |
| 4 | 青年 | 是 | 是 | 一般 | 是 |
| 5 | 青年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 一般 | 否 |
| 7 | 中年 | 否 | 否 | 好 | 否 |
| 8 | 中年 | 是 | 是 | 好 | 是 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 中年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 非常好 | 是 |
| 12 | 老年 | 否 | 是 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 好 | 是 |
| 14 | 老年 | 是 | 否 | 非常好 | 是 |
| 15 | 老年 | 否 | 否 | 一般 | 否 |
回顾一下公式:
对于特征A条件下,样本集D的基尼指数为:
G
i
n
i
(
D
,
A
)
=
∣
D
1
∣
∣
D
∣
G
i
n
i
(
D
1
)
+
∣
D
2
∣
∣
D
∣
G
i
n
i
(
D
2
)
Gini(D,A)=\frac{|D_1|}{|D|}Gini(D_1)+\frac{|D_2|}{|D|}Gini(D_2)
Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
第一个 选择年龄
A
1
A_1
A1这个特征
年龄特征中有:青年
A
11
A_{11}
A11,中年
A
12
A_{12}
A12和老年
A
1
3
A_13
A13三个特征值。
| D|A1 | 年龄 | 个数 | 是否同意贷款 | |
| 否 | 是 | |||
| D1 | 青年 | 5 | 3 | 2 |
| D2 | 中年 | 5 | 2 | 3 |
| D3 | 老年 | 5 | 1 | 4 |
1.以青年和非青年分类:
因为CART算法是二叉树,在此我们不妨将数据集分为青年和非青年(也就是中年和老年)。
那么,青年 D 1 D_1 D1的基尼数和权重: G i n i ( D 1 ) = 2 ∗ 2 5 ∗ 3 5 = 12 25 w 1 = 5 15 Gini(D_1)=2*\frac{2}{5}*\frac{3}{5}=\frac{12}{25}\\w_1=\frac{5}{15} Gini(D1)=2∗52∗53=2512w1=155
非青年 D 2 D_2 D2的基尼数和权重: G i n i ( D 2 ) = 2 ∗ 7 10 ∗ 3 10 = 42 100 w 2 = 10 15 Gini(D_2)=2*\frac{7}{10}*\frac{3}{10}=\frac{42}{100}\\w_2=\frac{10}{15} Gini(D2)=2∗107∗103=10042w2=1510
G i n i ( D , A 11 ) = 5 15 ∗ 12 25 + 10 15 ∗ 42 100 = 0.44 Gini(D,A_{11})=\frac{5}{15} *\frac{12}{25}+\frac{10}{15}*\frac{42}{100}=0.44 Gini(D,A11)=155∗2512+1510∗10042=0.44
同理,还可以以中年、老年来作为分类点。
2.以中年和非中年分类:
G i n i ( D , A 12 ) = 5 15 ∗ 2 ∗ 3 5 ∗ 2 5 + 10 15 ∗ 2 ∗ 6 10 ∗ 4 10 = 0.48 Gini(D,A_{12})=\frac{5}{15} *2*\frac{3}{5}*\frac{2}{5}+\frac{10}{15}*2*\frac{6}{10}*\frac{4}{10}=0.48 Gini(D,A12)=155∗2∗53∗52+1510∗2∗106∗104=0.48
3.以老年和非老年分类:
G i n i ( D , A 13 ) = 5 15 ∗ 2 ∗ 4 5 ∗ 1 5 + 10 15 ∗ 2 ∗ 5 10 ∗ 5 10 = 0.44 Gini(D,A_{13})=\frac{5}{15} *2*\frac{4}{5}*\frac{1}{5}+\frac{10}{15}*2*\frac{5}{10}*\frac{5}{10}=0.44 Gini(D,A13)=155∗2∗54∗51+1510∗2∗105∗105=0.44
可以看出,青年和老年的基尼指数最小,都可以作为最优划分点
第二个 选择工作
A
2
A_2
A2这个特征
工作特征中有:有工作
A
21
A_{21}
A21、无工作
A
22
A_{22}
A22 2个特征值。
| D|A2 | 有工作 | 个数 | 是否同意贷款 | |
| 否 | 是 | |||
