




 博客介绍了几种常见字符编码。ASCII是美国编码,一个字节;GB2312是中国编码,一般2个字节;unicode编码统一各国编码,一般4字节,解决乱码但开销大;UTF - 8可变长度,节省空间但增加复杂度。还提到python3内置unicode编码,给出了合理使用建议。
博客介绍了几种常见字符编码。ASCII是美国编码,一个字节;GB2312是中国编码,一般2个字节;unicode编码统一各国编码,一般4字节,解决乱码但开销大;UTF - 8可变长度,节省空间但增加复杂度。还提到python3内置unicode编码,给出了合理使用建议。
- ASCII: 美国的编码, 一个字节, 最大只能表示255个字符
- GB2312: 中国制定的编码。一般2个字节
- unicode编码,目的是统一各国编码, 一般4字节。 解决了乱码问题, 但是也需要更多的存储空间,传输时也需要传输更多,产生更多开销。
- UTF-8: 可变长度的编码, 比如一个英文字符,只占用1个字节,中文3个字节。作用比较明显。缺点就是增加复杂度
python3将所有字符内置为unicode编码了。
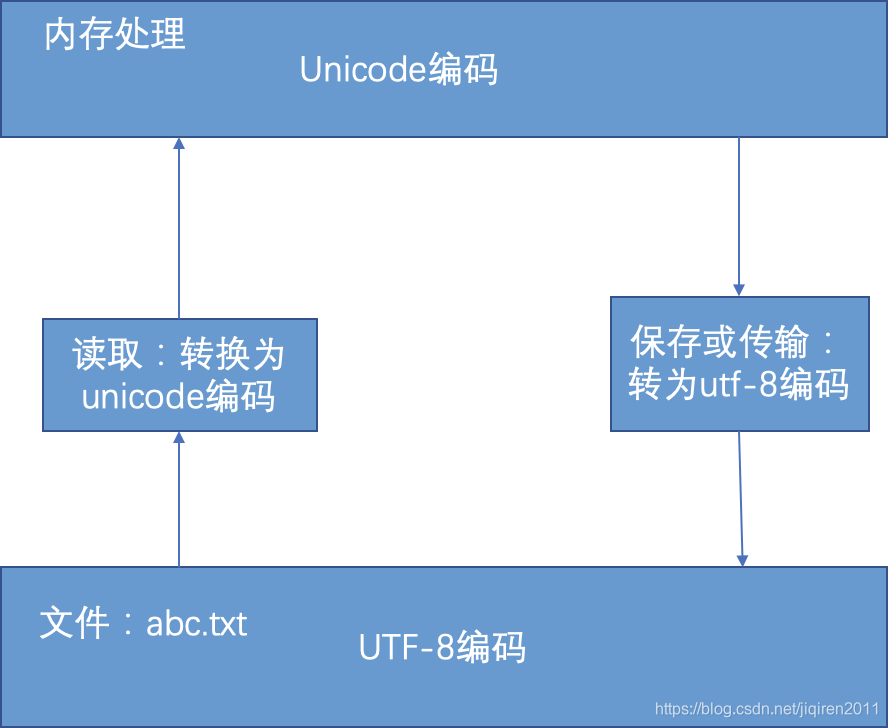
因为unicode编码长度固定,在中英文混合的情况下,内部处理比utf-8容易,而utf-8能够根据不同字符使用不同的长度编码,所以更节省空间, 实际中,可以像如下图一样进行处理, 达到合理使用:

















 986
986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









