



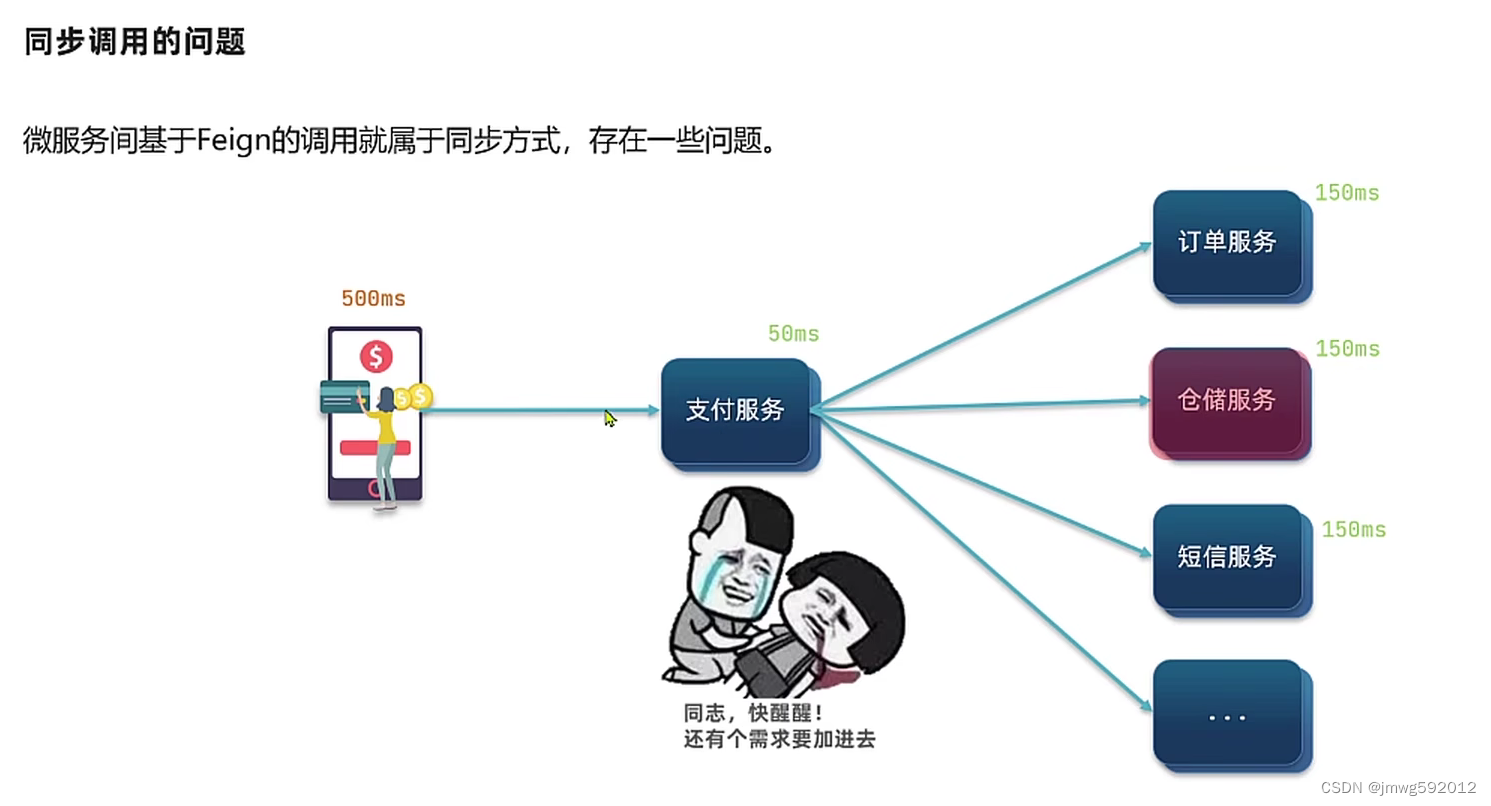
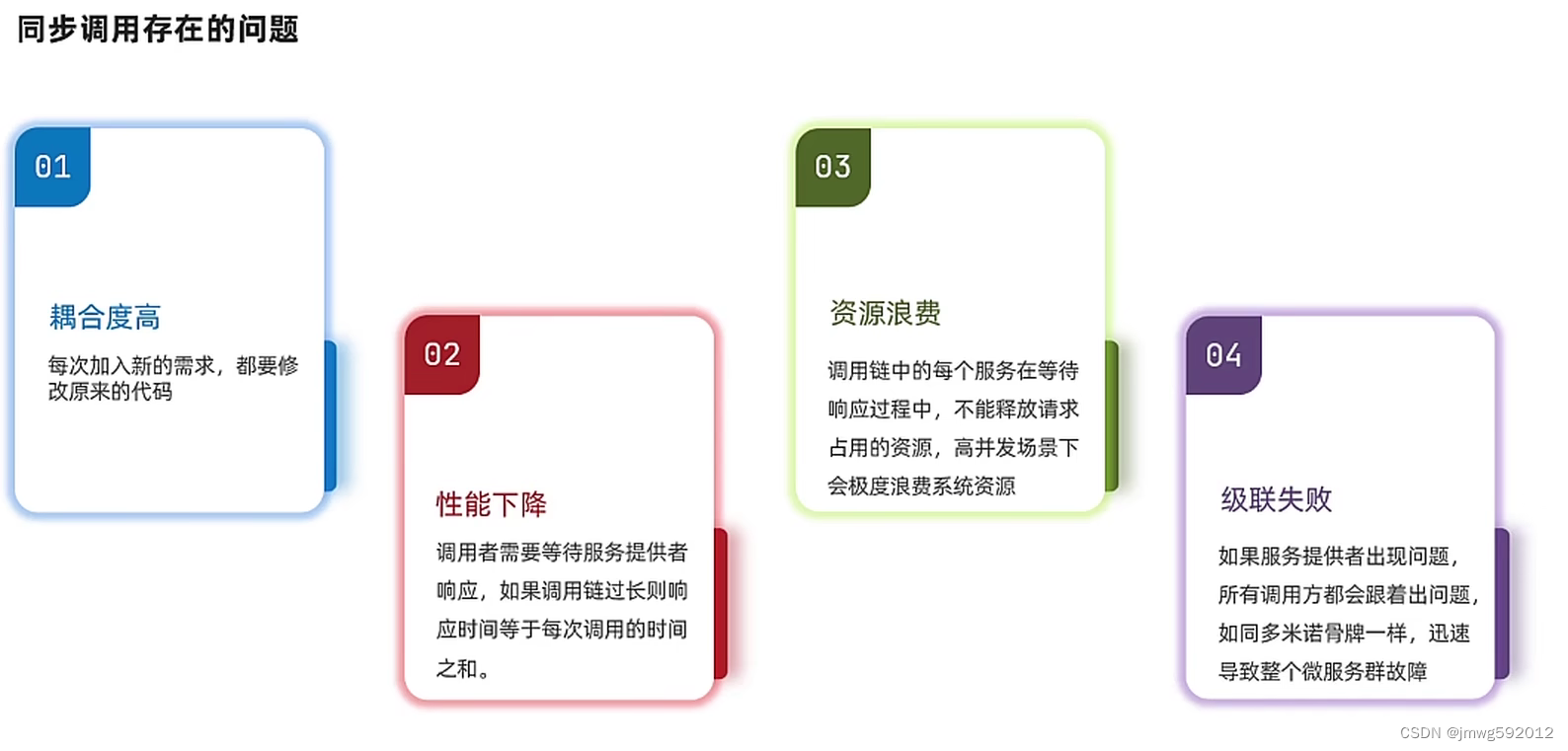
同步通讯的问题:
微服务间基于feign的调用就是同步调用,必须等待,吞吐量不高、新增需求就得原来的代码、
异步调用:事件驱动

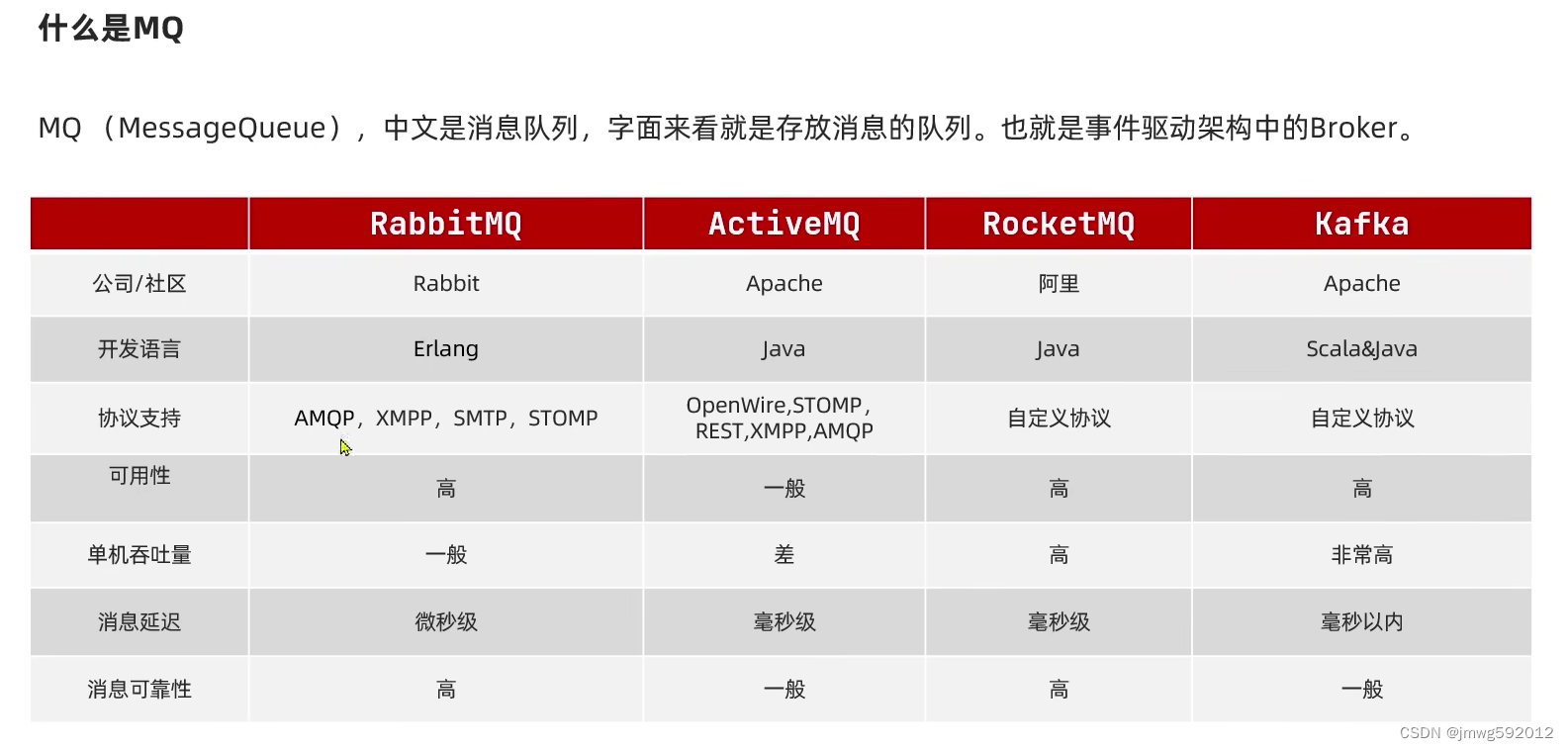
什么是mq(消息队列)
rabbitMQ、kafka、rocketMQ、ActiveMQ

简单消息队列demo步骤

AMQP
AMQP(Advanced Message Queuing Protocol)是一种网络协议,用于在应用程序之间进行异步消息通信。它提供了一种可靠的、异步的方式来发送和接收消息,以及管理消息队列。
SpringAMQP:
发送、接受步骤
引入依赖、配置rabbitMQ的地址和各种信息;
发送方:利用RabbitTemplate发送消息
接受方:利用注解@RabbitListener接受消息
work模型:
通过设置prefetch控制消费者预取的数量,同一个消息只能被一个消费者消费

