






由于最近刚刷完二叉树的相关知识,学习的过程中也记录了不少学习笔记,在这里就通过文章的方法分享给大家,感觉写的还是挺全面的,希望能对各位读者带来帮助~
如果读者学习二叉树是为了刷letcode的话,那么后面两节最好别看,因为涉及到了较多letcode的题目的题解
1. 二叉树的介绍
二叉树是指给定一个节点,每个节点又可能有左右两个节点,由此数据结构组成的树状数据结构,在C++中,可以使用如下的结构体定义二叉树
struct TreeNode
{
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x) , left(NULL) , right(NULL)
}
二叉树具有多种类型,下面介绍在刷题过程中较为常遇到的类型:
(1)满二叉树
如果一棵二叉树只有度为0的结点和度为2的结点,并且度为0的结点在同一层上,则这棵二叉树为满二叉树。或者说除了二叉树的最后一层,其它层的所有节点都具有左右两个节点。满二叉树如下所示:

满二叉树可以通过统计节点数和获得最大深度来验证,即如果一个满二叉树的深度为k,则该树一定有2^k - 1个节点
满二叉树的所有子树都是满二叉树,而所有子树都是满二叉树的根节点也一定是满二叉树。故满二叉树也可以使用递归来验证。
(2)完全二叉树
在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。我们可以结合过下面的这张图来理解上面这段话。对于前两个,容易理解。而对于第三个,由于最下面一层节点并不是全部靠在该层最左边的位置,故第三个不是完全二叉树。

对于完全二叉树,其所有子树也是完全二叉树。但该结论反过来就不能成立,即如果所有子树为完全二叉树,其根节点不一定是完全二叉树。如下反例:
完全二叉树的验证可以使用层序遍历来完成
(3)二叉搜索树
二叉搜索树是在刷题过程中常遇到的树的类型,其满足如下的规则:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值
- 它的左、右子树也分别为二叉搜索树
例如下面给出来的两个例子

那么我们再反过来想,如果一个根节点的所有子树都是二叉搜索树,那么这个根节点是否为二叉搜索树呢?答案依然是否定的,例如下面这棵二叉树

由于图中的5右边的节点4要小于5,这就导致虽然子树都是完全二叉树,但根节点却并不是完全二叉树。
二叉搜索树后面会专门用一个小结来更详细的介绍
(4)平衡二叉树
平衡二叉树是指它的左右两个子树的高度差的绝对值不超过1,也可以是一颗空树,并且左右两个子树都是一棵平衡二叉树。

上面给出的三棵树比较容易判断出是否为平衡二叉树,那么下面给出的这棵树是平衡二叉树吗?答案是否定的,因为平衡二叉树要求所有的子树也是一颗平衡二叉树,然而对于节点4,其左边的高度为2,右边的高度为0,这就不符合平衡二叉树的要求(右边的节点6同理)。故该树并不是平衡二叉树。

接下来给出新的问题:如果一个根节点的所有子树为平衡二叉树,那么这个根节点是否为平衡二叉树呢?答案同样是否定的,例如上面3个二叉树中的第三个二叉树,其所有子树都是平衡二叉树(空树也是平衡二叉树),而根节点并不是。
上面的结论导致我们不能使用简单的递归来判断平衡二叉树,需要额外的分支判断,判断程序如下:
class Solution {
public:
int helper(TreeNode* root) //递归辅助函数
{
if (!root)
return 0;
int l = helper(root->left);
int r = helper(root->right);
if (l < 0 || r < 0) //如果有任一子树不为平衡二叉树,则直接返回
return -1;
if (abs(l - r) > 1) //左右两边节点高度差距大于1,该节点不为平衡二叉树
return -1; //用-1代表当前当前树不是平衡二叉树
else
return max(l, r) + 1; //当前节点的高度为左右两边的最大高度再加1
}
bool isBalanced(TreeNode* root)
{
int res = helper(root);
return (res >= 0) ? true : false;
}
};
2. 二叉树的遍历
二叉树的遍历分为前序遍历、中序遍历、后序遍历以及层序遍历,下面通过以下这个树来逐一进行介绍

