







 本文介绍了自编码器(Auto-Encoder, AE)的基本概念、分类,如稀疏自编码(SAE)、降噪自编码(DAE)等,并提供了使用TensorFlow实现的AE实例,包括参数设置、编码器解码器结构、损失函数和优化器。通过实践,逐步解释了如何训练一个简单的AE模型以及栈式自编码器的概念。"
131180250,18852486,OpenCV中的击中击不中变换处理,"['计算机视觉', 'opencv', '图像处理']
本文介绍了自编码器(Auto-Encoder, AE)的基本概念、分类,如稀疏自编码(SAE)、降噪自编码(DAE)等,并提供了使用TensorFlow实现的AE实例,包括参数设置、编码器解码器结构、损失函数和优化器。通过实践,逐步解释了如何训练一个简单的AE模型以及栈式自编码器的概念。"
131180250,18852486,OpenCV中的击中击不中变换处理,"['计算机视觉', 'opencv', '图像处理']
自编码器(AE)的介绍及实现。
(原文发表在我的博客,欢迎访问
0x00.介绍
自编码(Auto-Encoder),简称ae,又有sae(稀疏自编码,Sparse Auto-Encoder)、dae(降噪自编码,Denoising Auto-Encoder)、rae(惩罚自编码,Regularized Auto-Encider)等分类。
基本的自编码网络可以看作一个由x->x的映射。它总共有两层神经网络,其中一层叫做encoder,另一层叫做decoder,即编码与解码。我们的输入x首先通过编码映射为h,之后h通过解码映射为y,我们要使x与y尽量接近。通常编码器与解码器的激活函数使用sigmoid函数(解码器有时候也使用恒等函数),损失函数使用平方误差或是交叉熵。以此我们计算损失函数。
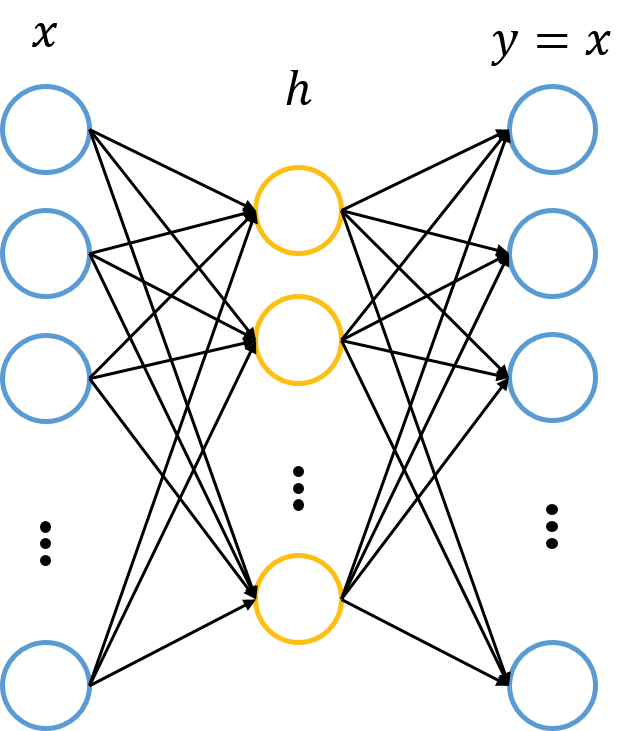
自编码神经网络属于序列到序列,主要用于特征的提取。常用自编码分类有:
- ae,正常的自编码,就是加强的pca(主成分分析)。
- sae,稀疏自编码。隐含层维数大于输入维数。
- dae,降噪自编码。给输入序列增加噪声,并添加dropout层。
- rae,惩罚自编码。增加惩罚项,使权重不会过大。
还有一种比较重要的自编码叫做栈式自编码(Stacked Auto-Encoder),对于一个基本的自编码器x->h->x,h可以看作为对特征的提取;如果将h看作原始信息,继续训练新的自编码器;以此类推,就叫做栈式自编码(stacked)。这种编码方式采用的是逐层训练。
0x01.实践
下面是网上的一个小的示例,是一个简单基本的自编码器。
这里以tensorflow的mnist数据作为输入,不过我们输入的是一个序列而不是矩阵(图像)。我们知道自编码器输入与输出相同,所以这里为序列到序列,即比较输出序列与输入序列的误差。
1.基本参数
# Network Parameters
# 神经元数量,这里通常为256、128
n_hidden_1 = 256 # 1st layer num features
n_hidden_2 = 128 # 2nd layer num features
# 这里为mnist的大小,28x28=784
n_input = 784 # MNIST data input (img shape: 28*28)
# tf Graph input (only pictures)
# 输入
X = tf.placeholder("float", [None, n_input]) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 704
704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









