






 本文介绍了使用Python进行中文分词词性标注和词频统计的项目,涉及金融文本处理,包括去除停用词、正则过滤、词性标注、词频统计及数据保存为Excel。
本文介绍了使用Python进行中文分词词性标注和词频统计的项目,涉及金融文本处理,包括去除停用词、正则过滤、词性标注、词频统计及数据保存为Excel。
基于Python的中文分词词性标注词频统计的实现
今天是2018年10月22号,小亮继续着自己深度学习与自然语言处理的打怪升级之路。今天给大家介绍一下最近接的小项目,基于Python的中文分词词性标注词频统计的实现,在这里与大家交流一下!
笔者信息:Next_Legend QQ:1219154092 机器学习 自然语言处理 计算机视觉 深度学习
小亮的博客:https://legendtianjin.github.io/NextLegend.github.io/ ——2018.10.22 于北洋
一、项目需求
该项目的背景领域是金融工程,处理语料是中文的金融方向的txt书籍,目的是检测出书中的名词与动词等关键信息,并标注词性、统计词频等信息,最后导出数据为Excel格式。下图是需要处理的txt文本数据以及小亮自己找的停用词文本:


二、需求分析
小亮并没有急于上手开始做项目,而是先分析了一下项目需求,其实主要的流程就是输入数据——>数据预处理——>词性标注(包含了分词)——>词频统计——>数据再次处理——>数据保存为Excel。其中中前后两部分的数据处理考验基本的Python数据结构能力,这部分可能得花一部分时间考虑。然后最难得部分是先做词性标注还是词频统计的顺序问题,刚开始小亮并没有考虑,只是先做了几个小样本的测试,结果到后面数据处理部分非常之麻烦,所以小亮百思终得其姐(解),先处理词性标注,再处理词频统计,从根本上说,词频统计其实也是数据处理问题,而不是自然语言处理(NLP)问题。
三、项目过程
(1) 导入相关的库

(2) 读取中文语料数据

(3) 去除停用词


(4) 正则表达式过滤非中文字符
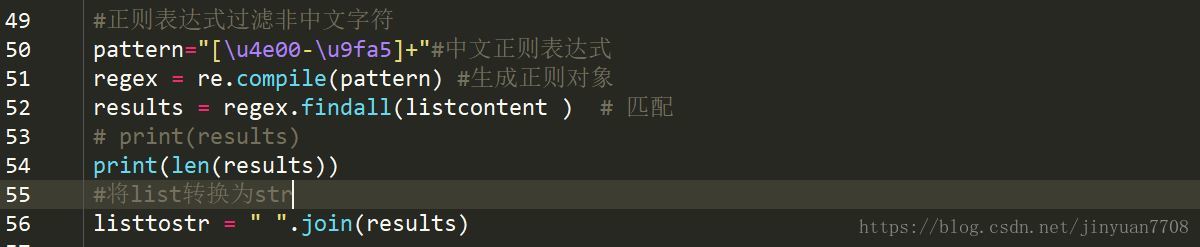
(5) 词性标注
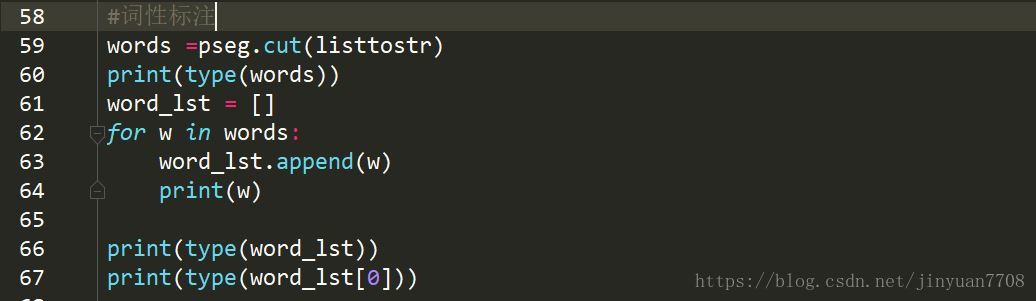
(6) 去除结果中的空格等现象

