






前言
以<深入理解计算机系统>(以下称“本书”)内容为基础,对程序的整个过程进行梳理。本书内容对整个计算机系统做了系统性导引,每部分内容都是单独的一门课.学习深度根据自己需要来定
引入
底层部分内容说难那也是挺难,但难度不是在理解上,而是并没有什么代码可以写.各种概念的实现都是半猜半记,本书没有提供对应的工具去开发(有是有但笔者不知道)
如前所述,数据是程序中最重要的部分(对软件程序员来讲),对数据的理解也是学习编程最好的切入点."一切都是数据,一切逻辑的实现都需要用数据表达".对这个概念应该有所觉悟.
文件基础认识
数据回顾
硬件层面:数据有地址和值两部分---地址用于数据传递,值表示数据含义.值也可以是地址,当值是地址的时候,需要继续向下解析.
软件层面:数据有类型限制---所有数据都归于一种类型(在面向对象中还可属于其继承的类型).数据由指针访问(基础数据类型由变量访问,但变量本质上仍是地址)
认识I/O
本书原话:输入/输出(I/O)是在主存和外部设备(例如磁盘驱动器、终端和网络)之间复制数据的过程.输入操作是从I/O设备复制数据到主存,而输出操作是从主存复制数据到I/O设备.---黑体字是原话.
---I/O即数据的传递
为什么需要理解Unix I/O
1>所有语言的运行时系统都提供执行I/O的较高级别工具.例如,C提供标准I/O库,包含printf和scanf这样执行带缓冲区的I/O函数.C++语言用他的重载运算符<<和>>提供输入输出功能.为什么要学习Unix I/O呢?我们经常遇到I/O和其他系统概念之间的循环依赖.例如进程和 I/O密不可分
2>有时候除了Unix I/O别无选择.
例如:标准 I/O没有提供读取文件元数据的方式,例如文件大小或文件创建时间.
另外 I/O库用来网络编程非常冒险
----上述黑体字是除了标准I/O外需要理解 Unix I/O的原因
文件的本质是什么
本书原话:一个Linux文件就是一个m个字节的序列:B0,B1,....Bm-1.所有的I/O设备(例如网络,磁盘和终端)都被模型化为文件,而所有的输入和输出都被当作对相应文件的读和写来执行.---黑体字是原话
1)文件是一个字节序列
2)文件是对硬件设备的抽象
本章中最重要的点在这里.硬件被抽象为文件.他的含义是:文件和硬件寄存器之间存在映射关系,当然文件的具体内容是什么,怎样排布,是由驱动怎么写决定的.
举个例子:假设有一个硬件A,有传感器和灯,传感器由8个字节的寄存器采集数据,8个字节的寄存器控制64个灯.那么可以用文件的读写方式建立起两个函数来和硬件A通信.
该文件有16个字节,前8个字节是传感器采集到的数据,后8个字节是用来控制64个灯的.尝试写出如下代码:
//伪代码
enum class Status{status_1,status_2,....status_n} //声明状态的枚举
Status showStatus(){ //采集状态的函数
int fd=Open("路径"); //打开文件所在路径的函数Open在后面有
long buf; //声明8字节空间,为接收传感器的8个字节做准备
read(fd,&buf,8); //读取8字节到buf中,read函数后面有
if (buf==1) //采集到的数据1等于1
return status_1; //枚举表示状态1
else if(buf==2) //采集到的数据2等于2
return status_2; //枚举表示状态2
... //其他
}
void light(Sometype st){ //点亮某些个灯的函数
int fd=Open("路径"); //打开文件所在路径的函数Open在后面有
if (情况1) //情况1下点亮前面8个灯,一个字节
char n=255; //内存空间中申请一个n,设为255,8个1.
seek(8); //显式设置文件当前位置为8,见本书P623(代码不保证正确)
write(fd,&n,1); //把n的地址传给write函数,1个字节,那么这8个1写给文件把灯点亮
else(情况2)
其他...
}
注:这段代码实在抽象,将就看一下.枚举是定义在什么地方的?假设标准中有
而且笔者做了一个假设:文件只映射寄存器,是否有函数未知.因为在平常印象中,文件有数据还有函数.
而笔者想表达的是:showStatus和light这类函数的集合,实际上将被汇集成为标准.参考笔者另一篇程序构建---标准是什么-优快云博客.那么这就是非常好的地方:程序员是面向标准开始编程,文件隐藏了硬件部分的实现细节.
