




前言
"<数据库原理及应用>(MySQL版)".以下称为"本书"中2.3.1节内容
引入
本书P47原话:查询数据是数据库的核心操作,是使用频率最高的操作.
查询的操作非常重要,也有一定的难度,要和实际相结合理解.
笔者为学习方便,在本机安装了navicat premium lite 17,他是能连接各种数据库的管理软件,提供了mysql基本功能并且免费,他提供了操作界面,比起在Windows Shell中一行一行敲的效率高不少.
查询总览
数据查询分为基本查询,分组查询,连接查询,子查询,合并查询结果---几部分组成,基本上遵循了循序渐进的规律:后面的查询在前一种查询的基础上渐渐增加,所以应注意学习会有一定的层次感.
从物理层面理解查询:以现有的表(单个表或多个表)形成一张新表.---为查询建立一点感性认识
SELECT语句的基本语法
格式:
SELECT 属性(多个)
FROM 表(多个)
WHERE 条件表达式(多个)
GROUP BY 属性(多个) HAVING 条件表达式(多个)
ORDER BY 属性
说明:带下划线为可选项,HAVING为GROUP BY 的可选项.
属性即列名.斜体字为程序员定义项目.
---字面意思能理解出要做什么事,比较容易.
2.3.1基本查询
注意:基本查询都是单表查询,表现在FROM后面只有一个表的名称.
表定义
本书示例的几张表dept,emp,salgrade没有明确给出定义,自定义如下:
1.表dept
CREATE TABLE dept
(
deptno DECIMAL(2.0),
dname VARCHAR(14),
loc VARCHAR(13)
)2.表emp
create table emp
(
empno decimal(4.0) PRIMARY key,
ename varchar(10),
job varchar(9),
mgr decimal(4.0),
hiredate date,
sal decimal(7.2),
comm decimal(7.2),
deptno decimal(2.0)
)表dept遵循前面的书写规则:命令和关键字用大写,程序员自定义数据用小写表emp都是小写.
SELECT子句
全部查询
格式:SELECT * FROM 表名;
含义:查找表中全部内容."*"表示全部
部分查询
格式:SELECT 属性1(列名), 属性2(列名).....FROM 表名;
含义:查找表中部分属性,形成一张新的表.
查询结果去重复
格式:SELECT DISTINCT 属性1(列名), 属性2(列名).....FROM 表名;
含义:查找结果去掉重复行,形成一张新的表
应用场景:
在查找的结果中出现重复行---结合本书P49例子理解:表emp内容有雇员所在部门号,雇员职务,雇员名称.当搜索内容为有哪些部门和职务时,语句SELECT deptno,job FROM emp;因为某些部门里担任某职务的人不止一个,此时查询结果有多个相同的行.查询语句改为:SELECT DISTINCT deptno,job FROM emp;后只保留一行去除多余相同行.
对比部分查询,多了一个DISTINCT
为列起别名
格式:原字段(属性)名 [AS] 新列(属性)名;
含义:在查询结果(一张表)中,更改属性名称
用法:在SELECT和FROM之间的1个属性,更改为原字段(属性)名 [AS] 新列(属性)名;其中AS可省略.示例见本书P50例2-14.笔者个人感觉别名的用法有一点奇特,如果认为原属性名不好,为什么不在设计表的时候修改而专门用一条新的指令修改?不过既然设计出来给用户多一个选择也不错的.
WHERE子句指定查询条件
总览WHERE子句
在SELECT查询结果中,用WHERE设定条件,筛选出符合设定条件的行.
如图:
select语句:SELECT ename,job FROM emp;
加where语句:SELECT ename,job FROM emp WHERE salary>=2500;
| emp表 | select语句得到的表 | 加where语句得到的表 | |||||||
| ename | job | salary | ename | job | ename | job | |||
| 张三 | 业务员 | 2000 | 张三 | 业务员 | 李四 | 经理 | |||
| 李四 | 经理 | 2500 | 李四 | 经理 | 王五 | 总监 | |||
| 王五 | 总监 | 3000 | 王五 | 总监 | |||||
这个例子给"WHERE子句做了什么?"增加一点感性认识:
select语句得到包含原表中完整元组的表,where语句给出筛选条件,得到符合条件的表
表2-2常用的比较运算符的解读
首先回顾属性的数据类型:字符串型,数值型,时间日期型,布尔型.运算符的使用和他们相关.
表内有6种运算符:算数比较判断,逻辑比较判断,之间判断,字符串模糊判断,空值判断,之内判断.总的来说按照字面意思去理解就行了,难度也不大.笔者从几个值得注意的方面做如下分析:
1.逻辑比较判断型运算符属于"综合运算"
其他运算符可以单独得出结果,而逻辑比较判断型运算符将这些结果再次运算得到最终结果.
2.算数比较判断支持数值,其中"="支持字符串类型和时间日期型.
算数比较判断和其他语言中一样,数字比较的6种表达式<,>,<=,>=,!=和=
下面有一张emp表,用于后面搜索
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
| 7369 | SMITH | CLERK | 7902 | 17/12/1980 | 800 | 20 | |
| 7499 | ALLEN | SALESMAN | 7698 | 20/2/1981 | 1600 | 300 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 22/2/1981 | 1250 | 500 | 30 |
本书P50例2-15把等于号"="用于字符串搜索.
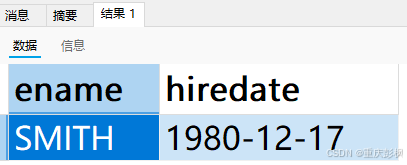
笔者自建一个搜索
SELECT ename,hiredate FROM `emp`
where hiredate='1980-12-17';得到的结果如图,说明等于号"="支持时间日期型搜索
3.之间判断BETWEEN...AND
本书P51例2-17说明时间日期型支持之间判断,由此得出结论:时间日期型数据底层表示为数值.
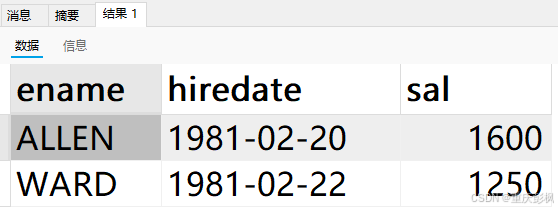
笔者自建一个搜索
SELECT ename,hiredate,sal FROM `emp`
where sal BETWEEN 1000 and 2000;得到如下结果
4.字符串的模糊查询
本书P51:在匹配字符串中使用通配符"%"和"-"."%"用于表示0个或任意多个字符,"-"表示任意1个字符.
举例:WHERE ename LIKE 'K%' OR ename LIKE '_C%';
'K%'匹配到KING,'_C%'匹配到SCOTT. //结果来自本书的emp表非本贴中的emp表
笔者自建一个搜索(基于本贴中的emp表)
SELECT ename,hiredate,sal FROM `emp`
where ename like 'T_' or ename like '%A%';得到结果如图