(1)前序遍历
前序遍历是按照“中左右”的节点顺序对二叉树进行遍历,对于上述给定的树,前序遍历得到的结果为:
5 4 1 2 6 7 8
前序遍历在程序中可以通过递归法和迭代法两种方法实现,这两种方法最好都掌握一下!
递归法程序较为简单,如下:
void front_erg(TreeNode* head)
{
if (head == NULL)
return;
//处理节点,我这里是直接打印了
printf("%d ", head->val); //中,即自己
front_erg(head->left); //左
front_erg(head->right); //右
}
迭代法的方法借鉴了递归的思想,使用了栈来保存数据:
void front_erg_iter(TreeNode *head)
{
if(!head)
return;
stack<TreeNode *> stk; //创建栈
stk.push(head);
while(!stk.empty())
{
TreeNode *node = stk.top();
stk.pop(); //释放节点
//处理节点,我这里是直接打印了
printf("%d ",node->val);
//由于前序是“中左右”的遍历顺序,而栈又是后入先出的顺序,故这里需要先放入右节点,再放入左节点
if(node->right)
stk.push(node->right);
if(node->left)
stk.push(node->left);
}
}
(2)中序遍历
中序遍历是按照”左中右“的节点顺序对二叉树进行遍历,对于上述给定的树,中序遍历得到的结果为:
1 4 2 5 7 6 8
中序遍历在程序中同样可以通过递归法和迭代法两种方法实现,这两种方法最好都掌握一下!
递归法仍然比较简单,只需要简单更换代码的位置就可以实现:
void middle_erg(TreeNode *head)
{
if(!head)
return;
middle_erg(head->left); //左
//处理节点,我这里是直接打印了
printf("%d ",head->val); //中,即自己
middle_erg(head->right); //右
}
迭代法并不像递归法那样简单变更代码位置就可以实现,对于中序遍历实现较为复杂:
void middle_erg_iter(TreeNode *head)
{
if(!head)
return;
stack<TreeNode *>stk;
TreeNode *node = head;
while(node || !stk.empty())
{
if(node) //如果节点不为空,则表明还没有深入到最左侧的节点
{
stk.push(node); //入栈当前节点
node = node->left; //继续往左探索
}
else //往左走到头了,说明左边没有,按照“左中右”的顺序,下面该输出“中”了
{
node = stk.top(); //获得栈顶节点
stk.pop(); //并释放
printf("%d ",node->val); //处理当前“中”节点,这里是打印
node = node->right; //“左中”处理完毕,接下来该“右”节点了,故往右探索
}
}
}
(3)后序遍历
后序遍历是按照”左右中“的节点顺序对二叉树进行遍历,对于上述给定的树,后序遍历得到的结果为:
2 1 4 7 8 6 5
后序遍历在程序中依旧可以通过递归法和迭代法两种方法实现,这两种方法最好都掌握一下!
递归法还是比较简单,还是只需要简单更换代码的位置就可以实现:
void back_erg(TreeNode *head)
{
if(!head)
return;
back_erg(head->left); //左
back_erg(head->right); //右
//处理节点,这里为打印
printf("%d ",head->val); //中
}
而对于后序遍历的迭代法,实现则更为复杂一些:
/*
* 以下这个不太好理解,我这里给一个处理过程中栈的元素
* 5 (在while前放入,下面进入while循环)
* 5 NULL 6 4 (添加NULL并存放左右节点,如果存在的话)
* 5 NULL 6 4 NULL 2 1
* 5 NULL 6 4 NULL 2 1 NULL (由于节点1没有左右节点,则这里没有入栈其他数据) 1被打印
* 5 NULL 6 4 NULL 2 (遇到了NULL,则先将NULL给pop出去,在得到1,处理后同样pop。所以1 NULL就出栈了)