| D1 | 是 | 5 | 0 | 5 |
| D2 | 否 | 10 | 6 | 4 |
那么,有工作
D
1
D_1
D1的基尼数和权重:
G
i
n
i
(
D
1
)
=
2
∗
0
5
∗
5
5
=
0
w
1
=
5
15
Gini(D_1)=2*\frac{0}{5}*\frac{5}{5}=0 \\ w_1=\frac{5}{15}
Gini(D1)=2∗50∗55=0w1=155
有工作
D
2
D_2
D2的基尼数和权重:
G
i
n
i
(
D
2
)
=
2
∗
4
10
∗
6
10
=
48
100
w
2
=
10
15
Gini(D_2)=2*\frac{4}{10}*\frac{6}{10}=\frac{48}{100}\\w_2=\frac{10}{15}
Gini(D2)=2∗104∗106=10048w2=1510
G i n i ( D , A 2 ) = 5 15 ∗ 0 + 10 15 ∗ 48 100 = 0.32 Gini(D,A_{2})=\frac{5}{15} *0+\frac{10}{15}*\frac{48}{100}=0.32 Gini(D,A2)=155∗0+1510∗10048=0.32
第三个 选择房子
A
3
A_3
A3这个特征
房子特征中有:有房子
A
31
A_{31}
A31、无房子
A
32
A_{32}
A32 2个特征值。
| D|A3 | 有自己的房子 | 个数 | 是否同意贷款 | |
| 否 | 是 | |||
| D1 | 是 | 6 | 0 | 6 |
| D2 | 否 | 9 | 3 | 6 |
那么,有房子
D
1
D_1
D1的基尼数和权重:
G
i
n
i
(
D
1
)
=
2
∗
0
6
∗
6
6
=
0
w
1
=
6
15
Gini(D_1)=2*\frac{0}{6}*\frac{6}{6}=0 \\ w_1=\frac{6}{15}
Gini(D1)=2∗60∗66=0w1=156
有房子
D
2
D_2
D2的基尼数和权重:
G
i
n
i
(
D
2
)
=
2
∗
6
9
∗
3
9
=
36
81
w
2
=
9
15
Gini(D_2)=2*\frac{6}{9}*\frac{3}{9}=\frac{36}{81}\\w_2=\frac{9}{15}
Gini(D2)=2∗96∗93=8136w2=159
G i n i ( D , A 2 ) = 6 15 ∗ 0 + 9 15 ∗ 36 81 = 0.27 Gini(D,A_{2})=\frac{6}{15} *0+\frac{9}{15}*\frac{36}{81}=0.27 Gini(D,A2)=156∗0+159∗8136=0.27
第四个 选择信贷
A
4
A_4
A4这个特征
信贷特征中有:信贷非常好
A
41
A_{41}
A41、信贷好
A
42
A_{42}
A42、信贷一般
A
43
A_{43}
A43 3个特征值。
| D|A4 | 信贷情况 | 个数 | 是否同意贷款 | |
| 否 | 是 | |||
| D1 | 非常好 | 4 | 0 | 4 |
| D2 | 好 | 6 | 2 | 4 |
| D3 | 一般 | 5 | 4 | 4 |
1.以非常好和并不非常好分类:
那么,非常好
D
1
D_1
D1的基尼数和权重:
G
i
n
i
(
D
1
)
=
2
∗
0
4
∗
4
4
=
0
w
1
=
4
15
Gini(D_1)=2*\frac{0}{4}*\frac{4}{4}=0 \\ w_1=\frac{4}{15}
Gini(D1)=2∗40∗44=0w1=154
不非常好
D
2
D_2
D2的基尼数和权重:
G
i
n
i
(
D
2
)
=
2
∗
5
11
∗
6
11
=
48
100
w
2
=
11
15
Gini(D_2)=2*\frac{5}{11}*\frac{6}{11}=\frac{48}{100}\\w_2=\frac{11}{15}
Gini(D2)=2∗115∗116=10048w2=1511
G i n i ( D , A 41 ) = 4 15 ∗ 0 + 11 15 ∗ 60 121 = 0.36 Gini(D,A_{41})=\frac{4}{15} *0+\frac{11}{15}*\frac{60}{121}=0.36 Gini(D,A41)=154∗0+1511∗12160=0.36
2.以好和非好分类
G
i
n
i
(
D
,
A
42
)
=
6
15
∗
2
∗
4
6
∗
2
6
+
9
15
∗
2
∗
5
9
∗
4
9
=
0.47
Gini(D,A_{42})=\frac{6}{15} *2*\frac{4}{6}*\frac{2}{6}+\frac{9}{15}*2*\frac{5}{9}*\frac{4}{9}=0.47
