







Java编程规范
- 1、不使用BigDecimal的equals方法做等值比较
- 2、不使用double直接构造BigDecimal
- 3、不使用 Apache Beanutils进行属性的copy
- 4、日期格式化时使用y表示年,而不用Y
- 5、不使用 count(列名)或 count(常量)来替代 count(*)
- 6、使用三目运算符时必须要注意类型对齐
- 7、建议设置HashMap的初始化容量
- 8、不建议使用Executors创建线程池
- 9、不建议在for循环中使用“+”进行字符串拼接
- 10、不在for each循环里进行元素的remove/add操作
- 11、不直接使用日志系统(Log4j、Log back) 中的API
- 12、不把SimpleDateFormat定义成static变量
- 13、不建议修改serialVersionUID 字段的值
- 14、谨慎使用继承
- 15、不使用is Success作为变量名
- 16、数据库字符个数判断
1、不使用BigDecimal的equals方法做等值比较
原因:equals方法会比较两部分内容,分别是值(value)和标度(scale)。
在使用BigDecimal的equals方法对1和1.0进行比较的时候,
有的时候是true(当使用int、double定义BigDecimal时),
有的时候是false(当使用String定义BigDecimal时)。
BigDecimal中提供了compareTo方法,这个方法就可以只比较两个数字的值,如果两个数相等,则返回0。
BigDecimal bigDecimal1 = new BigDecimal("1");
BigDecimal bigDecimal2 = new BigDecimal("1.0000");
System.out.println(bigDecimal1.compareTo(bigDecimal2));
//输出结果为0
2、不使用double直接构造BigDecimal
原因:BigDecimal(Double)存在精度损失风险,在精确计算或者值比较的场景中可能会导致业务逻辑异常。
BigDecimal是通过一个”无标度值”和一个”标度”来表示一个数的。
通过scale字段来表示标度。
(如123.123,如果使用BigDecimal表示,那么他的无标度值为123123,他的标度为3。)
- 如果scale为零或正值,则该值表示这个数字小数点右侧的位数。
- 如果scale为负数,则该数字的真实值需要乘以10的该负数的绝对值的幂。 例如,scale为-3,则这个数需要乘1000,即在末尾有3个0。
当我们使用new BigDecimal(0.1)创建一个BigDecimal 的时候,其实创建出来的值并不是正好等于0.1的。而是0.1000000000000000055511151231257827021181583404541015625。这是因为doule自身表示的只是一个近似值。
所以,若**要创建一个精确的BigDecimal来表示小数,使用String创建**。
而对于BigDecimal(String) ,当我们使用new BigDecimal(“0.1”)创建一个BigDecimal 的时候,其实创建出来的值正好就是等于0.1的。
3、不使用 Apache Beanutils进行属性的copy
原因:Apache Beanutils性能较差,可以使用其他方案比如 Spring BeanUtils、Cglib BeanCopier进行属性拷贝,注意均是浅拷贝。
性能比较:
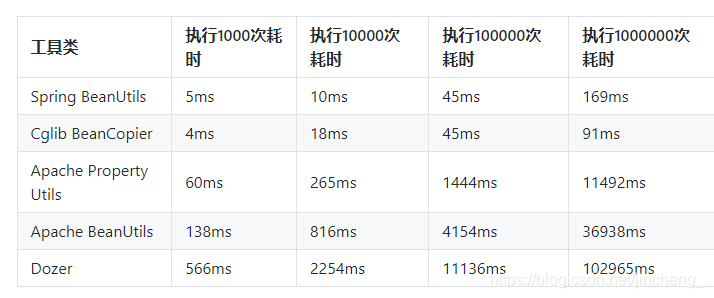
综上,可得出结论,在性能方面,Spring BeanUtils 和 Cglib BeanCopier 表现比较不错,而Apache PropertyUtils、Apache BeanUtils以及Dozer则表现的很不好。
但是,如果不单单考虑性能,像 Dozer ,性能比较差,但是他可以很好的和Spring结合,可以通过配置文件等进行属性之间的映射等,也受到了很多开发者的喜爱。
4、日期格式化时使用y表示年,而不用Y
原因:日期格式化后,yyyy表示当天所在的年,而大写的YYYY代表的是week in which year(JDK7之后引入的概念),
意思是当天所在的周属于的年份,一周从周日开始,周六结束,只要本周跨年,返回的YYYY就是下一年。
// Date转String
Date data = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String dataStr = sdf.format(data);
System.out.println(dataStr);
5、不使用 count(列名)或 count(常量)来替代 count(*)
原因:不要使用count(列名)或者count(常量)来代替count(*),count(*)是