* 5 NULL 6 4 NULL 2 NULL 2被打印
* 5 NULL 6 4 NULL
* 5 NULL 6 4被打印
* 5 NULL 6 NULL 8 7
* 篇幅原因,下面不在给出,和上面处理是同理的
* 不过可以看到我们要处理的节点是通过NULL来控制的
*/
void back_erg_iter(TreeNode* head)
{
if (!head)
return;
stack<TreeNode*>stk;
stk.push(head);
TreeNode* node;
while(!stk.empty())
{
node = stk.top();
if (node)
{
stk.push(NULL); //这个NULL用于在合适时间处理数据
//同理栈的顺序,先入右,则入左
if (node->right)
stk.push(node->right);
if (node->left)
stk.push(node->left);
}
else //遇到了NULL,表示该打印了
{
stk.pop(); //先将当前的NULL给pop掉
node = stk.top(); //再将要处理的数据得到
//处理节点,这里仅打印
printf("%d ", node->val);
stk.pop();
}
}
}
上述这么复杂不好记,不好想怎么办?还可以使用一种非常巧妙的办法来实现后序遍历,那就是把我们可以先求中右左(因为只要是中开头,程序都不复杂),然后再把结果给反转就可以实现后序遍历的“左右中”了!缺点就是引入了额外的空间,且没有办法在流程中边遍历边处理~
void back_erg_iter(TreeNode* head)
{
stack<TreeNode*> stk;
vector<int> res;
if (head)
stk.push(head);
while (!stk.empty())
{
TreeNode* node = stk.top();
stk.pop();
res.push_back(node->val); //中
if (node->left)
stk.push(node->left); //右
if (node->right)
stk.push(node->right); //左
}
reverse(res.begin(), res.end()); //反转数据,得到后序遍历的结果
for(int i : res)
printf("%d ",i);
return res;
}
(4)层序遍历
层序遍历相较于前面所讲的就相对简单了,对于一颗二叉树,层序遍历通过先上后下,先左后右的方式,对二叉树进行遍历。对于上面给定的二叉树,层序遍历的结果为:
5 4 6 1 2 7 8
层序遍历一般使用迭代法来进行操作,程序还是较为简单易写的:
void floor_erg(TreeNode* head)
{
if (!head)
return;
queue<TreeNode*> que; //使用了队列而不是栈
que.push(head);
int floor_num; //记录每一层的节点数
while (!que.empty()) //每一层while循环都会搭配for循环遍历完一层
{
int floor_num = que.size(); //获得当前层节点个数
for (int i = 0; i < floor_num; i++)
{
TreeNode *node = que.front();
que.pop();
printf("%d ", node->val);
if (node->left)
que.push(node->left); //左
if (node->right)
que.push(node->right); //右
}
}
}
(5)遍历小结
这一节学习了前序、中序、后序以及层序遍历四种遍历方式。对于前三种,不同遍历的方式就代表了“中”的位置,例如前序遍历“中左右”的“中”就在最前面。利用递归法可以非常方便的实现前三种方式的遍历,而使用迭代法则对于不同的遍历方式有不同的处理方法,虽然复杂,但建议也要掌握,这些迭代的思想在刷题的时候还是很有帮助的。对于层序遍历,该方式就比较简单,可以使用队列很快的实现。但层序遍历在刷题的时候还是很有用的,可以用于检验生成的二叉树结果是否符合要求。
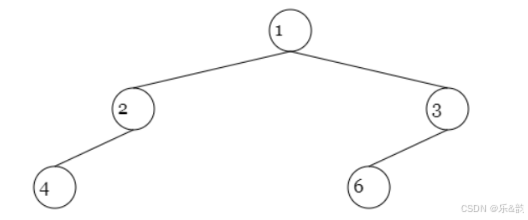
下面我们开始思考一个问题,对于一棵无重复元素的二叉树,给定任意一个遍历结果,我们是否能通过该结果反推出原始的二叉树呢?答案是否定的,例如下面二叉树是不同的,但前序遍历的结果是一样的