Gini(D,A42)=156∗2∗64∗62+159∗2∗95∗94=0.47
3.以一般和非一般分类
G
i
n
i
(
D
,
A
43
)
=
5
15
∗
2
∗
1
5
∗
4
5
+
10
15
∗
2
∗
8
10
∗
2
10
=
0.32
Gini(D,A_{43})=\frac{5}{15} *2*\frac{1}{5}*\frac{4}{5}+\frac{10}{15}*2*\frac{8}{10}*\frac{2}{10}=0.32
Gini(D,A43)=155∗2∗51∗54+1510∗2∗108∗102=0.32
可以看出,特征值一般的基尼指数最小,作为最优划分点。
把4个特征得出的基尼指数进行比较:
| 特征值 | 基尼指数 |
|---|---|
| 年龄 | 0.44 |
| 工作 | 0.32 |
| 房子 | 0.27 |
| 信贷情况 | 0.32 |
可以看出,特征房子对应的基尼指数最小,那么就可以作为最优特征绘制二叉树。
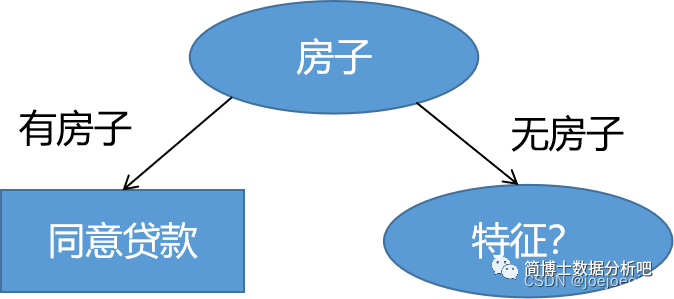
可以看出,有房子的都是同意贷款,那么没房子这里该怎么继续划分,继续对无房子的数据集进行统计,
| ID | 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别 |
|---|---|---|---|---|---|
| 1 | 青年 | 否 | 否 | 一般 | 否 |
| 2 | 青年 | 否 | 否 | 好 | 否 |
| 3 | 青年 | 是 | 否 | 好 | 是 |
| 5 | 青年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 一般 | 否 |
| 7 | 中年 | 否 | 否 | 好 | 否 |
| 13 | 老年 | 是 | 否 | 好 | 是 |
| 14 | 老年 | 是 | 否 | 非常好 | 是 |
| 15 | 老年 | 否 | 否 | 一般 | 否 |
按照年龄、工作、信贷情况来分类,可以得出:
1.在无房子数据集内,以年龄特征分类
| 年龄 | 个数 | 不同意贷款 | 同意贷款 |
|---|---|---|---|
| 青年 | 4 | 3 | 1 |
| 中年 | 2 | 2 | 0 |
| 老年 | 3 | 1 | 2 |
2.在无房子数据集内,以工作特征分类
| 工作 | 个数 | 不同意贷款 | 同意贷款 |
|---|---|---|---|
| 有工作 | 3 | 0 | 3 |
| 无工作 | 6 | 6 | 0 |
3.在无房子数据集内,以信贷情况特征分类
| 信贷情况 | 个数 | 不同意贷款 | 同意贷款 |
|---|---|---|---|
| 非常好 | 1 | 0 | 1 |
| 好 | 4 | 2 | 2 |
| 一般 | 4 | 4 | 0 |
不用分别计算就可以看出工作这个特征对应的分类非常明显,因此对应的基尼指数肯定最小,那么就可以继续选这个特征进行二叉树的分类。
2.6 CART:回归树算法:输出是连续的(回归问题)
1.划分连续数据
既然是决策树,那么输出的一定就是叶子结点,对于 连续变量而言,可以按照一定的要求将连续变量进行划分。
以之前桃子例子来说:
输入:用
[
0
,
0.5
]
[0,0.5]
[0,0.5]来表示由不甜到甜的程度
输出:用
[
1
,
10
]
[1,10]
[1,10]来表示由不好吃到好吃的程度
| 甜度 | 0.05 | 0.15 | 0.25 | 0.35 | 0.45 |
|---|---|---|---|---|---|
| 好吃程度 | 5.5 | 7.6 | 9.5 | 9.7 | 8.2 |
在对数据划分时,就可以从甜度这个输入量来进行划分,但是要注意由于CART算法是二叉树,所以每次划分只能划分成两类,比如:甜度
≤
0.1
\leq 0.1
≤0.1和甜度
>
0.1
> 0.1
>0.1这样两类,然后可以再继续在甜度
>
0.1
> 0.1
>0.1 这个范围内在选择最优切分点继续划分。

右上角的角标数意味着分类的次数,右下角标数代表着所属的类,这就意味着,输出单元最终不只是 2个单元,也可以是多个单元。
2.如何生成回归树模型
假设将输入空间划分成
M
M
M个单元
R
1
,
R
2
,
⋯
,
R
m
R_1,R_2,\cdots,R_m
R1,R2,⋯,Rm,并在每个单元
R
m
R_m
Rm上有一个固定的输出值
c
m
c_m
cm,回归树模型可以表示为:
f
(
x
)
=
∑
m
=
1
M
c
m
I
(
x
∈
R
m
)
f(x)=\sum_{m=1}^Mc_mI(x\in R_m)
f(x)=m=1∑McmI(x∈Rm)
这里的
f
(
x
)
f(x)
f(x)就是CART回归模型,
c
m
c_m