(7) 词频统计

(8) 数据二次处理整合

(9) 保存数据为Excel格式

四、项目结果
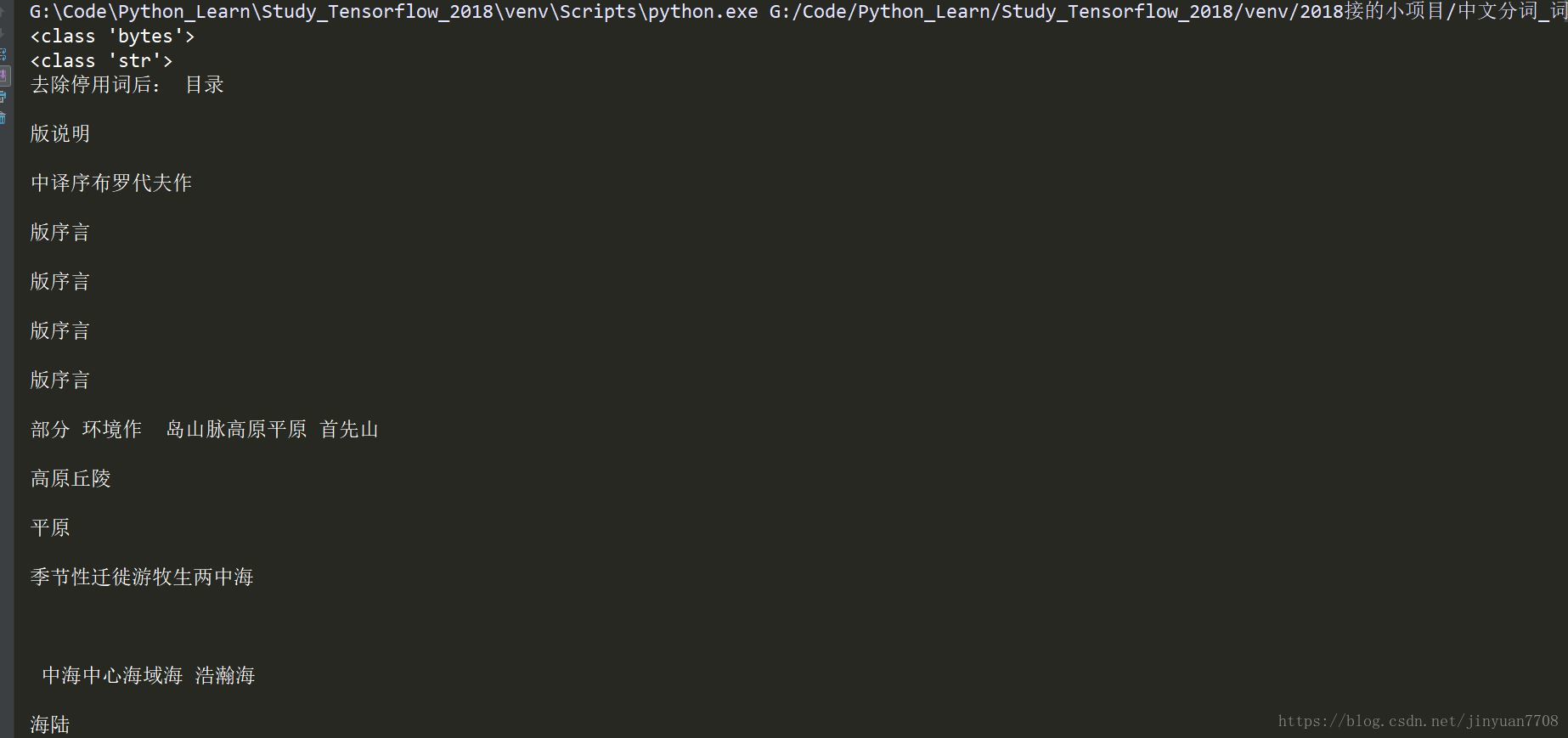
(1) 去除停用词后的结果
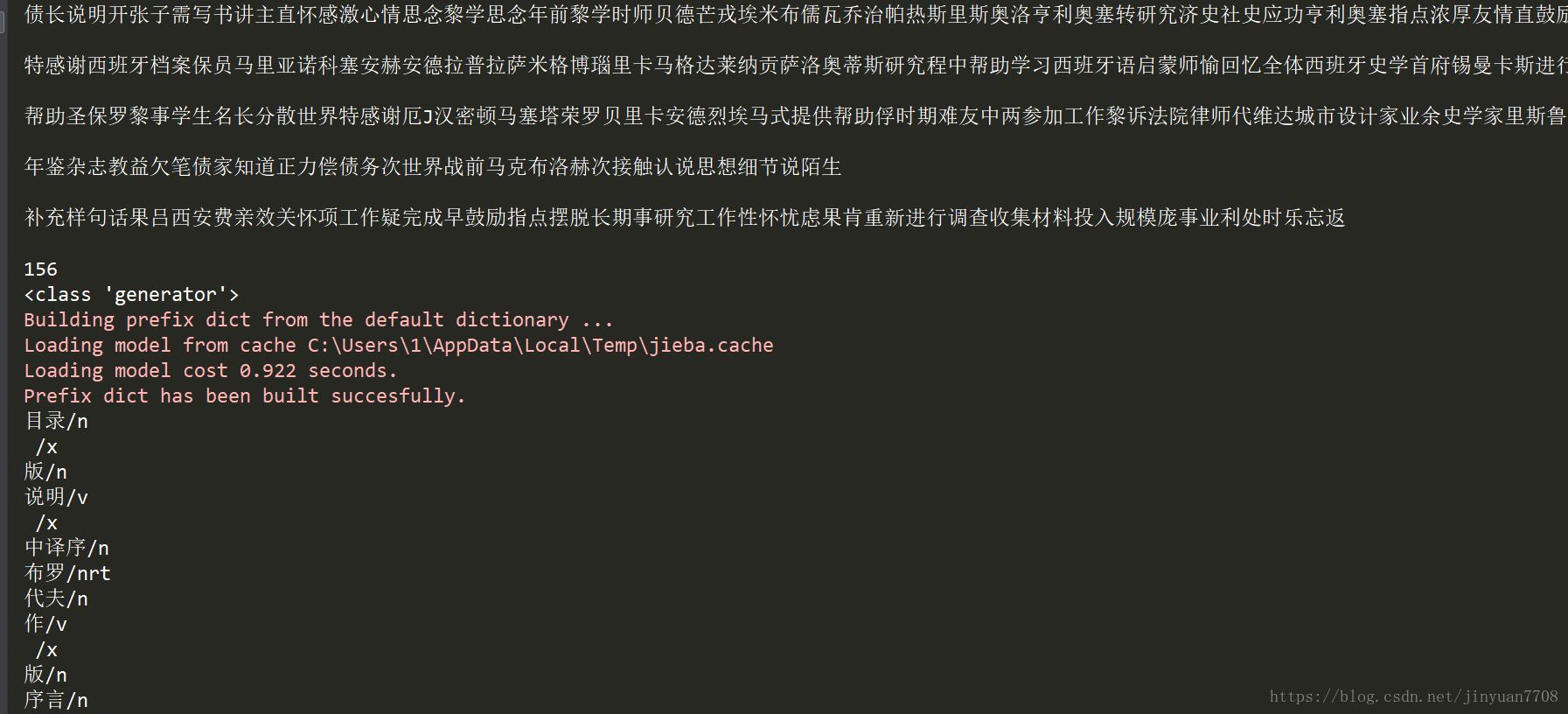
(2) 词性标注结果
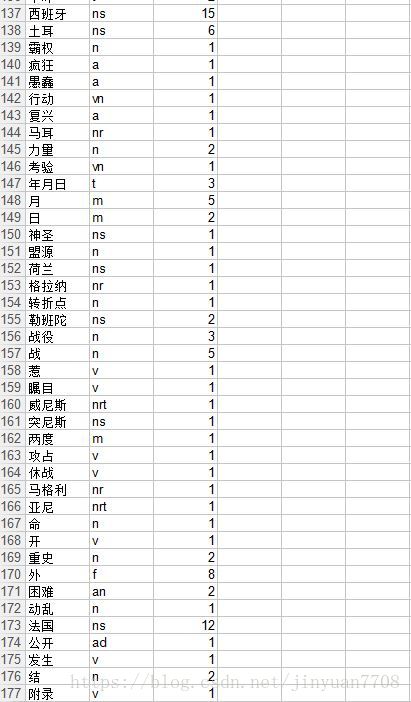
(3) 词频统计结果

(4) Excel结果



















 808
808











 到【灌水乐园】发言
到【灌水乐园】发言