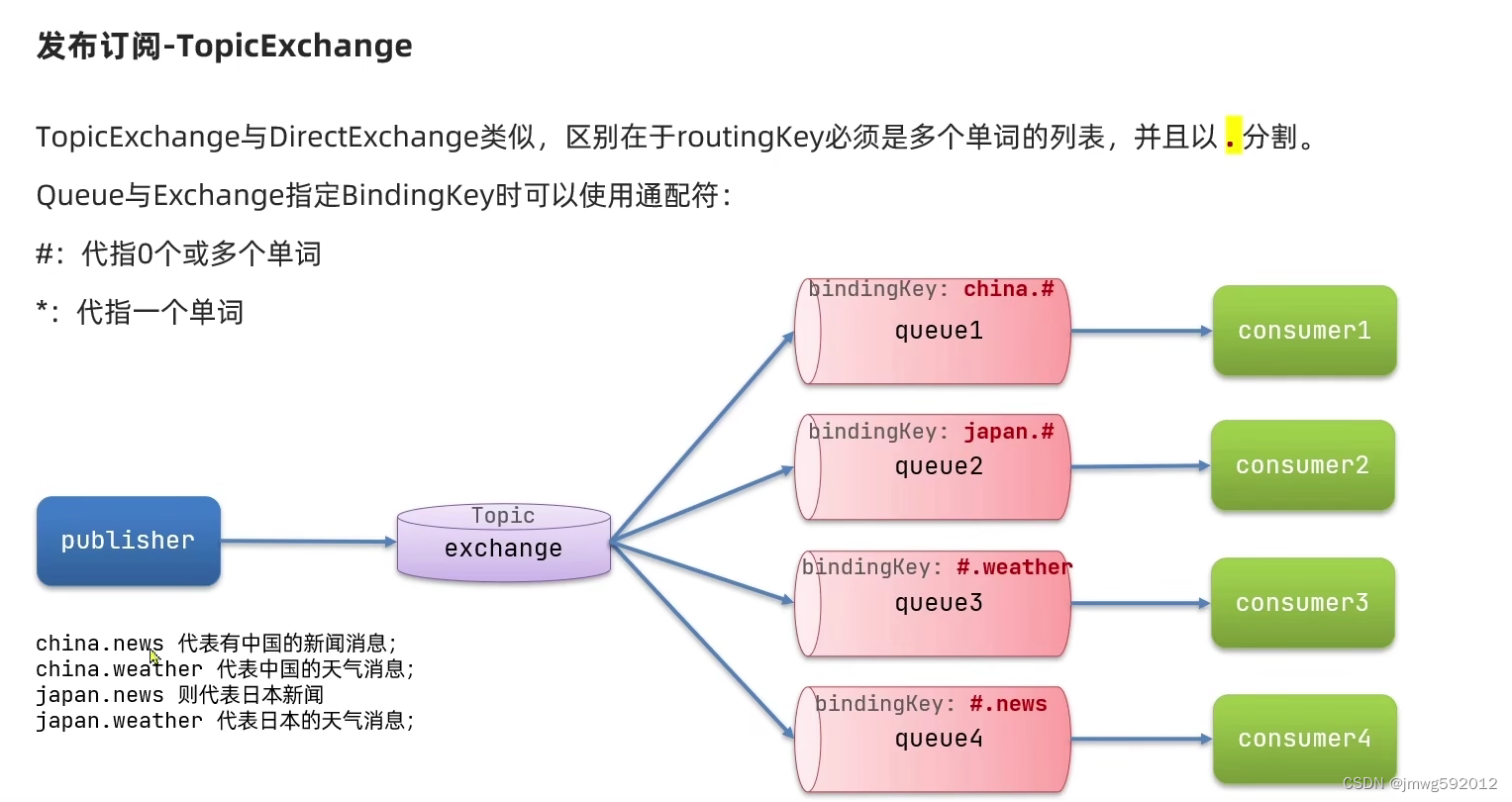
发布订阅模型:
一个消息能被多个消费者共同消费
发布者------》交换机-----》队列------》消费者
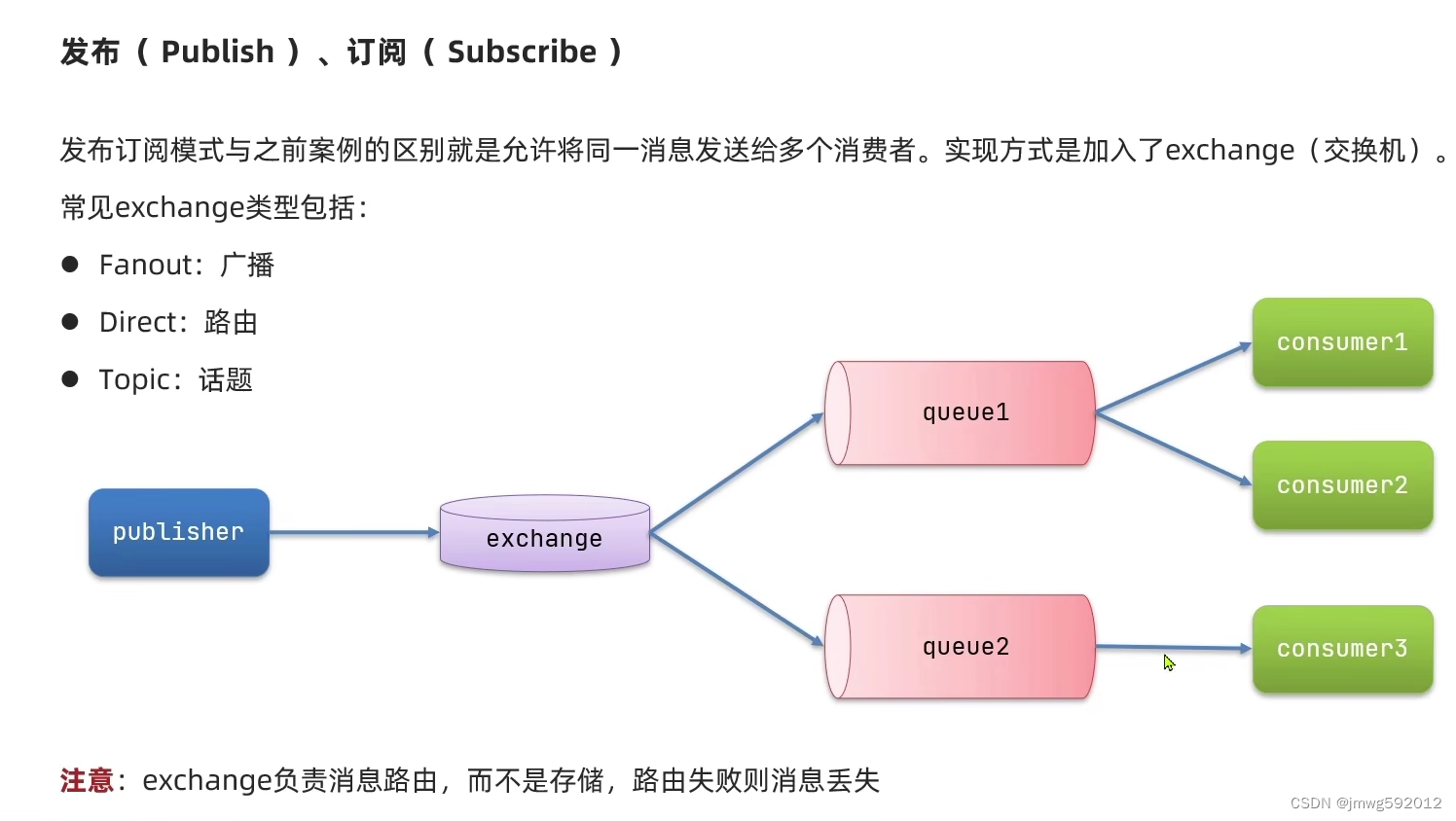
FanoutExchange
DirectExchange

TopicExchange
消息转换器
springAMQP底层使用的是jdk的序列化和反序列化,可以覆盖替换
使用Jackson2Json

MQ高级
生产者可靠性
生产者重连机制:有的时候由于网络波动,可能会出现客户端连接MQ失败的情况。通过配置我们可以开启连接失败后的重连机制:

但是SpringAMQP提供的重试机制是阻塞式的重试,会影响业务性能。
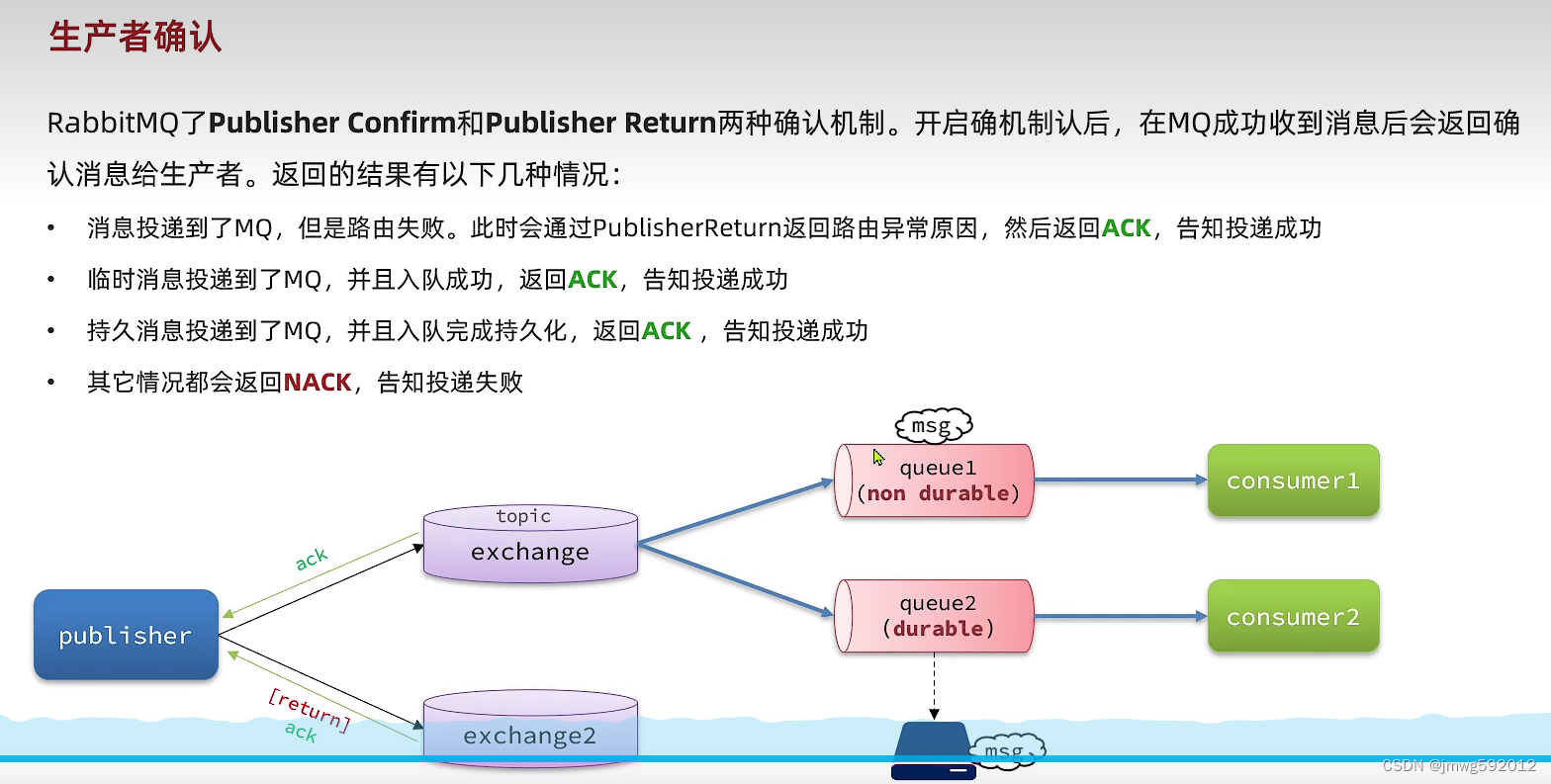
生产者确认:
三种ACK;1、消息投递到了MQ,但是路由失败,通过publisherReturn返回路由异常原因,然后返回ACK;2、临时消息投递到了MQ,并且入队成功,返回ACK;3、持久消息投递到了MQ,并且入队完成持久化,返回ACK