cm代表输出的类,
I
(
x
∈
R
m
)
I(x\in R_m)
I(x∈Rm)是指示性函数。
假设输入和输出变量如下:
| 输入 | R 1 R_1 R1 | R 2 R_2 R2 | … | R m R_m Rm |
|---|---|---|---|---|
| 输出 | c 1 c_1 c1 | c 2 c_2 c2 | … | c m c_m cm |
I ( x ∈ R m ) I(x\in R_m) I(x∈Rm)是指当 x ∈ R m x\in R_m x∈Rm取 1 1 1, x ∉ R m x\notin R_m x∈/Rm取 0 0 0
这样就意味着,对于某个输出单元也就是类 c m c_m cm而言,当输入单元 R m R_m Rm和它一致时就存在,如果不一致时,就没有。这样把所有输入单元对应的类求和之后,便是最终的回归树模型。
3.平方误差和最优输出
怎么找切分点?这时就需要通过平方误差最小化来找到最优切分点了。
选择第
x
(
j
)
x^{(j)}
x(j)个变量和取
s
s
s,分别作为切分变量和切分点,并定义两个区域:
R
1
(
j
,
s
)
=
x
∣
x
(
j
)
≤
s
R
2
(
j
,
s
)
=
x
∣
x
(
j
)
>
s
R_1(j,s)=x|x^{(j)}\leq s \\ R_2(j,s)=x|x^{(j)} > s
R1(j,s)=x∣x(j)≤sR2(j,s)=x∣x(j)>s
用平方误差最小化来寻找最优切分变量
j
j
j和最优切分点
s
s
s:
min
j
,
s
[
m
i
n
c
1
∑
x
i
∈
R
1
(
j
,
s
)
(
y
i
−
c
1
)
2
+
m
i
n
c
2
∑
x
i
∈
R
2
(
j
,
s
)
(
y
i
−
c
2
)
2
]
\min_{j,s}\left[min_{c_1}\sum_{x_i\in R_1(j,s)}(y_i-c_1)^2+min_{c_2}\sum_{x_i\in R_2(j,s)}(y_i-c_2)^2\right]
j,smin
minc1xi∈R1(j,s)∑(yi−c1)2+minc2xi∈R2(j,s)∑(yi−c2)2
这个公式意味着,将输出变量按照输入变量分为了两类,然后要求出来每次分类后的各个分类的平方误差最小值之和,也就意味着整体的最小平方误差,平方误差最小,意味着分类和实际最吻合。其中:
c
^
1
=
a
v
e
(
y
i
∣
x
i
∈
R
1
(
j
,
s
)
)
c
^
2
=
a
v
e
(
y
i
∣
x
i
∈
R
2
(
j
,
s
)
)
\hat c_1=ave (y_i|x_i\in R_1(j,s))\\ \hat c_2=ave (y_i|x_i\in R_2(j,s))
c^1=ave(yi∣xi∈R1(j,s))c^2=ave(yi∣xi∈R2(j,s))
这里可以理解成,如果我们想要平方误差最小,那么就是将每次分类后的和设置为对应的每个区域内的输出变量的平均值。
4.停止条件
可以是将输出变量分为两个类,也可以是直到没有多余的样本点。
输出的就是一棵CART二叉树。
5.例题:桃子例题
| 甜度 | 0.05 | 0.15 | 0.25 | 0.35 | 0.45 |
|---|---|---|---|---|---|
| 好吃程度 | 5.5 | 7.6 | 9.5 | 9.7 | 8.2 |
1.以甜度特征进行回归计算
第一 以甜度
s
=
0.1
s=0.1
s=0.1进行划分
可以将表格里的连续数据划分成
R
1
R_1
R1和
R
2
R_2
R2两类:
R
1
R_1
R1类是:
| 甜度 | 0.05 |
|---|---|
| 好吃程度 | 5.5 |
R 2 R_2 R2类是:
| 甜度 | 0.15 | 0.25 | 0.35 | 0.45 |
|---|---|---|---|---|
| 好吃程度 | 7.6 | 9.5 | 9.7 | 8.2 |
可以得出:
c
^
1
=
5.5
c
^
2
=
7.6
+
9.5
+
9.7
+
8.2
4
=
8.75
\hat c_1=5.5 \\ \hat c_2=\frac{7.6+9.5+9.7+8.2}{4}=8.75
c^1=5.5c^2=47.6+9.5+9.7+8.2=8.75
接着代入平方误差公式中:
= ∑ x i ∈ R 1 ( j , s ) ( y i − c 1 ) 2 + ∑ x i ∈ R 2 ( j , s ) ( y i − c 2 ) 2 = 0 + ( 7.6 − 8.75 ) 2 + ( 9.5 − 8.75 ) 2 + ( 9.7 − 8.75 ) 2 + ( 8.2 − 8.75 ) 2 = 3.09 \begin{aligned}&=\sum_{x_i\in R_1(j,s)}(y_i-c_1)^2+\sum_{x_i\in R_2(j,s)}(y_i-c_2)^2 \\&=0+(7.6-8.75)^2+(9.5-8.75)^2+(9.7-8.75)^2+(8.2-8.75)^2\\&=3.09\end{aligned} =xi∈R1(j,s)∑(yi−c1)2+xi∈R2(j,s)∑(yi−c2)2=0+(7.6−8.75)2+(9.5−8.75)2+(9.7−8.75)2+(8.2−8.75)2=3.09
