






一.下载地址
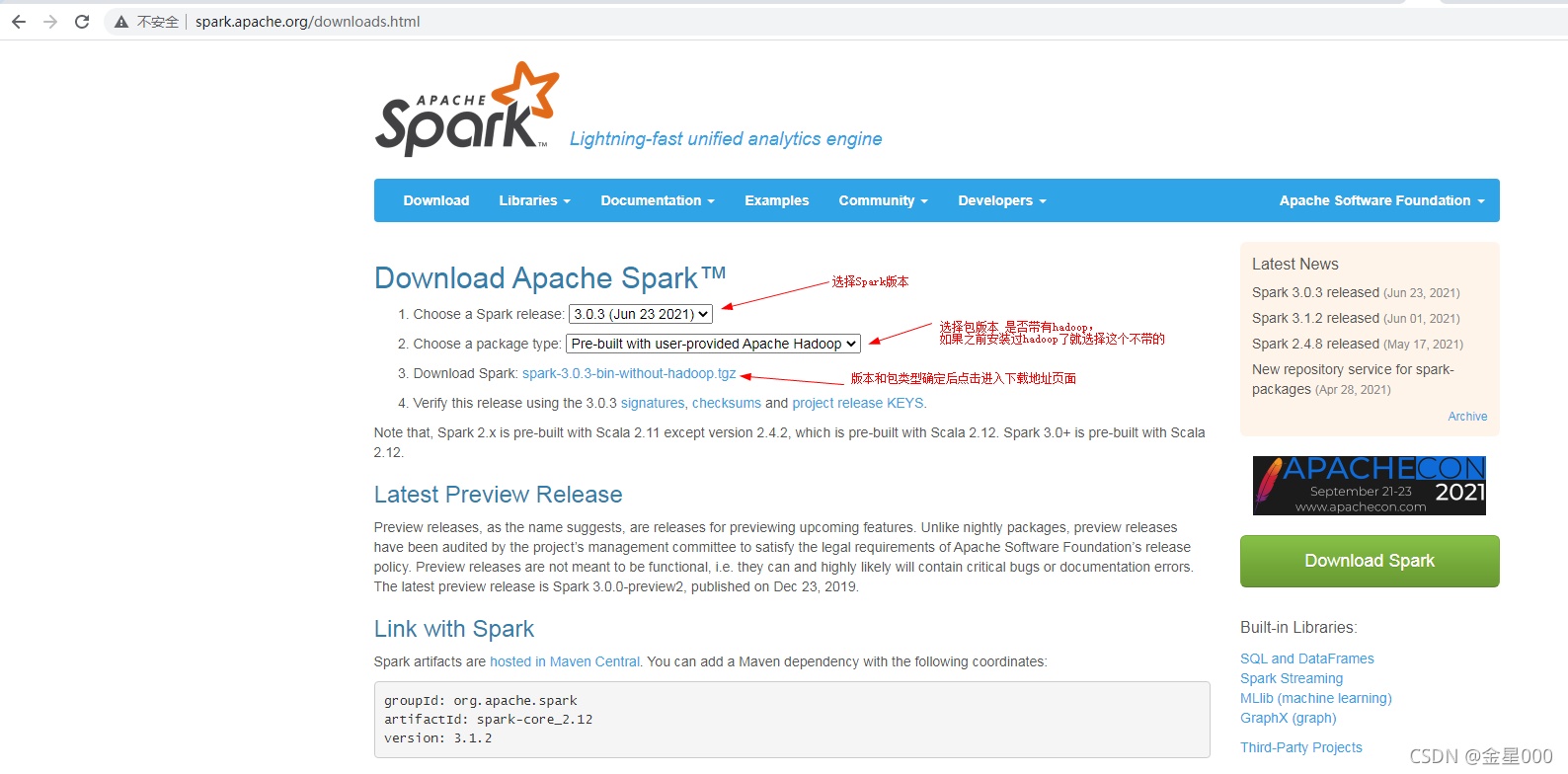
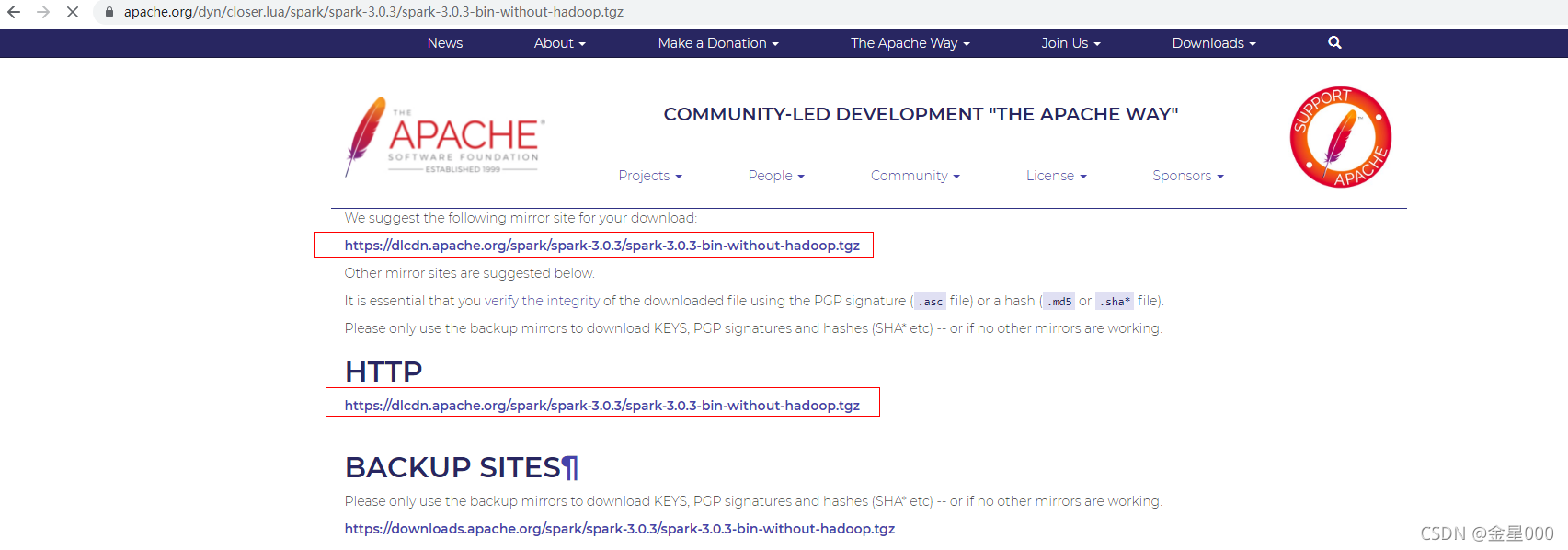
这里不直接下载到本地计算机,可以在linux下通过wget下载
在usr目录下 通过 mkdir spark创建spark目录,

![]()
在spark目录下执行下载
wget --no-check-certificate https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-3.0.3/spark-3.0.3-bin-hadoop2.7.tgz
下载到所在目录即可,然后进行解压 tar -zxvf spark-3.0.3-bin-hadoop2.7.tgz

进入解压后的目录spark-3.0.3-bin-hadoop2.7
想要使Spark能够使用Hadoop 中HDFS和HBase中的数据,需要进入conf下对其配置文件进行配置。

这里的spark-env.sh 是由 spark-env.sh.template 通过 cp spark-env.sh.template spark-env.sh 创建的。
vi spark-env.sh

在文件中增加以上配置内容,注意()中的路径根据你自己的hadoop路径调整。
:wq! 保存后
为了验证是否spark安装成功,可以执行自带实例运行
切换到spark的bin目录下

结果正常就说明安装成功了

















 605
605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