MQ可靠性
在默认情况下,rabbitMq会将接收到的信息保存在内存中以降低消息收发的延迟。
一旦MQ宕机,内存中的消息会丢失;内存空间有限,当消费者故障或处理过慢,会导致消息积压,引发Mq阻塞。
数据持久化
消息分为持久化消息和非持久化消息,非持久化在内存中堆积多了就会发生pageOut阻塞将消息写入内存中,不太友好。
lazy queue
直接先将消息写入磁盘,之后再读取,但是非常快速,因为IO做了优化。
内存中的消息数量也有限制。

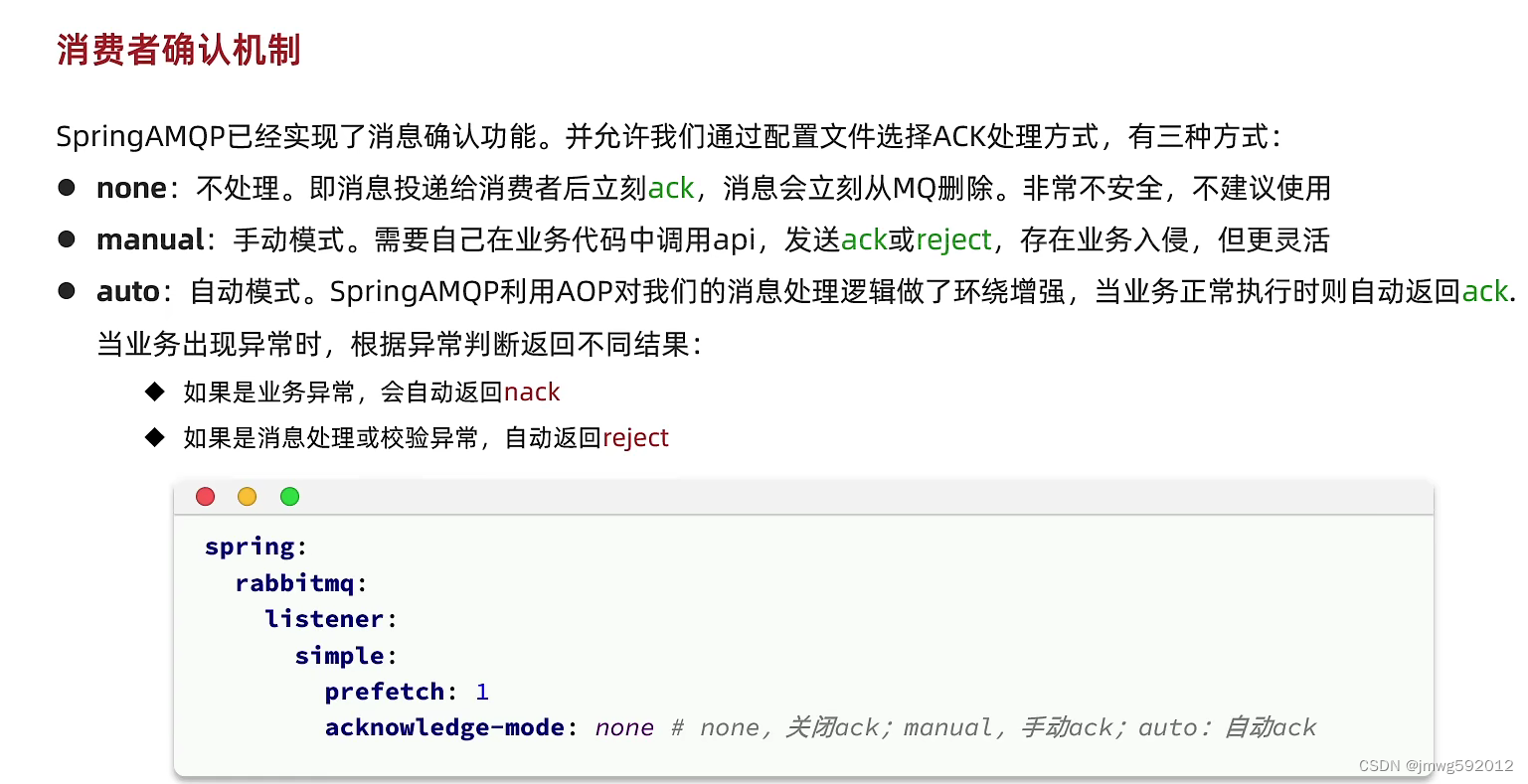
消费者可靠性
消费者确认机制
一般就是配置的spring自动模式
消费失败处理机制
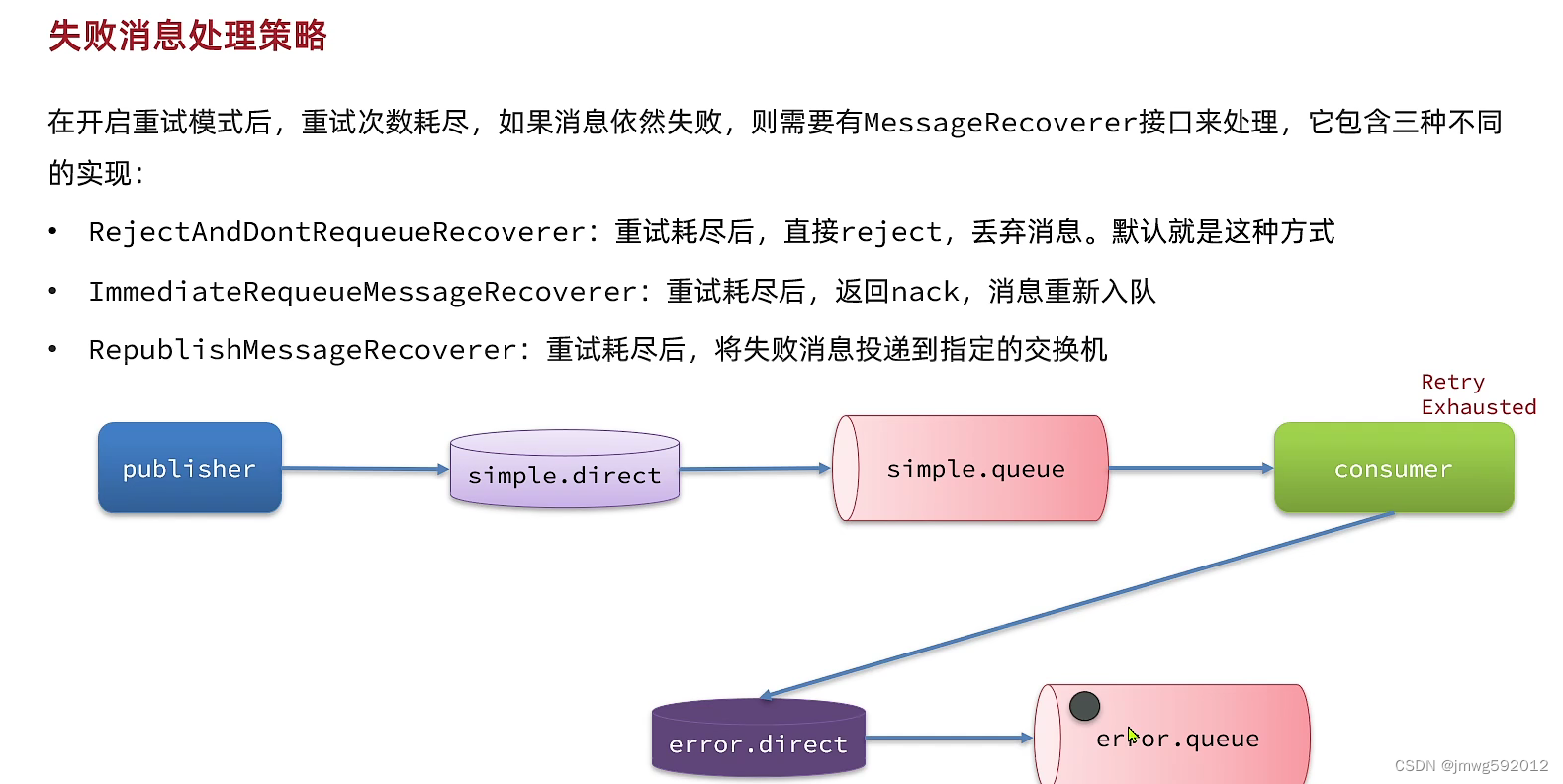
失败重试机制

重试次数耗尽的消息的处理策略:
1.直接删除,默认
2.立即入队
3.将失败消息重新投递到指定交换机

业务幂等性
是指有一些操作重复执行几遍业务最终结果也是一致的。
比如查询操作、删除操作;
需要保证业务的幂等性