第二步 以甜度
s
=
0.2
s=0.2
s=0.2进行划分
计算出平方误差和结果为
3.53
3.53
3.53。
第三步 以甜度
s
=
0.3
s=0.3
s=0.3进行划分
计算出平方误差和结果为
9.13
9.13
9.13。
第四步 以甜度
s
=
0.4
s=0.4
s=0.4进行划分
计算出平方误差和结果为
11.52
11.52
11.52。
这样,从四个分类中,我们选取最小值,也就是当甜度
s
1
=
0.1
s_1=0.1
s1=0.1时,作为最优切分点,同时输出的CART回归树模型就是:
f
(
x
)
=
{
5.5
(
s
≤
0.1
)
8.75
(
s
>
0.1
)
f(x)=\begin{cases}5.5 &(s\leq 0.1)\\8.75 &(s > 0.1)\end{cases}
f(x)={5.58.75(s≤0.1)(s>0.1)
当然我们还可以对
s
>
0.1
s>0.1
s>0.1区域进行回归划分,这就要取决于你的停止条件,如果说是继续分成三类,那么就可以按照相同的思路进行计算。
通过对连续变量进行划分,就可以转换为离散的变量来进行计算,那么就和之前的分类树模型也是相通的方法,这也就是为什么常见的都是CART分类树模型。
CART的剪枝
1.损失函数
原理:根据剪枝前后的损失函数来决定是否剪枝,剪枝后,如果损失函数减小,则意味着可以剪枝。
损失函数正是用来度量预测错误程度的指标。
损失函数:
C
α
=
C
(
T
)
+
α
∣
T
∣
C_\alpha = C(T)+\alpha |T|
Cα=C(T)+α∣T∣
第一部分
C
(
T
)
C(T)
C(T)反映的是代价,是对训练数据的预测误差(比如基尼指数),也就是模型的拟合能力
第二部分
∣
T
∣
|T|
∣T∣反映的是模型的复杂度,体现的是泛化能力,
∣
T
∣
|T|
∣T∣表示子树上叶子结点的个数,叶子结点越多,模型越复杂。
α
\alpha
α是一个决定拟合和泛化综合效果的参数。
当
α
=
0
\alpha=0
α=0时,模型仅由拟合决定,不考虑对未知数据的预测能力,所以这样得到是一棵最完整的决策树,泛化能力弱。
当
α
=
+
∞
\alpha=+\infty
α=+∞时,得到的是单结点树,对于任何数据的泛化能力很强,但拟合效果差。
如何选取
α
\alpha
α至关重要。
2. α \alpha α的取值
可以将
α
\alpha
α从
0
∼
+
∞
0\sim+\infty
0∼+∞划分成多个小区间,比如:
0
≤
α
0
<
α
1
<
⋯
<
α
n
<
α
n
+
1
<
+
∞
0\leq \alpha_0<\alpha_1<\cdots<\alpha_n<\alpha_{n+1}<+\infty
0≤α0<α1<⋯<αn<αn+1<+∞
这时,每一个
α
\alpha
α就对应着一棵决策树。接着,我们把这些
α
\alpha
α按照左闭右开的形式划成小区间。比如:
[
α
1
,
α
2
)
,
[
α
2
,
α
3
)
,
⋯
,
[
α
n
,
α
n
+
1
)
,
[\alpha_1,\alpha_2),[\alpha_2,\alpha_3),\cdots,[\alpha_n,\alpha_{n+1}),
[α1,α2),[α2,α3),⋯,[αn,αn+1),
总共有
n
n
n个区间,每个小区间都对应着一个决策树,我们可以记成:
T
0
,
T
1
,
T
2
,
⋯
,
T
n
T_0,T_1,T_2,\cdots,T_n
T0,T1,T2,⋯,Tn
这里
T
0
T_0
T0就代表了
α
=
0
\alpha=0
α=0时的完整的决策树,意味着没有剪枝。
接着,就是要从这些决策树里,找到最优的决策树。
假设现在我们有这么一棵子树,叫做
T
t
T_t
Tt
那么剪枝前的损失函数可以写成:
C
α
(
T
t
)
=
C
(
T
t
)
+
α
∣
T
t
∣
C_\alpha(T_t)=C(T_t)+\alpha|T_t|
Cα(Tt)=C(Tt)+α∣Tt∣
剪枝后变成了一个叶子结点,也就意味着此时
∣
T
∣
=
1
|T|=1
∣T∣=1,那么损失函数可以写成:
C
α
(
T
t
)
=
C
(
T
t
)
+
α
C_\alpha(T_t)=C(T_t)+\alpha
Cα(Tt)=C(Tt)+α
接着,我们可以假设
