




 k-最近邻(kNN)算法是一种懒散学习模型,无需训练过程。它通过计算新样本与训练样本间的距离进行分类,常用的距离度量包括欧式距离、曼哈顿距离和闵可夫斯基距离。k值的选择影响模型性能,过小可能导致过拟合,过大则可能平均化数据模式。此外,kNN还可用于回归任务。选择合适的距离度量和k值是关键,如考虑使用余弦相似度处理高维数据。
k-最近邻(kNN)算法是一种懒散学习模型,无需训练过程。它通过计算新样本与训练样本间的距离进行分类,常用的距离度量包括欧式距离、曼哈顿距离和闵可夫斯基距离。k值的选择影响模型性能,过小可能导致过拟合,过大则可能平均化数据模式。此外,kNN还可用于回归任务。选择合适的距离度量和k值是关键,如考虑使用余弦相似度处理高维数据。
训练k近邻模型需要多长时间?
答案是零秒。这听起来可能有些让人吃惊,但事实上,kNN是一种极其“懒散”的模型,它并不进行任何训练!
有监督学习算法群体中包含多样的算法,但kNN却独树一帜。它是一个相对简单的模型,因此是初学者入门的好选择。它背后的数学原理美妙而复杂:kNN为我们揭示了距离度量(在实践中常被视为抽象概念)在机器学习领域的重要性。
kNN看起来基本,但其实是如基于向量的相似性搜索等高级技术的基石。当你在Google上使用图片搜索时,后台可能就运行了某种版本的kNN算法。
在阅读完这篇文章后,你将深入了解kNN及其他“懒散”算法的运行方式,以及为何距离是数据科学和机器学习中最关键的概念之一。
让我们现在开始!
我们发现kNN是一个值得探讨的话题:它在表面上看似简单,但实际上与诸如距离和相似性这样的深层次概念紧密相连。祝你阅读愉快!
kNN算法的工作原理
kNN主要用于分类,因此,让我们来考虑以下例子。
我们用一个玩具数据集,其中包含三个类别:蓝色、黄色和红色。假设每个样本代表一个向量数据库中的文档,每个类是一个类别:科学、文学或新闻文章。
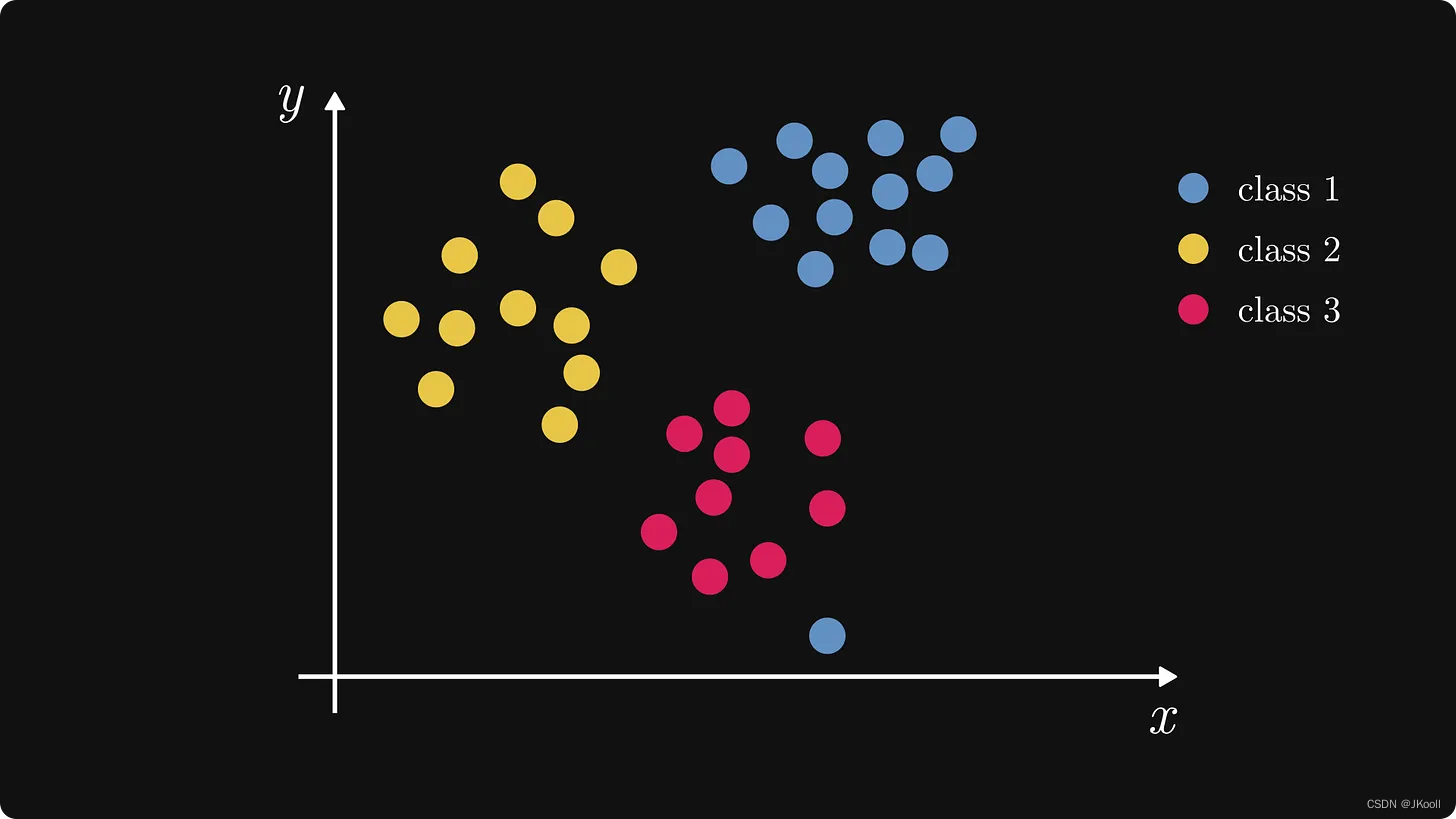
在机器学习中,我们使用这些数据来训练一个泛化模型。然而kNN是个例外:它在新的数据点输入用于推理之前甚至不看这个数据集!
这就是它被称为“懒散”的原因。懒散的模型并不从训练集中学习,而是将其存储起来,并在每次进行预测时提取出来。
kNN通过以下步骤来进行预测:
- 计算新样本与训练样本之间的距离
- 找出k个最近的邻居
- 通过k个最近邻居的多数投票来对新样本进行分类。
简而言之,你给kNN展示你的邻居,kNN就会告诉你你是谁。
短短几句话难以对算法做出公正的评价,所以这里有一个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3305
3305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