可以给每一条消息增添唯一ID,等消息成功处理后,将消息ID存储数据库,等到下次消息过来时判断ID是否已经存在于数据库中。
上面这种方式比较依赖性能,消耗资源;
也可以在业务中保证幂等性,比如修改状态时,要先判断是否是需要修改的状态再进行下一步操作
总结

消息延迟
什么是延迟消息
一个消息发送后,消费者不能立刻收到消息,而是在指定时间过后才能收到消息,延迟任务
死信交换机
延迟消息插件
定时任务,一般是在内存维护一个时钟,属于cpu密集型
kafka
kafaka快速入门
MQ系统:将一个系统(生产者)的消息发送到MQ中进行排队,然后发动另外一个系统(消费者)进行消费的系统
异步、解耦、消峰
kafka的设计目标是高吞吐、低延迟和可扩张,主要关注消息传递而不是消息处理。所以,并没有支持死信队列、顺序消息等高级功能。
集群容错性高稳定性要求高于数据安全性要求,即可以丢失一些数据但是不能使服务不可用。
注意
分组消费
同一个消息可以被不同消费者组重复消费,但是一个消息在一个消费者组内只能被消费一次
kafka的存储消息的offset存储在服务端,但是offset的推进由客户端来实现(consumer.comit),如果通过consumer.poll()来拉取消息后没有做提交处理,那么kafka服务端的offset不会更新,同一个消费组的不同消费者也能消费到这些消息。
- 在一个消费者组内,一个分区在同一时刻只能被一个消费者消费。
- 一个消费者可以消费一个或多个分区,这取决于消费者组的成员数量和分区的数量。
- 当消费者组的成员数量少于分区数量时,会有消费者消费多个分区。
- 当消费者组的成员数量多于分区数量时,会有消费者处于空闲状态,没有分区消费。
- 不同的消费者组可以消费同一个主题下的同一个分区。这意味着同一个消息可以被不同的消费者组重复消费。
如果kafka服务端没有记录offset可以通过设置auto_offset_reset来控制读取消息的开始位置,earliest、latest、none、anything else等
offset管理
因为offset在服务端管理的话客户端非常被动,所以可以将每个partion分区的offset存储在redis等第三方工具中,进行更新管理,如果读取到的消息offset<=redis中的offset那么这个消息就是已经消费过的消息,可以实现消息的幂等性