一个遍历结果不行,那么两个不同遍历的结果可以确定一棵树吗?如果给定的是前序和后序,那么也是无法确定一棵树的,例如下面这个例子,两棵树是不同的,但前序[1 2 3]和后序[3 2 1]是一样的。

只有知道了中序遍历以及前序、后序二者任意一方时,才可以反推出原始的二叉树。这个核心就是利用中序来分割左右二叉树,并利用前序或后序寻找根节点,这个是什么意思呢?还是拿本章最开始的那棵树举例,前面我们已经给出了这棵树的前序、中序、后序遍历的结果,如下:
- 前序:5,4,1,2,6,7,8
- 中序:1,4,2,5,7,6,8
- 后序:1,2,4,7,8,6,5
通过和后序我们可以知道这课树的根节点为5,然后再根据中序,我们就可以知道{1,4,2}在根节点的左边,而{7,6,8}在根节点的右边,然后将分开的左右节点执行相同的操作,依此类推(可以看到是递归的操作),就可以完成二叉树的构建,相应的程序如下:
利用前序遍历和中序遍历:
class Solution {
public:
//index在函数的递归过程中充当了局部根节点的下标
TreeNode* helper(vector<int>& preorder,int& index,vector<int>& inorder, int left_in, int right_in)
{
if (left_in == right_in)
{
//由于目前index指向在preorder指向自己
//而自己已经处理完毕了,故需要自增,使preorder指向下一个值
index++;
return new TreeNode(inorder[left_in]);
}
if (left_in > right_in)
return NULL;
int root_val = preorder[index]; //局部根节点对应的值
int root_index; //局部根节点位于inorder中的位置
for (int i = left_in; i <= right_in; i++) //可以使用哈希表加快搜索速度
{
if (inorder[i] == root_val)
{
root_index = i;
break;
}
}
TreeNode* root = new TreeNode(root_val);
//能到这里说明肯定至少存在一个子节点,这里先将index使其在preorder指向该节点
/* 例子:
* 3
* / \
* 20 null
* 前序:3,20 中序: 20,3
* 例如此时index指向的是3,那么由于3存在子节点,需要在前序中指向3的子节点
* 由于前序的保存顺序为:中左右,故下面先处理左边的部分,再处理右边的部分
*/
index++;
//下面分隔区间采取了左闭右闭的处理方法,根据根节点位于inorder中的位置将左右区间进行分隔
root->left = helper(preorder, index, inorder, left_in, root_index - 1);
//这里没有index++的原因见函数开头,这么做是为了避免左边节点为空时index自增两次
root->right = helper(preorder, index, inorder, root_index + 1, right_in);
return root;
}
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder)
{
int n = preorder.size();
int index = 0;
return helper(preorder, index, inorder, 0, n - 1);
}
};
利用中序遍历和后序遍历,这里使用了另外一种风格的写法:
class Solution {
public:
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder)
{
if (inorder.size() == 1)
return new TreeNode(inorder[0]);
if (inorder.size() == 0)
return NULL;
int root_val = postorder.back(); //对于后序遍历,最后一个值为根节点
int root_index;
//得到根节点的索引
for (int i = 0; i < inorder.size(); i++)
{
if (inorder[i] == root_val)
root_index = i;
}
vector<int> new_in;
vector<int> new_post;
//处理左子树部分
new_in.assign(inorder.begin(), inorder.begin() + root_index);
new_post.assign(postorder.begin(), postorder.begin() + root_index);
TreeNode* l = buildTree(new_in, new_post);
//处理右子树部分
new_in.assign(inorder.begin() + root_index + 1, inorder.end());
new_post.assign(postorder.begin() + root_index, postorder.end() - 1);
TreeNode* r = buildTree(new_in, new_post);
TreeNode* root = new TreeNode(root_val);
root->left = l;
roo->right = r;
return root;
}
};
3. 二叉树的常用操作
(1)二叉树的释放
二叉树在申请时我们往往会使用动态空间,这就需要我们在使用完成后需要的构建的二叉树完成空间释放,释放的操作也很简单,只需要注意把“中”(即自己)最后释放掉就可以。
void tree_free(TreeNode *head)
{
if(!head)
return;
tree_free(head->left);
tree_free(head->right);
delete head; //如果使用的是new申请的话
}
当然也可以使用迭代的方法,使用栈就可,比较简单,这里就不给出了。
(2)二叉树的深度
二叉树的深度是指从某一路径的高度,该路径由根节点开始,叶子结点结束。由于二叉树往往具备多条路径,故这就设计到了求解最大深度和最小深度。
对于最大深度,只需要先到最底层,然后自底向上返回当前深度就可以,程序如下:
int maxDepth(TreeNode* root)
{
if (!root)
return 0;
int a = maxDepth(root->left); //获得左子树的最大深度
int b = maxDepth(root->right); //获得右子树的最大深度
return (a > b) ? (a + 1) : (b + 1); //由于要返回给上一层,故需要把当前深度加1
//return max(a,b) + 1; //更简洁易懂
}
对于最小深度,其原理和最大深度是一样的。由于最小深度要比较最小值,我们不能在空节点时返回0(除了根节点外),这会导致最小值比较失效。程序如下:
class Solution {
public:
int helper(TreeNode* root)
{
if (!root)
return INT_MAX; //为了规避只有一个子节点的情况返回0导致的最小值计算有误
if (!root->left && !root->right) //如果当前是叶子节点,则当前深度为1
return 1;
int a = helper(root->left);
int b = helper(root->right);
return (a < b) ? (a + 1) : (b + 1); //取最小值
}
int minDepth(TreeNode* root)
{
if (!root)
return 0; //只有根节点为空时才返回0,其他时候的空要分开处理
return helper(root);
}
};
二叉树的深度是很重要的一个知识点,很多其他题目都会间接或直接使用深度来实现,例如判断平衡二叉树或二叉树最大直径,所以对于深度的处理一定要掌握!
此外,在补充一句题外话,二叉树的高度和深度是不同的概念,或者说他俩是反着来的,不要混为一谈。(下图用了代码随想录的图)