SQL92定义的标准统计行数的语法,跟数据库无关,跟null非null无关。
说明:count(*)会统计值为null的行,count(列名)不会统计此列为null的行。
count函数主要用法有COUNT(*)、COUNT(字段)和COUNT(1)。
因为COUNT(**) 是SQL92定义的标准统计行数的语法,所以MySQL对他进行了很多优化,MyISAM中会直接把表的总行数单独记录下来供COUNT(*)查询,而InnoDB则会在扫表的时候选择最小的索引来降低成本。当然,这些优化的前提都是没有进行where和group的条件查询。
在InnoDB中COUNT(*)和COUNT(1)实现上没有区别,而且效率一样,但是COUNT(字段)需要进行字段的非NULL判断,所以效率会低一些。
因为COUNT(**)是SQL92定义的标准统计行数的语法,并且效率高,所以最好直接使用COUNT(*)查询表的行数。
6、使用三目运算符时必须要注意类型对齐
原因:三目运算符condition?表达式1:表达式2中,要高度注意表达式1和2在类型对
齐时,可能抛出的因为自动拆箱导致的NPE异常。(NullPointerException空指针异常)
说明: 以下两种场景会触发类型对齐的拆箱操作:
1.表达式1或表达式2的值有一个是原始类型
2.表达式1或表达式2的值类型不一致,会强制拆箱升级成表示范围更大的那个类型。
因此在开发过程中,如果涉及到三目运算符,那么就要高度注意其中的自动拆装箱问题。
最好的做法就是保持三目运算符的第二位和第三位表达式的类型一致,并且如果要把三目运算符表达式给变量赋值的时候,也尽量保持变量的类型和他们保持一致。并且,做好单元测试!!!
所以,我们不仅要高度注意第二位和第三位表达式的类型对齐过程中由于自动拆箱发生的NPE问题,其实还需要注意使用三目运算符表达式给变量赋值的时候由于自动拆箱导致的NPE问题。
7、建议设置HashMap的初始化容量
集合初始化时,指定集合初始值的大小。
否则JDK会默认帮我们计算一个相对合理的值当做初始容量。所谓合理值,其实是找到第一个比用户传入的值大的2的幂。(即3->4;9->16)
HashMap使用如下构造方法进行初始化,如果暂时无法确定集合大小,那么指定默认值(16)即可。
Map<String, String> map = new HashMap<String, String>(16);
8、不建议使用Executors创建线程池
原因:线程池避免使用Executors去创建,而是通过ThreadPoolExecutor的方式,
这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
Executors返回的线程池对象弊端如下:
1.FixedThreadPool和SingleThreadPool:
允许的请求队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM。(OutOfMemory ,内存溢出)
2.允许的创建线程数量为Integer.MAX_VALUE,可能会创建大量的线程,从而导致OOM。
避免使用Executors创建线程池,主要是避免使用其中的默认实现,那么可以自己直接调用ThreadPoolExecutor的构造函数来自己创建线程池。在创建的同时,给BlockQueue指定容量就可以了。
private static ExecutorService executor = new ThreadPoolExecutor(10, 10,
60L, TimeUnit.SECONDS,
new ArrayBlockingQueue(10));
9、不建议在for循环中使用“+”进行字符串拼接
推荐:循环体内,字符串的连接方式,使用StringBuilder 的append方法进行扩展。
常用的字符串拼接方式有五种,分别是使用+、使用concat、使用StringBuilder、使用StringBuffer以及使用StringUtils.join。
1.使用+
String wechat = "sfsfslis";
String introduce = "sdgsgg";
String hollis = wechat + "," + introduce;
2.concat
String wechat = "asdasdsa";
String introduce = "asdad";
String hollis = wechat.concat(",").concat(introduce);
3.StringBuffer
StringBuffer wechat = new StringBuffer("adalis");
String introduce = "sgsfhsfzc";
StringBuffer hollis = wechat.append(",").append(introduce);