α
\alpha
α从
0
0
0开始逐渐变大到
+
∞
+\infty
+∞,意味着从高度拟合到高度泛化的变化趋势,可以得出在高度拟合和高度泛化时,所对应的损失函数都是非常大的。
而在这变化过程中,意味着剪枝前和剪枝后的会有一个临界值
α
\alpha
α,在这个临界值处,拟合和泛化的损失函数为最小。
这个值就可以联立两个方程求解出来:
α
=
C
(
t
)
−
C
(
T
t
)
∣
T
t
∣
−
1
\alpha=\frac{C(t)-C(T_t)}{|T_t|-1}
α=∣Tt∣−1C(t)−C(Tt)
3.算法解读
输入:CART算法生成的完整决策树
输出:最优决策树
T
α
T_\alpha
Tα。
第一步,设
k
=
0
,
T
=
T
0
k=0,T=T_0
k=0,T=T0也就是从完整的决策树出发。
k
k
k代表的是迭代的次数,这里从0开始,也就意味着还没开始迭代,那么树也是完整的,从这里开始出发。
第二步,设
α
=
+
∞
\alpha=+\infty
α=+∞因为后面我们要比较大小,当损失函数小的时候可以剪枝。
相当于由大至小开始比较。
第三步,自下而上的对各内部结点
t
t
t计算
C
(
T
t
)
,
∣
T
t
∣
C(T_t),|T_t|
C(Tt),∣Tt∣,以及
g
(
t
)
=
C
(
t
)
−
C
(
T
t
)
∣
T
t
∣
−
1
,
α
=
m
i
n
(
α
,
g
(
t
)
)
g(t)=\frac{C(t)-C(T_t)}{|T_t|-1},\alpha=min(\alpha,g(t))
g(t)=∣Tt∣−1C(t)−C(Tt),α=min(α,g(t))
这里的
g
(
t
)
g(t)
g(t)代表了在这个结点对应的
α
\alpha
α值,
C
(
t
)
C(t)
C(t)代表了单结点时的预测误差,
C
(
T
t
)
C(T_t)
C(Tt)代表了子数时的预测误差。
注意:此处的预测误差与我们之前所介绍的预测错误率不同,它还可以包括平方损失、基尼指数等。
第四步,自上而下访问内部结点 t t t,如果有 g ( t ) = α g(t)=\alpha g(t)=α ,则进行剪枝,并对叶结点 t t t 以多数表决法决定类,得到树 T T T 。
4.剪枝的例题

第一二步
设
k
=
0
,
T
=
T
0
k=0,T=T_0
k=0,T=T0也就是从完整的决策树出发,设置
α
=
+
∞
\alpha=+\infty
α=+∞
从这棵决策树上,我们可以看出有3个内部结点,分别是
T
0
,
T
1
,
T
2
T_0,T_1,T_2
T0,T1,T2,对应的叶子结点有4个。其中绿色表示正类,红色表示负类。
第三四步
g
(
t
)
=
C
(
t
)
−
C
(
T
t
)
∣
T
t
∣
−
1
,
α
=
m
i
n
(
α
,
g
(
t
)
)
g(t)=\frac{C(t)-C(T_t)}{|T_t|-1},\alpha=min(\alpha,g(t))
g(t)=∣Tt∣−1C(t)−C(Tt),α=min(α,g(t))
第一轮,因为内部结点3个,我们可以把
T
0
,
T
1
,
T
2
T_0,T_1,T_2
T0,T1,T2分别对应为
t
=
0
,
t
=
1
,
t
=
2
t=0,t=1,t=2
t=0,t=1,t=2,对于
C
(
t
)
C(t)
C(t)代表了单结点时的预测误差,这里因为我们选用的是预测错误率来计算。
对于
T
0
T_0
T0子树而言,一共有17个样本点,其中8个正类,9个负类,如果按照多数表决法来设置单结点的话,那么应该设为负类,这样误判的个数就为8,同时还要乘以这棵子树中样本点占总体的权重。因此:
C
(
0
)
=
17
17
∗
8
17
=
8
17
C(0)=\frac{17}{17}*\frac{8}{17}=\frac{8}{17}
C(0)=1717∗178=178
接着求
C
(
T
0
)
C(T_0)
C(T0),可以看出在
T
0
T_0
T0子树中,对应的4个叶子结点里,只有从左数第2个结点有1个误判。因此:
C
(
T
0
)
=
1
17
C(T_0)=\frac{1}{17}
C(T0)=171
代入计算:
g
(
0
)
=
C
(
0
)
−
C
(
T
0
)
∣
T
0
∣
−
1
=
8
17
−
1
17
4
−
1
=
7
51
g(0)=\frac{C(0)-C(T_0)}{|T_0|-1}=\frac{\frac{8}{17}-\frac{1}{17}}{4-1}=\frac{7}{51}
g(0)=∣T0∣−1C(0)−C(T0)=4−1178−171=517
取:
α
=
m
i
n
(
α
,
g
(
0
)
)
=
m
i
n
(
+
∞
,
7
51
)
=
7
51