(3)翻转二叉树
翻转二叉树如下图所示,可以看到每一个节点的左右节点都互换了,这个就很简单了,因为我们对所有节点的操作都是想用的,交换左右节点,交换完成后再处理自己的左右节点就可以。据说这个题当时面试谷歌的大佬都没做出来,掌握了是不是就能进谷歌了(`・ω・´)

程序如下,这里给出迭代的写法,递归也不难~
TreeNode* invertTree_iter(TreeNode* root)
{
stack<TreeNode*> stk;
TreeNode* node = root;
if (node)
stk.push(node);
while (!stk.empty())
{
node = stk.top();
stk.pop();
swap(node->left, node->right); //交换左右节点
if(node->left) //处理左节点
stk.push(node->left);
if(node->right) //处理右节点
stk.push(node->right);
}
return root;
}
(4)最近公共祖先
二叉树的公共祖先是什么意思呢?网上的定义是这样的:对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。这句话要表达的内容其实很简单,但并不是很好理解,下面通过一张图来介绍一下:

在这种图中,节点6和节点7的最近公共祖先是5,他们俩都是以5为根节点的二叉树中。虽然3也是公共祖先(因为也在以3为根节点的二叉树中),但我们由于要求的是最近的,故结果为5。同样的,对于6、8,最近公共祖先为3;对于1、5,最近公共祖先为3,对于7、4,最近公共祖先为2。寻找最近公共祖先的应用场景有很多,例如在公司组织架构中找最近的主管。
上面知道了最近公共祖先的定义,那么应该如何求解呢?这里我们考虑二叉树节点各不相同的情况(这也是大多数的应用场景),如果给定要求最近公共祖先的两个节点都位于二叉树中,则必定有如下结论:
- 在找到p和q任意一个节点(例如p)后,直接返回并去树的另半边去找,如果找不到,则q一定位于以p为根节点的二叉树中
- 如果p和q都被找到,则p和q一定位于某一节点的的两边,且该节点是唯一的,该节点即为公共祖先
知道了上述结论,我们就可以很简洁的求出二叉树节点的最近公共祖先:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q)
{
if (!root || root == p || root == q) //找到或者空节点就直接返回
return root;
TreeNode* left = lowestCommonAncestor(root->left, p, q); //先在左边找
TreeNode* right = lowestCommonAncestor(root->right, p, q); //再在右边找
if (!left) //如果左边没找到p或q其中一个,则直接返回右边的结果(右边可能也没找到,那么这个情况就直接返回NULL了)
return right;
if (!right) //到这里说明左边找到了p或q其中一个,但右边没找到,则直接返回左边的结果
return left;
return root; //如果左右两边都找到了,则说明位于该根节点的两边,说明本节点为最近公共祖先,返回本节点
}
4. 二叉搜索树专题
二叉搜索树是二叉树中非常重要的一个类型,或者可以说我们很多时候使用二叉树就是为了使用二叉搜索树,并且关于二叉树的元素查找、删除或者插入等等操作,都是在二叉搜索树下才具有实际意义,故二叉搜索树我将用一个小节来进行单独讲解。
前面已经讲了什么是二叉搜索树,这里就不在赘述,下面我就直接从二叉搜索树的应用入手。但在处理二叉搜索树时,有一句话一定要铭记在心中:**看到二叉搜索树就先考虑中序遍历!**这是因为由于二叉搜索树是有序的二叉树,所以其中序遍历的结果也是有序的,这使得我们可以利用中序遍历来处理很多二叉搜索树的问题。