4.StringBuilder
StringBuilder wechat = new StringBuilder("asdads");
String introduce = "asdasdad";
StringBuilder hollis = wechat.append(",").append(introduce);
5.StringUtils.join
String wechat = "cfbis";
String introduce = "gmghfh";
System.out.println(StringUtils.join(wechat, ",", introduce));
String []list ={"ssssllis","dfhdfh"};
String result= StringUtils.join(list,",");
System.out.println(result);
//结果:ssssllis,dfhdfh
直接使用StringBuilder的方式是效率最高的。因为StringBuilder天生就是设计来定义可变字符串和字符串的变化操作的。
但是,还要强调的是:
1、如果不是在循环体中进行字符串拼接的话,直接使用+就好了。
2、如果在并发场景中进行字符串拼接的话,要使用StringBuffer来代替StringBuilder。
10、不在for each循环里进行元素的remove/add操作
推荐:不在foreach循环里进行元素的remove、add操作。remove元素使用Iterator方
式,如果并发操作,需要对Iterator对象加锁。

fail-fast,即快速失败,它是Java集合的一种错误检测机制。当多个线程对集合(非fail-safe的集合类)进行结构上的改变的操作时,有可能会产生fail-fast机制,这个时候就会抛出ConcurrentModificationException(当方法检测到对象的并发修改,但不允许这种修改时就抛出该异常)。
同时需要注意的是,即使不是多线程环境,如果单线程违反了规则,同样也有可能会抛出改异常。
在for each循环里进行元素的remove/add操作则会抛出上述异常。
正确方式:
1、直接使用普通for循环进行操作
List<String> userNames = new ArrayList<String>() {{
add("Hollis");
add("hollis");
add("HollisChuang");
add("H");
}};
for (int i = 0; i < 1; i++) {
if (userNames.get(i).equals("Hollis")) {
userNames.remove(i);
}
}
System.out.println(userNames);
2、直接使用Iterator进行操作
List<String> userNames = new ArrayList<String>() {{
add("Hollis");
add("hollis");
add("HollisChuang");
add("H");
}};
Iterator iterator = userNames.iterator();
while (iterator.hasNext()) {
if (iterator.next().equals("Hollis")) {
iterator.remove();
}
}
System.out.println(userNames);
3、使用Java 8中提供的filter过滤
List<String> userNames = new ArrayList<String>() {{
add("Hollis");
add("hollis");
add("HollisChuang");
add("H");
}};
userNames = userNames.stream().filter(userName -> !userName.equals("Hollis")).collect(Collectors.toList());
System.out.println(userNames);
4、使用增强for循环其实也可以
如果,我们非常确定在一个集合中,某个即将删除的元素只包含一个的话, 比如对Set进行操作,那么其实也是可以使用增强for循环的,只要在删除之后,立刻结束循环体,不要再继续进行遍历就可以了,也就是说不让代码执行到下一次的next方法。
List<String> userNames = new ArrayList<String>() {{
add("Hollis");
add("hollis");
add("HollisChuang");
add("H");
}};
for (String userName : userNames) {
if (userName.equals("Hollis")) {
userNames.remove(userName);