消息路由
生产者发送消息到partition
partitioner_class_config设置
默认是没有配置的此时如果,消息带有key的话,相同key发送到一个partition中,如果没有携带key的话都发送到一个partition分区中知道,大小达到了BATCH_SIZE_CONFIG
还有轮询、自定义
顺序消费
- 设置发送的路由,把需要顺序消费的消息都发送到一个partition中
消费者绑定partition消费
partition_assignmment_stratengy_config
- range:一个topic下有10个partition(0-9)一个消费者组下有三个Consumer。range策略就会将0-3、4-6、7-9,这样分
- round-robin:轮询分配策略会0-3-6-9;1-4-7;2-5-8这样分
- sticky:粘性策略。在开始分区时,尽量保持分区的分配均匀;分区的分配尽可能的和 分配的保持一致。比如在range分区的情况下,第三个Consumer的服务宕机了,那么按照stikcy策略,就会保持 其他两个原有的分区分配情况。然后将宕机的7-9分区尽量平均的分配到另外两个consumer上。保持数据稳定性。
- 自定义
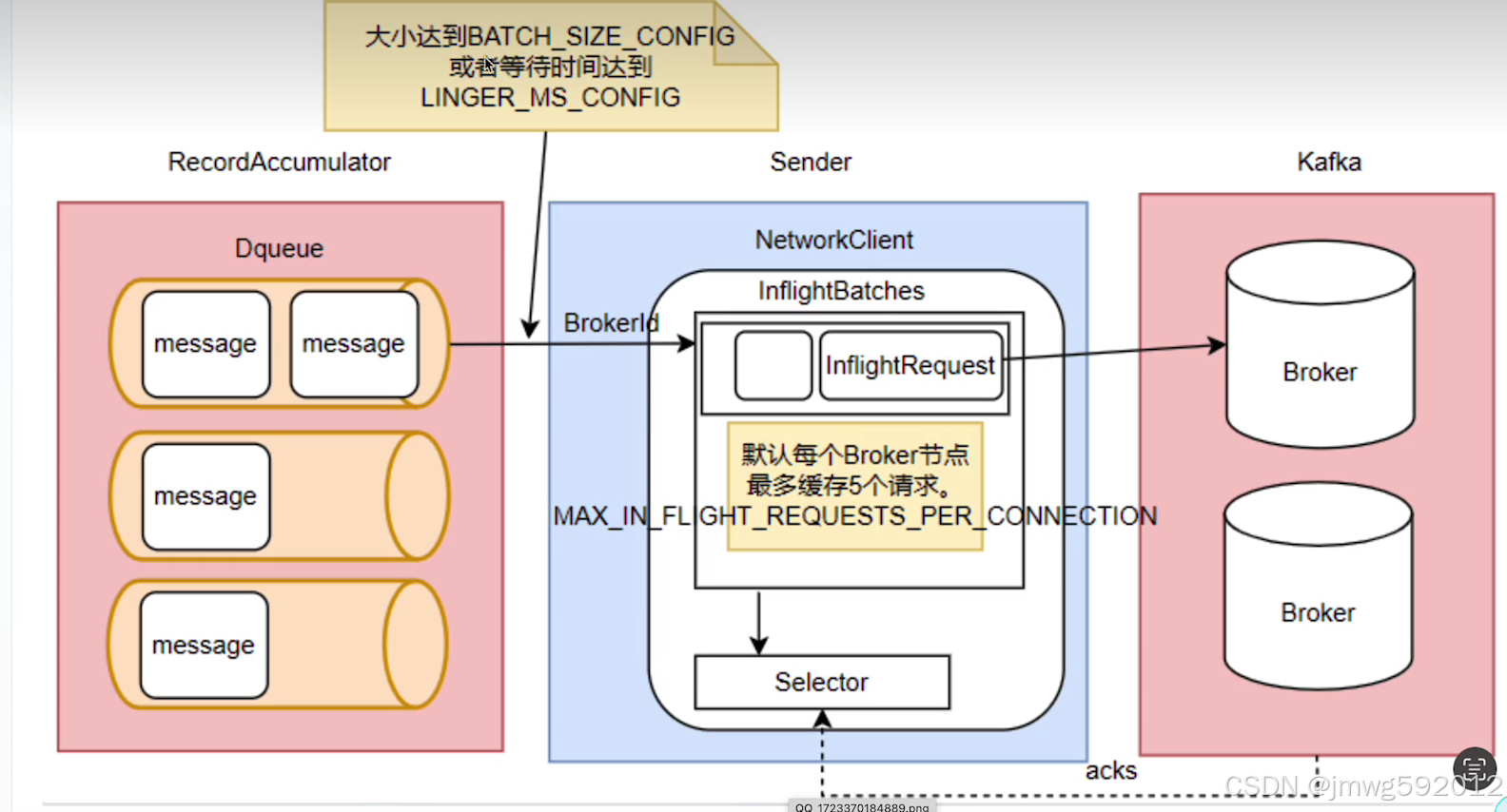
生产者缓存机制
生产者发送消息会先发送(存储)到本地的accmulator对象(一个deque)中,启动sender对象,等消息大小到达Batch_size_config在发送。其中deque就和消费者关联。
发送消息也不是一次性发送而是有一个inflightBatches缓存消息,然后再一批次发送,等待应答
生产者应答机制
客户端进行设置,ACK_CONFIG=====>由客户端来确定是否开启应答机制。
ack_config=0:客户端不会关心消息是否发送成功,发送一次即可。吞吐量最高,安全性最低。
ack_config=1:只需要等到kafka集群中的leader的应答即可。数据一致性不太好
ack_config=all: 必须等到集群中的所有结点的应答才可。网络消费较高。
还有介于1和all之间的:min.insycn.replicas 即不需要等多所有结点的应答.
