







 本文介绍了CPU的存储器层次结构,强调了缓存行(Cacheline)在多核CPU中引发的数据一致性问题。通过 MESI 协议解释了解决方案,同时探讨了缓存行对齐以避免伪共享的问题。此外,还讨论了CPU的乱序执行机制,包括X86架构下的内存屏障和原子指令,以及它们在保证执行顺序和数据可见性方面的作用。最后,提到了JVM级别的内存模型(JMM)和相关规范,如JSR133,以确保多线程环境下的正确性。
本文介绍了CPU的存储器层次结构,强调了缓存行(Cacheline)在多核CPU中引发的数据一致性问题。通过 MESI 协议解释了解决方案,同时探讨了缓存行对齐以避免伪共享的问题。此外,还讨论了CPU的乱序执行机制,包括X86架构下的内存屏障和原子指令,以及它们在保证执行顺序和数据可见性方面的作用。最后,提到了JVM级别的内存模型(JMM)和相关规范,如JSR133,以确保多线程环境下的正确性。
目录
2.2 数据一致问题怎么解决(总线锁+一致性协议 混合模式)
JMM(Java Memory Mode)
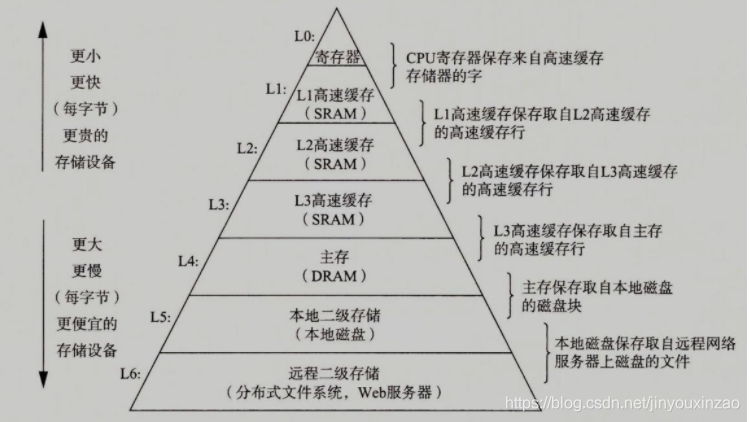
1、存储器的层次结构图
其中L0 L1 L2是CPU独有的,L3以上对于多个CPU来说是共享的。读数据的时候是自上而下,就近原则。
2、缓存行(Cache line)
2.1 什么是缓存行问题
计算机内部缓存的最小单位是行,一般是64字节(512为),那么比如我们定义了两个变量 int a,b;这两个变量一共占8字节,我们先假设他存储在同一行,当CPU执行指令用到这两个变量的时候,如上图,先回读取到自己的私有缓存L2或L1,缓存的单位是一行,同理另一个CPU要用的时候也是这个流程,这时两个CPU之间就会有一个数据一致性问题,这就是缓存行问题。
2.2 数据一致问题怎么解决(总线锁+一致性协议 混合模式)
总线锁:比较老的CPU都是通过总线锁(Bus)来解决的,但是总线锁有个问题,因为总线锁锁了以后,不光ab两个变量拿不到,所以用到的变量都拿不到了。
一致性协议 (也叫缓存锁)MESI(Modified Exclusive Shared Invalid) Cache:
大致意思是这样的:MESI是四种状态,如果当前线程修改了某个值(和主存不一样),这个值的状态标记为Modified,那在其他线程里就是Invalid;如果这个值我独享,标记为Exclusive;如果我在读别的线程也在读,标记为Shared.
注意:缓存一致性协议有很多,MESI还是其中一种,因为Intel用的是MESI,一般我们都指这个协议,这个缓存锁只能解决部分问题,比如有些数据分布在多个缓存行,依然要使用总线锁
2.3 缓存行对齐解决额外消耗
伪共享:位于同一缓存行的两个毫不相干的变量被修改时相互影响
问题:由于缓存的是一行,那么只要这行的某一个变量修改了,整个行都会被认为修改了,所以就需要把整行数据写回主从,并通知其他线程作废数据,重新读取。而实际上修改的值可能其他线程并没有用到。这种也
解决:通过缓存行对齐的方式,比如long类型的变量一个占8字节,在定义这个变量的前后都定义七个long类型的变量,这样就可以保证,不管在头尾,都是一个独立的缓存行,不会因为别的线程修改其他变量而导致CPU的私有缓存和共享缓存之间的频繁读写。其实就是一个变量占用了一行。 好处是提高了效率,坏处是浪费空间。
3、CPU的乱序执行
乱序执行的概念:比如CPU一次性从内存中读取了一组指令,比如10个指令,执行第一个指令的时候发现需要用到一个变量,这个变量在自己的高速缓存里没有,这时就要去内存中读取,如果是顺序执行,后面的9个指令就要等着,由于CPU高速缓存的速度比从内存读取的速度快进100倍。就会严重影响效率。 乱序执行就是在第一条在读取变量的过程中,CPU会分析其他指令,如果和指令1没有依赖关系,就会单独执行。 可以理解为CPU内部的并行策略。 这是读乱序。写乱序:是在L0和L1之间还有一个更加高效的缓存区WriteCombinBuffer(只有四字节),够四个再写到L1。
3.1 硬件上如何保证不乱序
X86的CPU 硬件内存屏障
相关博客:https://www.jianshu.com/p/c6f190018db1
sfence:在sfence(store fence)指令前的写操作 应当必须在sfence指令后的写操作完成之前执行(说白了就是如果某两个指令必须有序执行,那么就在两个指令之间加一个sfence屏障,上面的没有执行之前下面的指令不能继续执行)
Ifence:在lfence(load fence)指令前的读操作当必须在ifence指令后的读操作之前完成。
mfence:在mfence(merge fence)指令前的读写操作当必须在mfence指令后的读写操作之前执行。
原子指令:如X86上的lock... 指令是一个Full Barrier,执行时会锁住内存子系统来确保执行顺序,甚至跨多个CPU,software locks 通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序。
3.2 JVM级别如何规范(JSR133)
LoadLoad屏障:
对于这样的指令集【Load1; LoadLoad; Load2】,由于中间有LoadLoad指令,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
StoreStore屏障:
对于这样的指令集【Store1; StoreStore; Store2】,由于中间有StoreStore指令,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
LoadStore屏障:
对于这样的指令集【Load1; LoadStore; Store2】,由于中间有LoadStore指令,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
StoreLoad屏障:
对于这样的指令集【Store1; StoreLoad; Load2】,由于中间有StoreLoad指令,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。

















 945
945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









