




前序
现在有一组数据,

然后要从这组数组中找到某个数,比如要查找数7,一般来说,逐个逐个来查找的话,那么时间复杂度就是O(n),
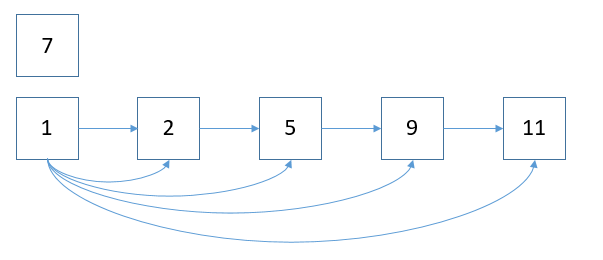
当n的数量达到上百万,或上千万时,那性能是非常差的,在我们系统中是不能接受的。
也许我们想到了hash,平衡二叉树结构来提高性能,今天我们来讲另一个结构:跳跃表-skiplist。
比如二叉树,它会提取一些节点作为树的根节点,当然这里树指整棵树也指树的子树,类似地,我们跳跃表也可以提取出一些关键节点出来,
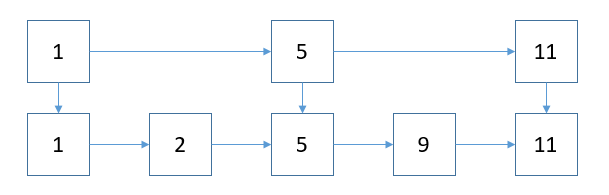
像上图,我们提取1,5,11节点出来,则这里跳跃表的最大层次高度为2。
再用上面的例子,那我们查找7的话,如何查找?
查找
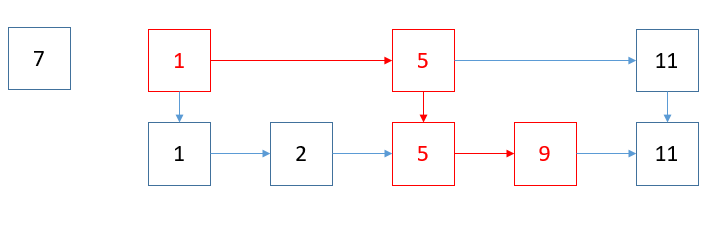
我们从最大高度的开始找起,首先从1节点开始,7比1大,则找1的下一个节点,从1节点的最高高度找到它的下一个节点节点5(如果7比最高高度的下一节点数少,则从1节点的最高高度往下降一高度的下一节点比较),7比5大,则在当前高度,打5的下一节点11,7比11小,则5的高度降小一级,找5的0高度的下一节点9,7比9小,则结束了,没有找到。
路径为:(1)->(5)->(9)
跳跃表通过关键节点的比较,和跳跃表高度的下一节点比较,时间复杂度为O(log2(n)。空间复杂度为O(2n)。
添加
现我们需要添加元素时,比如添加12,17:
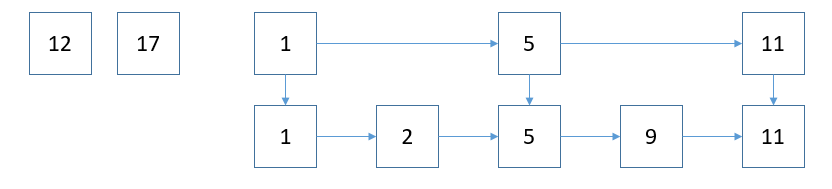
添加到跳跃表后,
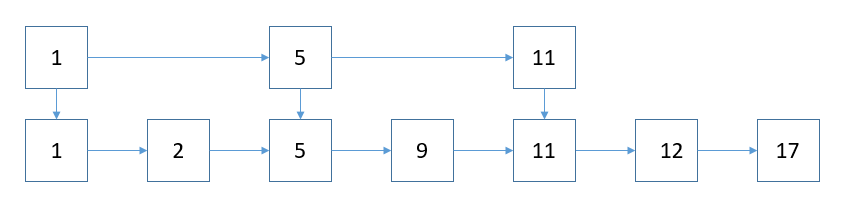
新的元素添加到跳跃表后,是否需要提取出新的关键节点,通过抛硬币,正面则提取关键节点,是否提取关键节点,可参照的说明Skip_list。
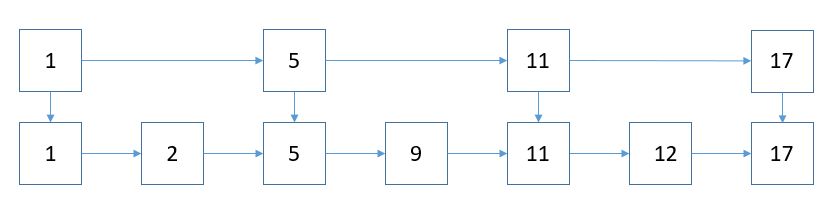
再提取
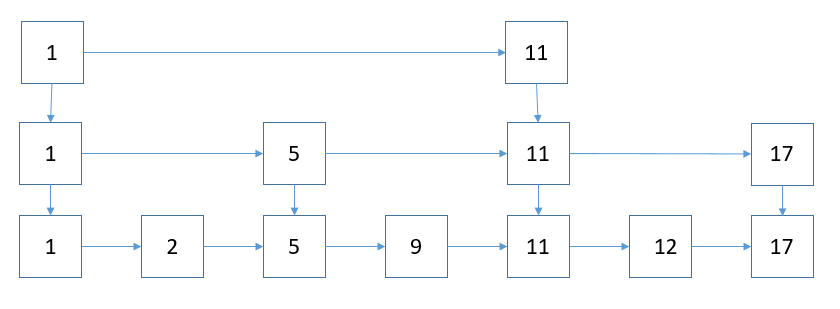
删除
删除节点则移除相关节点,相关的下一节点也移除,添加和删除节点,跳跃表维护比较简单,不像红黑树需要重新维护红黑树平衡,左旋,右旋,变色等等操作。
skip list:
https://en.wikipedia.org/wiki/Skip_list

















 265
265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