注意:虽然称为模糊查询,但执行逻辑是精确的,如'T_'并未匹配到SMITH,因为SMITH不符合匹配语句
5.空值判断
在表的元组中不填内容(注意是不填,不是写上NULL,会被认为是输入字符串"NULL"),当搜索时输入语句:"属性 IS NULL",即可得到搜索结果.
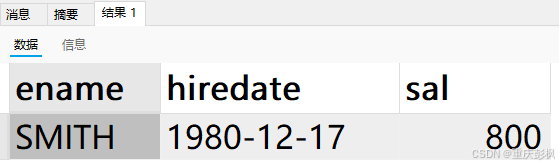
笔者自建一个搜索
SELECT ename,hiredate,sal FROM `emp`
where comm is NULL;得到结果如图
6.之内判断
与前面的between...and不同,之内判断是数值精确匹配.而between...and是范围匹配.
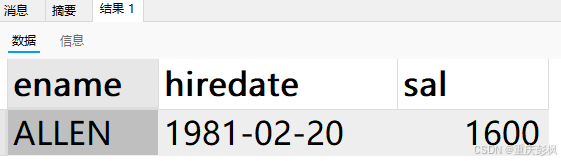
笔者自建一个搜索
SELECT ename,hiredate,sal FROM `emp`
where sal in(900,1600);得到结果如图
之内判断也支持时间日期类型,再次说明:时间日期类型在底层表示为数值.
SELECT ename,hiredate,sal FROM `emp`
where hiredate in('1981-02-22');得到结果如图

where子句小结
和字符串相关的有"字符串的模糊查询",和等于号"=".数值类型和时间类型其他运算符可用.至于字符串是否能用在其他运算上可自己试一试,但实际操作意义不大.
使用ORDER BY子句对查询结果排序
格式:ORDER BY 属性名1,...属性名n;
注意:必须放最后一个子句,属性名可以使用别名.
小结
SQL基本查询语句的分析



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