生产者消息幂等性
分布式数据传递过程中的三个数据语义:
- at-least-once:至少一次,可以保证数据不丢失,但是又不能保证数据不重复;(我存钱)
- at-most-once:最多一次,保证数据不重复,但是又不能保证数据不丢失; (银行收钱)
- exactly-once:精确一次,
Kafka为了保证消息的发送的Exactly-once语义,增加了几个概念:
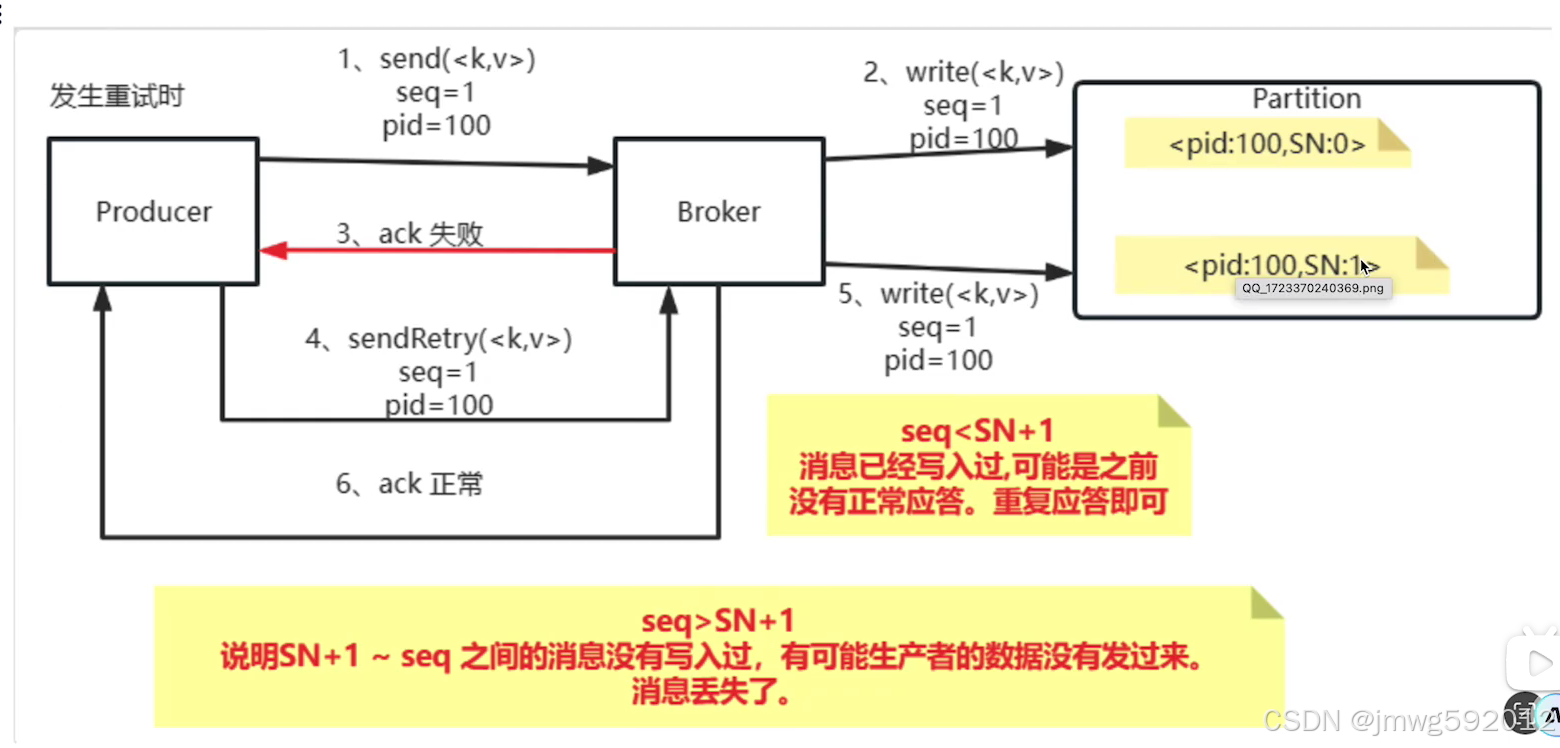
PID:每个新的Producer在初始化的过程中国会被分配一个唯一的PID。这个pid对用户是不可见的
Sequence Number: 对于每个pid,这个producer会针对partition维护一个sequenceNumber。这是一个从0开始单调递增的数字。当producer要往同一个partiton发送消息时,这个sequenceNumber就会+1.然后随着消息一起发往Broker。
Broker端则会针对每个<PID,Partition>维护一个序列号(SN),只有对应的SequenceNumber = SN+1时,Broker才会接受消息,同时将SN更新为SN+1。否则,SequenceNumber过小就会认为消息已经写入了,不需要重复写入。而如果sequenceNumber过大,就会认为中间可能有数据丢失了。对生产者就会抛出一个OutOfOrderSequenceNumber。
生产者消息压缩机制
当生产者往Broker发送消息时,还会对每个消息进行压缩,从而降低Producer到Broker的网络数据传输压力,同时也降低了Broker的数据存储压力。COMPRESSION_TYPE_CONFIG参数
消息事务机制
通过生产者消息幂等性问题,能够解决单生产者消息写入单分区的幂等性问题。但是,如果是要写入多个分区呢?比如生产者一次性发送多条消息,然后给不同的笑嘻嘻指定不同的key。这批消息就有可能写入多个Partition,而这些Partition是分布在不同Broker上的。这意味着,Producer需要对多个Broker同时保证消息的幂等性。
Kafka的事务消息还会做两件事情:
- 一个TransactionId只会对应一个PID,如果当前一个Producer的事务没有提交,而另外一个新的Producer保持相同的TransactionId,这是旧的生产者会立即失效,无法继续发送消息。
- 跨会话事务对齐,如果某个Producer实例异常宕机了,事务没有被正常提交。那么新的TransactionId相同的Producer实例会对旧的事务进行补齐。保证旧事务要么提交,要么终止。这样新的Producer实例就可以以一个正常的状态开始工作。
java高并发
传统的synchronized锁和JUC的Lock的区别
利用lock进行精确唤醒
什么是锁,锁的是啥
线程安全的List、set、map
阻塞队列
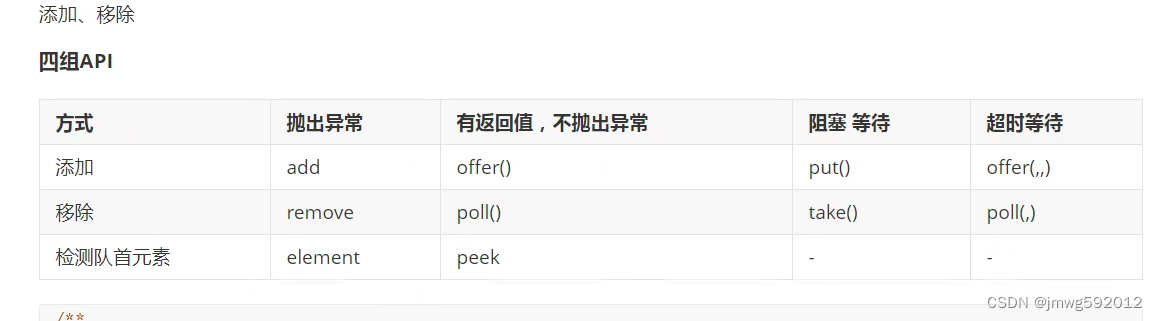
同步队列:SynchronousQueue
线程池、七大参数、四大拒绝策略
IO密集型、CPU密集型
(最大线程数要大于那些十分耗IO的线程数)

















 3747
3747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