\alpha=min(\alpha,g(0))=min(+\infty,\frac{7}{51})=\frac{7}{51}
α=min(α,g(0))=min(+∞,517)=517
对于 T 1 T_1 T1子树而言,一共有9个样本点,其中7个正类,2个负类,如果按照多数表决法来设置单结点的话,那么应该设为正类,这样误判的个数就为2,同时还要乘以这棵子树中样本点占总体的权重。因此: C ( 1 ) = 9 17 ∗ 2 9 = 2 17 C(1)=\frac{9}{17}*\frac{2}{9}=\frac{2}{17} C(1)=179∗92=172
接着求
C
(
T
1
)
C(T_1)
C(T1),可以看出在
T
1
T_1
T1子树中,没有误判。因此:
C
(
T
1
)
=
0
C(T_1)=0
C(T1)=0
代入计算:
g
(
1
)
=
C
(
1
)
−
C
(
T
1
)
∣
T
1
∣
−
1
=
2
17
−
0
3
−
1
=
1
17
g(1)=\frac{C(1)-C(T_1)}{|T_1|-1}=\frac{\frac{2}{17}-0}{3-1}=\frac{1}{17}
g(1)=∣T1∣−1C(1)−C(T1)=3−1172−0=171
取:
α
=
m
i
n
(
α
,
g
(
1
)
)
=
m
i
n
(
7
51
,
1
17
)
=
1
17
\alpha=min(\alpha,g(1))=min(\frac{7}{51},\frac{1}{17})=\frac{1}{17}
α=min(α,g(1))=min(517,171)=171
对于 T 2 T_2 T2子树而言,一共有8个样本点,其中7个正类,1个负类,如果按照多数表决法来设置单结点的话,那么应该设为正类,这样误判的个数就为1,同时还要乘以这棵子树中样本点占总体的权重。因此: C ( 1 ) = 8 17 ∗ 1 98 = 1 17 C(1)=\frac{8}{17}*\frac{1}{98}=\frac{1}{17} C(1)=178∗981=171
接着求
C
(
T
2
)
C(T_2)
C(T2),可以看出在
T
2
T_2
T2子树中,没有误判。因此:
C
(
T
2
)
=
0
C(T_2)=0
C(T2)=0
代入计算:
g
(
2
)
=
C
(
2
)
−
C
(
T
2
)
∣
T
2
∣
−
1
=
1
17
−
0
2
−
1
=
1
17
g(2)=\frac{C(2)-C(T_2)}{|T_2|-1}=\frac{\frac{1}{17}-0}{2-1}=\frac{1}{17}
g(2)=∣T2∣−1C(2)−C(T2)=2−1171−0=171
取:
α
=
m
i
n
(
α
,
g
(
2
)
)
=
m
i
n
(
1
51
,
1
17
)
=
1
17
\alpha=min(\alpha,g(2))=min(\frac{1}{51},\frac{1}{17})=\frac{1}{17}
α=min(α,g(2))=min(511,171)=171
可以看出
g
(
2
)
=
g
(
1
)
=
α
=
1
17
g(2)=g(1)=\alpha=\frac{1}{17}
g(2)=g(1)=α=171, ,因此不妨对内部结点
T
2
T_2
T2子树剪枝。
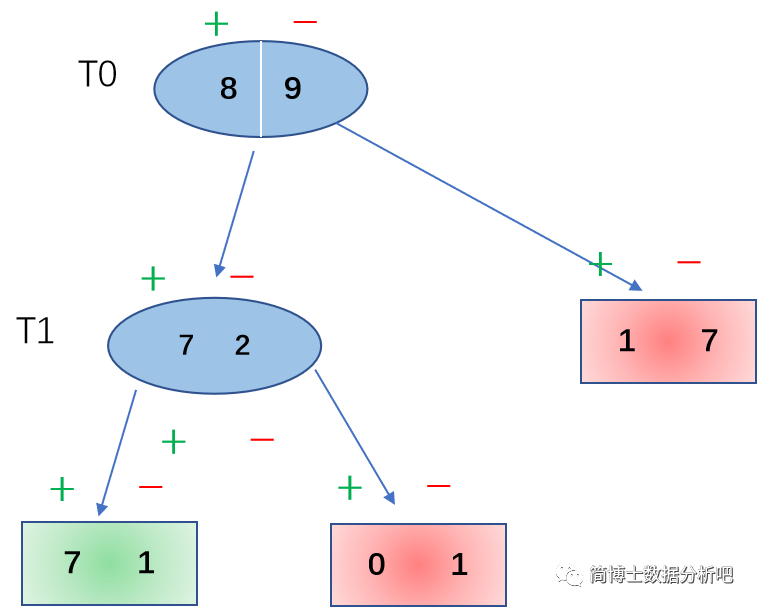
第二轮,按照上面的思路继续对
T
0
T_0
T0和
T
1
T_1
T1内部结点进行迭代计算。
对于
T
0
T_0
T0子树而言,一共有17个样本点,其中8个正类,9个负类,如果按照多数表决法来设置单结点的话,那么应该设为负类,这样误判的个数就为8,同时还要乘以这棵子树中样本点占总体的权重。因此:
C
(
0
)
=
17
17
∗
8
17
=
8
17
C(0)=\frac{17}{17}*\frac{8}{17}=\frac{8}{17}
C(0)=1717∗178=178
接着求
C
(
T
0
)
C(T_0)
C(T0),可以看出在
T
0
T_0
T0子树中,对应的3个叶子结点里,有2个误判。因此:
C
(
T
0
)
=
2
17
C(T_0)=\frac{2}{17}
C(T0)=172
代入计算:
g
(
0
)
=
C
(
0
)
−
C
(
T
0
)
∣
T
0
∣
−
1
=
8
17
−
2
17
3
−
1
=
3
17
g(0)=\frac{C(0)-C(T_0)}{|T_0|-1}=\frac{\frac{8}{17}-\frac{2}{17}}{3-1}=\frac{3}{17}
g(0)=∣T0∣−1C(0)−C(T0)=3−1178−172=173
取:
α
=
m
i
n
(
α
,
g
(
0
)
)
=
m
i
n
(
1
17
,
3
17
)
=
1
17