文件所在的层次大致如下图所示: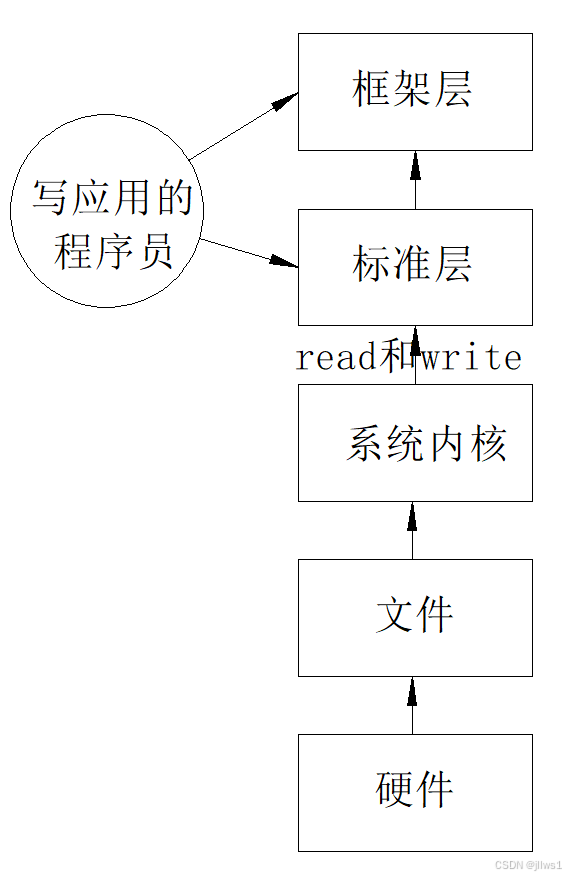
站在这个角度来看,文件和程序员关系并不大.文件的读写操作由系统内核封装给了标准,而程序员照着标准编程.当遇到问题时,再来看实现部分.
文件的执行方式
1>打开文件
标准I/O库调用open打开文件后,返回一个非负整数,叫做描述符.但他并不是指针(有点奇怪)
2>三个标准文件
每个进程开始时默认三个打开文件,标准输入(描述符0),标准输出(描述符1),标准错误(描述符2).推导进程想打开其他文件的时候,描述符从3开始.
3>改变当前的文件位置
描述符不是文件指针,内核保持一个文件位置k,初始为0,从文件开始的字节偏移量.应用程序能通过执行seek操作,显式设置当前文件的位置k.
4>读写文件
读文件操作从文件当前位置复制n>0个字节到内存,写文件是从当前位置k开始,都更新k
5>关闭文件
内核释放资源,文件使用的描述符恢复可用状态.
简单来说,文件打开,读写和关闭的操作流程.注意文件的描述符不是指针,由seek函数确定文件位置.
文件分类
每个Linux文件都有一个类型来表明他在系统的角色
1>普通文件
特点:包含任意数据
分类:文本文件和二进制文件.
二进制文件就是0和1组成的文件.
文本文件只含ASCII码或者Unicode字符的普通文件,文本文件是文本行序列,每个文本行是一个字符序列.文本行以新行符(换行符)'\n'结尾.
2>目录
包含一组链接的文件.目录下面包含文件或者其他目录
重点是目录的设计,从类型设计上来看,他是由一种"递归"的思想设计出的数据类型.如果用C++表示,大致如下:
struct Directory{
vector<Directory> next_layers;
}用口头语言来表达:"我"包含的数据是若干个和"我"相同的数据---可能有多个,可能没有(最后一层).可能是笔者孤陋寡闻,从没见过哪本书提到过这种设计,所以可以算是一点小小心得做奉献.
他和链表有点像但又不是链表,链表里没有表明下一层的"我"的个数,所以只被作为两个数据之间的链接.当然按照动态数组的思路,加上一个数量的属性也是同样的效果.
准确表达,他的类型应该是这样的:
struct Directory{
vector<File> files;
vector<Directory> next_layers;
}修正:笔者之前在数据类设计_图片类设计之7_矩阵图形类设计更新_实战之页面简单设计(前端架构)-优快云博客提到的矩阵图形类设计中采用了"散列算法"是不准确的.散列表和这个不一样,这是由递归思想设计出来的层级数据结构,抱歉.
此外,在设计模式中,有一种职责链模式,也采用了递归思想.
3>套接字
用来与另一个进程进行跨网络通信的文件
目录层次
绝对路径
以斜杠开始,表示根节点开始的路径.
相对路径
以当前工作目录开始,以1个点(.)和/表示访问当前目录中的文件或目录.
以2个点(..)和/表示访问上一级目录开始访问
小结
文件初探



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











