




 本文介绍了文本相似度计算的重要性,以及三种常见的方法:TF-IDF算法、余弦定理和Jaccard相似度。TF-IDF用于衡量词语在文件中的重要性;余弦定理计算文本间的角度来度量相似度;Jaccard相似度则通过集合的交集与并集计算文本的相似度。
本文介绍了文本相似度计算的重要性,以及三种常见的方法:TF-IDF算法、余弦定理和Jaccard相似度。TF-IDF用于衡量词语在文件中的重要性;余弦定理计算文本间的角度来度量相似度;Jaccard相似度则通过集合的交集与并集计算文本的相似度。
一、简介
文本相似度是进行文本聚类的基础,和传统的结构化数值数据的聚类方法相似,文本聚类是通过计算文本之间的“距离”来表示文本之间的相似度,并产生聚类。文本相似度的常用计算反法有余弦定理。但是文本数据和普通的数据不同,它是一种半结构化的数据,在进行聚类之前必须要对文本数据源进行处理,如分词、向量化表示等,其目的就是使用向量化的数值来表达这些半结构化的文本数据。使其适用于文本分析。
二、TF-IDF算法
在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文本中出现的次数(该次数一般会归一化处理,以防止它偏向长文本)。
在给定的文件里,词频

其中,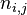 表示该词在文件
表示该词在文件
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2923
2923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