\alpha=min(\alpha,g(0))=min(\frac{1}{17},\frac{3}{17})=\frac{1}{17}
α=min(α,g(0))=min(171,173)=171
注意:在第2轮中,此时要比较的
α
\alpha
α是第一轮中的结果,也就是
1
17
\frac{1}{17}
171
对于 T 1 T_1 T1子树而言,一共有9个样本点,其中7个正类,2个负类,如果按照多数表决法来设置单结点的话,那么应该设为正类,这样误判的个数就为2,同时还要乘以这棵子树中样本点占总体的权重。因此: C ( 1 ) = 9 17 ∗ 2 9 = 2 17 C(1)=\frac{9}{17}*\frac{2}{9}=\frac{2}{17} C(1)=179∗92=172
接着求
C
(
T
1
)
C(T_1)
C(T1),可以看出在
T
1
T_1
T1子树中,由于第一个叶结点属于正类,有1个误判。因此:
C
(
T
1
)
=
1
17
C(T_1)=\frac{1}{17}
C(T1)=171
代入计算:
g
(
1
)
=
C
(
1
)
−
C
(
T
1
)
∣
T
1
∣
−
1
=
2
17
−
1
17
2
−
1
=
1
17
g(1)=\frac{C(1)-C(T_1)}{|T_1|-1}=\frac{\frac{2}{17}-\frac{1}{17}}{2-1}=\frac{1}{17}
g(1)=∣T1∣−1C(1)−C(T1)=2−1172−171=171
取:
α
=
m
i
n
(
α
,
g
(
1
)
)
=
m
i
n
(
1
17
,
1
17
)
=
1
17
\alpha=min(\alpha,g(1))=min(\frac{1}{17},\frac{1}{17})=\frac{1}{17}
α=min(α,g(1))=min(171,171)=171
可以看出,这里的
T
1
T_1
T1子树对应的
α
\alpha
α是最小值,意味着对
T
1
T_1
T1剪枝。
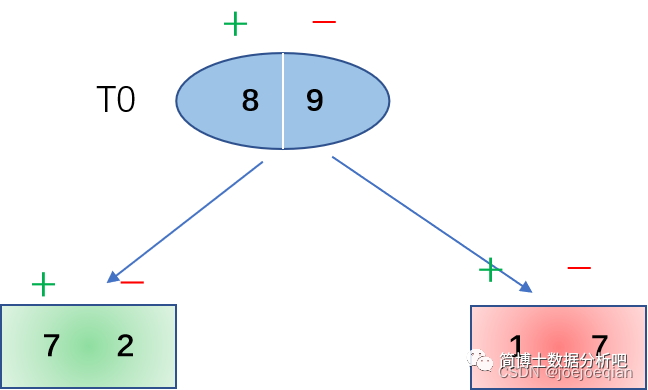
第三轮
按照上面的思路继续对
T
0
T_0
T0结点进行迭代计算。
对于 T 0 T_0 T0子树而言,一共有17个样本点,其中8个正类,9个负类,如果按照多数表决法来设置单结点的话,那么应该设为负类,这样误判的个数就为8,同时还要乘以这棵子树中样本点占总体的权重。因此: C ( 0 ) = 17 17 ∗ 8 17 = 8 17 C(0)=\frac{17}{17}*\frac{8}{17}=\frac{8}{17} C(0)=1717∗178=178
接着求
C
(
T
0
)
C(T_0)
C(T0),可以看出在
T
0
T_0
T0子树中,对应的2个叶子结点里,由于这里拿正类单结点替代了左边,那么误判个数就变成了3个。因此:
C
(
T
0
)
=
3
17
C(T_0)=\frac{3}{17}
C(T0)=173
代入计算:
g
(
0
)
=
C
(
0
)
−
C
(
T
0
)
∣
T
0
∣
−
1
=
8
17
−
3
17
2
−
1
=
5
17
g(0)=\frac{C(0)-C(T_0)}{|T_0|-1}=\frac{\frac{8}{17}-\frac{3}{17}}{2-1}=\frac{5}{17}
g(0)=∣T0∣−1C(0)−C(T0)=2−1178−173=175
取:
α
=
m
i
n
(
α
,
g
(
0
)
)
=
m
i
n
(
1
17
,
3
17
)
=
1
17
\alpha=min(\alpha,g(0))=min(\frac{1}{17},\frac{3}{17})=\frac{1}{17}
α=min(α,g(0))=min(171,173)=171
这里就可以看出,
T
0
T_0
T0子树对应的不是最小
α
\alpha
α,因此不剪枝。同时,根节点满足了两个叶子结点的停止条件,剪枝结束。
当然,对于树形结构比较复杂的决策树而言,可以继续增加迭代次数,最终采用交叉验证法将原始的决策树和每轮生成的Tree1、Tree2…等决策树中选取最优树形。
总结
| 算法 | 支持模型 | 树结构 | 特征选择 | 连续值处理 | 缺失值处理 | 剪枝 |
|---|---|---|---|---|---|---|
| ID3 | 分类 | 多叉树 | 信息增益 | 不支持 | 不支持 | 不支持 |
| C4.5 | 分类 | 多叉树 | 信息增益比 | 支持 | 支持 | 支持 |
| CART | 分类,回归 | 二叉树 | 基尼系数,均方差 | 支持 | 支持 | 支持 |

















 2214
2214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