(1)验证二叉搜索树
即给定一棵二叉树,我们来判断其是否为二叉搜索树。前面已经说了,其中序遍历是有序的,这里我们就可以直接查看中序遍历是否为递增的来完成判断~
class Solution {
private:
TreeNode* pre;
public:
bool isValidBST(TreeNode* root)
{
if(!root)
return true;
//左
bool l = isValidBST(root->left);
//中
if(pre && pre->val >= root->val) //等于也是不可以的哦!
return false;
pre = root; //将当前值保存为上一个
//右
bool r = isValidBST(root->right); //再判断右边
return (l && r);
}
}
可以看到上述程序框架也就是在中序遍历的递归程序基础上额外加了几行代码。
当然,这个题除了这么做外,还可以自顶而下,一直更新区间,判断该节点是否位于给定的区间中。下面仅进给出思想,程序感兴趣还请自行编写~
/* 通过下面这个图介绍一下区间更新方法
* 10 (-∞,+∞)
* / \
* (-∞,10) 5 15 (10,+∞)
* / \ / \
* (-∞,5) 3 7 6 20 (15,+∞)
* (5,10)---↑ ↑----- (10,15)
* 由于6不在规定范围内,故该二叉树验证失败
*/
(2)查找元素
在二叉搜索树中,大于当前节点的元素在节点的右子树上,小于当前节点的元素在节点的左子树上,这就使得我们使用二叉搜索树查找元素时可以更快的获取,使用二叉搜索树查找元素的时间复杂度为log(n)。
这里使用迭代就可以很方便简洁的完成:
TreeNode* searchBST(TreeNode* root, int val)
{
while(root)
{
if(root->val == val) //找到了,则返回该节点的地址
return root;
else if(root->val > val) //大于val,说明可能位于当前节点的左边
root = root->left;
else //小于val,说明可能位于当前节点的右边
root = root->right;
}
return NULL; //找不到返回NULL
}
(3)插入元素
由于二叉搜索树的有序性,这使得插入的操作更加的规则。给定一棵二叉树和一个要插入的元素,我们只需要一直往下层遍历找到合适的节点插入即可。
这里我还是给出迭代的程序,因为二叉搜索树的性质使得我们仅通过单一路径即可以完成要求,故使用迭代法更合适些!
TreeNode* insertIntoBST(TreeNode* root, int val)
{
if(!root)
return new TreeNode(val);
TreeNode* pre; //保存上一个节点
TreeNode* curr = root; //保存当前节点
char pos; //记录分支方向
while(curr)
{
pre = curr;
//这里假设插入的值不存在于给定的二叉树中,即不考虑curr->val == val的情况
if(curr->val > val)
{
curr = curr->left;
pos = 'l';
}
else
{
curr = curr->right;
pos = 'r';
}
}
if(pos == 'l')
pre->left = new TreeNode(val);
else
pre->right = new TreeNode(val);
return root;
}
(4)删除元素
删除元素的处理要比插入元素复杂一些,这是因为删除后,我们还需要将删除节点指向的和被指的重新联系起来。例如下面这棵树。