break;
}
}
System.out.println(userNames);
5、直接使用fail-safe的集合类
在Java中,除了一些普通的集合类以外,还有一些采用了fail-safe机制的集合类。这样的集合容器在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。
由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所作的修改并不能被迭代器检测到,所以不会触发ConcurrentModificationException。
ConcurrentLinkedDeque<String> userNames = new ConcurrentLinkedDeque<String>() {{
add("Hollis");
add("hollis");
add("HollisChuang");
add("H");
}};
for (String userName : userNames) {
if (userName.equals("Hollis")) {
userNames.remove();
}
}
11、不直接使用日志系统(Log4j、Log back) 中的API
推荐:应用中不直接使用日志系统(Log4j、Log back) 中的API,而应依赖使用日志框架
SLF4J中的API,使用门面模式的日志框架,有利于维护和各个类的日志处理方式统一。
日志门面,是门面模式的一个典型的应用。
门面模式(Facade Pattern),也称之为外观模式,其核心为:外部与一个子系统的通信必须通过一个统一的外观对象进行,使得子系统更易于使用。
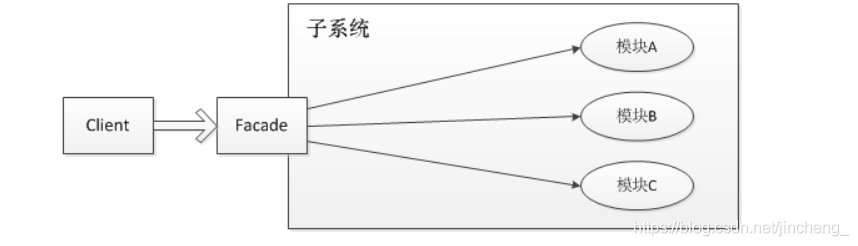
为什么需要日志门面
就是为了在应用中屏蔽掉底层日志框架的具体实现。这样的话,即使有一天要更换代码的日志框架,只需要修改jar包,最多再改改日志输出相关的配置文件就可以了。这就是解除了应用和日志框架之间的耦合。
12、不把SimpleDateFormat定义成static变量
原因:SimpleDateFormat是线程不安全的类,一般不要定义为static变量,如果定义
为static,必须加锁,或者使用DateUtils工具类。
13、不建议修改serialVersionUID 字段的值
类通过实现 java.io.Serializable 接口以启用其序列化功能。
原因:序列化类新增属性时,请不要修改serialVersionUID字段,避免反序列化失败,
如果完全不兼容升级,避免反序列化混乱,那么请修改serialVersionUID值。
说明:注意serialVersionUID不一致会抛出序列化运行时异常。
serialVersionUID有两种显示的生成方式:
一是默认的1L,比如:private static final long serialVersionUID = 1L;
二是根据类名、接口名、成员方法及属性等来生成一个64位的哈希字段,比如:
private static final long serialVersionUID = xxxxL;
14、谨慎使用继承
推荐:谨慎使用继承的方式来进行扩展,优先使用聚合/组合的方式来实现。
说明:不得已使用继承的话,必须符合里氏代换原则,此原则说父类能够出现的地方
子类一定能够出现,比如:“把钱交出来”,钱的子类美元、欧元、人民币等都可以出现。
Java代码的复用有继承,组合以及代理三种具体的表现形式。
15、不使用is Success作为变量名
原因:POJO类中布尔类型的变量,都不要加is,否则部分框架解析会引起序列化错误,
反例:定义为基本数据类型boolean isSuccess的属性,它的方法也是isSuccess(),
RPC框架在反向解析的时候,以为对应的属性名称是success,导致属性获取不到,进而抛出异常。
所以,在定义POJO中的布尔类型的变量时,不要使用isSuccess这种形式,而要直接使用success!
关于基本数据类型与包装数据类型的使用标准如下:
1.所有的POJO类属性必须使用包装数据类型
2.RPC方法的返回值和参数必须使用包装数据类型
3.所有的局部变量使用基本数据类型
说明:
POJO类属性没有初值是提醒使用者在需要使用时,必须自己显示的进行赋值,任何
NPE(java.lang.NullPointerException)问题,或者入库检查,都由使用者来保证。
正例:数据库的查询结果是null,因为自动拆箱,用基本数据类型接受有NPE风险。

所以,建议在POJO和RPC的返回值中使用包装类型,尽量避免在代码中出现不确定的null值。
16、数据库字符个数判断


















 2614
2614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









