






布隆过滤器(Bloom Filter) 是一种高效的概率型数据结构,用于判断一个元素是否属于某个集合。它的核心特点是:
- 空间效率高:布隆过滤器使用位数组和多个哈希函数来表示集合,占用的内存远小于传统的哈希表。
- 查询速度快:判断一个元素是否在集合中的时间复杂度是 O(k)O(k),其中 k k 是哈希函数的数量。
- 允许误判:布隆过滤器可能会误判(False Positive),即判断一个元素在集合中,但实际上不在。但不会漏判(False Negative),即如果布隆过滤器判断一个元素不在集合中,那么它一定不在。
布隆过滤器简介
当你往简单数组或列表中插入新数据时,将不会根据插入项的值来确定该插入项的索引值。这意味着新插入项的索引值与数据值之间没有直接关系。这样的话,当你需要在数组或列表中搜索相应值的时候,你必须遍历已有的集合。若集合中存在大量的数据,就会影响数据查找的效率。
针对这个问题,你可以考虑使用 哈希表。利用哈希表你可以通过对 “值” 进行哈希处理来获得该值对应的键或索引值,然后把该值存放到列表中对应的索引位置。这意味着索引值是由插入项的值所确定的,当你需要判断列表中是否存在该值时,只需要对值进行哈希处理并在相应的索引位置进行搜索即可,这时的搜索速度是非常快的。

根据定义,布隆过滤器可以检查值是 “可能在集合中” 还是 “绝对不在集合中”。“可能” 表示有一定的概率,也就是说可能存在一定为误判率。那为什么会存在误判呢?下面我们来分析一下具体的原因。
布隆过滤器(Bloom Filter)本质上是由长度为 m 的位向量或位列表(仅包含 0 或 1 位值的列表)组成,最初所有的值均设置为 0,如下图所示。

为了将数据项添加到布隆过滤器中,我们会提供 K 个不同的哈希函数,并将结果位置上对应位的值置为 “1”。在前面所提到的哈希表中,我们使用的是单个哈希函数,因此只能输出单个索引值。而对于布隆过滤器来说,我们将使用多个哈希函数,这将会产生多个索引值。

如上图所示,当输入 “semlinker” 时,预设的 3 个哈希函数将输出 2、4、6,我们把相应位置 1。假设另一个输入 ”kakuqo“,哈希函数输出 3、4 和 7。你可能已经注意到,索引位 4 已经被先前的 “semlinker” 标记了。此时,我们已经使用 “semlinker” 和 ”kakuqo“ 两个输入值,填充了位向量。当前位向量的标记状态为:

当对值进行搜索时,与哈希表类似,我们将使用 3 个哈希函数对 ”搜索的值“ 进行哈希运算,并查看其生成的索引值。假设,当我们搜索 ”fullstack“ 时,3 个哈希函数输出的 3 个索引值分别是 2、3 和 7:

从上图可以看出,相应的索引位都被置为 1,这意味着我们可以说 ”fullstack“ 可能已经插入到集合中。事实上这是误报的情形,产生的原因是由于哈希碰撞导致的巧合而将不同的元素存储在相同的比特位上。幸运的是,布隆过滤器有一个可预测的误判率(FPP):
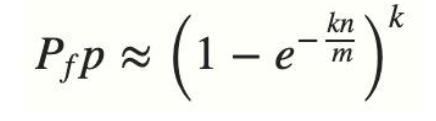
- n 是已经添加元素的数量;
- k 哈希的次数;
- m 布隆过滤器的长度(如比特数组的大小);
极端情况下,当布隆过滤器没有空闲空间时(满),每一次查询都会返回 true 。这也就意味着 m 的选择取决于期望预计添加元素的数量 n ,并且 m 需要远远大于 n 。
实际情况中,布隆过滤器的长度 m 可以根据给定的误判率(FFP)的和期望添加的元素个数 n 的通过如下公式计算:
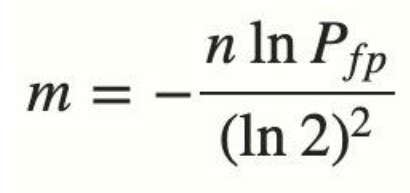
了解完上述的内容之后,我们可以得出一个结论,当我们搜索一个值的时候,若该值经过 K 个哈希函数运算后的任何一个索引位为 ”0“,那么该值肯定不在集合中。但如果所有哈希索引值均为 ”1“,则只能说该搜索的值可能存在集合中。
布隆过滤器应用
在实际工作中,布隆过滤器常见的应用场景如下:
- 网页爬虫对 URL 去重,避免爬取相同的 URL 地址;
- 反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱;
- Google Chrome 使用布隆过滤器识别恶意 URL;
- Medium 使用布隆过滤器避免推荐给用户已经读过的文章;
- Google BigTable,Apache HBbase 和 Apache Cassandra 使用布隆过滤器减少对不存在的行和列的查找。 除了上述的应用场景之外,布隆过滤器还有一个应用场景就是解决缓存穿透的问题。所谓的缓存穿透就是服务调用方每次都是查询不在缓存中的数据,这样每次服务调用都会到数据库中进行查询,如果这类请求比较多的话,就会导致数据库压力增大,这样缓存就失去了意义。
利用布隆过滤器我们可以预先把数据查询的主键,比如用户 ID 或文章 ID 缓存到过滤器中。当根据 ID 进行数据查询的时候,我们先判断该 ID 是否存在,若存在的话,则进行下一步处理。若不存在的话,直接返回,这样就不会触发后续的数据库查询。需要注意的是缓存穿透不能完全解决,我们只能将其控制在一个可以容忍的范围内。
布隆过滤器java实现
import java.util.BitSet;
import java.util.Random;
/**
* 布隆过滤器实现
*/
public class BloomFilter {
private BitSet bitSet; // 位图,用于存储布隆过滤器的位数组
private int bitSetSize; // 位图的大小
private int numHashFunctions; // 哈希函数的数量
private Random random = new Random(); // 随机数生成器,用于哈希函数
/**
* 构造函数
*
* @param bitSetSize 位图的大小
* @param numHashFunctions 哈希函数的数量
*/
public BloomFilter(int bitSetSize, int numHashFunctions) {
this.bitSetSize = bitSetSize;
this.numHashFunctions = numHashFunctions;
this.bitSet = new BitSet(bitSetSize);
}
/**
* 添加元素到布隆过滤器
*
* @param element 要添加的元素
*/
public void add(String element) {
for (int i = 0; i < numHashFunctions; i++) {
int hash = hash(element, i); // 计算哈希值
bitSet.set(hash, true); // 将对应位置设置为 1
}
}
/**
* 检查元素是否可能存在于布隆过滤器中
*
* @param element 要检查的元素
* @return 如果元素可能存在,返回 true;否则返回 false
*/
public boolean contains(String element) {
for (int i = 0; i < numHashFunctions; i++) {
int hash = hash(element, i); // 计算哈希值
if (!bitSet.get(hash)) { // 如果有一个位置为 0,则元素一定不存在
return false;
}
}
return true; // 所有位置都为 1,元素可能存在
}
/**
* 哈希函数
*
* @param element 要哈希的元素
* @param seed 哈希种子
* @return 哈希值
*/
private int hash(String element, int seed) {
random.setSeed(seed); // 设置随机种子
return Math.abs(element.hashCode() ^ random.nextInt()) % bitSetSize; // 哈希计算
}
public static void main(String[] args) {
// 创建一个布隆过滤器,位图大小为 1000,哈希函数数量为 3
BloomFilter bloomFilter = new BloomFilter(1000, 3);
// 添加元素
bloomFilter.add("apple");
bloomFilter.add("banana");
bloomFilter.add("orange");
// 检查元素是否存在
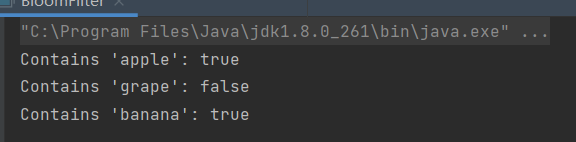
System.out.println("Contains 'apple': " + bloomFilter.contains("apple")); // true
System.out.println("Contains 'grape': " + bloomFilter.contains("grape")); // false (可能误判)
System.out.println("Contains 'banana': " + bloomFilter.contains("banana")); // true
}
}
运行结果:


















 396
396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