如果要删除节点3,则删除后的结果如右边所示。这前后发生了哪些变化呢?首先是3的上一级节点5的左节点指向了3的右节点4,其次是3的右节点4的左节点又指向了3的左节点2,这段话挺绕,但写出程序就很好理解:
pre->left = curr->right; //上一级节点左节点指向了本级的右节点
curr->right->left = curr->left; //本级的右节点的左节点指向了本级的左节点
delete curr; //删除本级节点
以上我们删除的是一个节点的左节点,如果要删除一个节点的右节点(例如节点6)呢?你可能会这么想(如下代码),但这么想虽然也对,但写起来程序就复杂多了,需要分情况处理。其实,还是套用上面的处理就可以,大家可以用笔试一下!
pre->right = curr->left;
curr->left->right = curr->right;
delete curr;
不过实际操作起来还有很多细节问题要处理,比如3没有左或右节点该怎么办?4的左节点不为空怎么办?如果要删除根节点5怎么办?所以删除节点还是一个复杂的技术活!
下面给出基于迭代方法的节点删除代码:
//删除一个节点
TreeNode* deleteOneNode(TreeNode* root)
{
if(!root)
return NULL;
if(!root->right) //如果右节点为空,则直接返回左节点
return root->left;
TreeNode* temp = root->right; //准备将右节点的左节点指向了本级的左节点
while(temp->left) //这里就是为了处理左节点不为空的情况,既然你不为空,那么我就一直往下,直到你为空为止
temp = temp->left;
temp->left = root->left;
temp = root->right;
delete root;
return temp;
}
//如果要删除的节点位于二叉树中,则删除该节点;若不位于,则不处理
TreeNode* deleteNode(TreeNode* root, int key)
{
TreeNode* curr = root;
TreeNode* pre = NULL;
while(curr)
{
if(curr->val == key)
break;
else if(curr->val > key)
{
pre = curr;
curr = curr->left;
}
else
{
pre = curr;
curr = curr->right;
}
}
//如果要删除的节点不存在,则上面退出时curr = NULL;
if(!pre) //删除的是根节点的情况
return deleteOneNode(curr);
//这里并没有根据pos而是使用大小来区分方向
if(pre->val > key)
pre->left = deleteOneNode(curr);
else
pre->right = deleteOneNode(curr);
return root;
}
通过上面四个小节的学习,大家应该已经对二叉树以及二叉树的处理操作有了基本的认知。关于二叉树的内容仍然还有很多,就留给各位读者后面自行学习了~本文章到此就正式结束了,谢谢各位读者的观看!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









