



学习一个深度学习网络,就看三点,1. 网络架构 2.输入输出 3.损失函数
yolov1
2015年诞生的YOLOv1创造性地使用端到端结构完成了物体检测任务,把检测问题转换成了回归问题,直接预测物体的类别和位置。
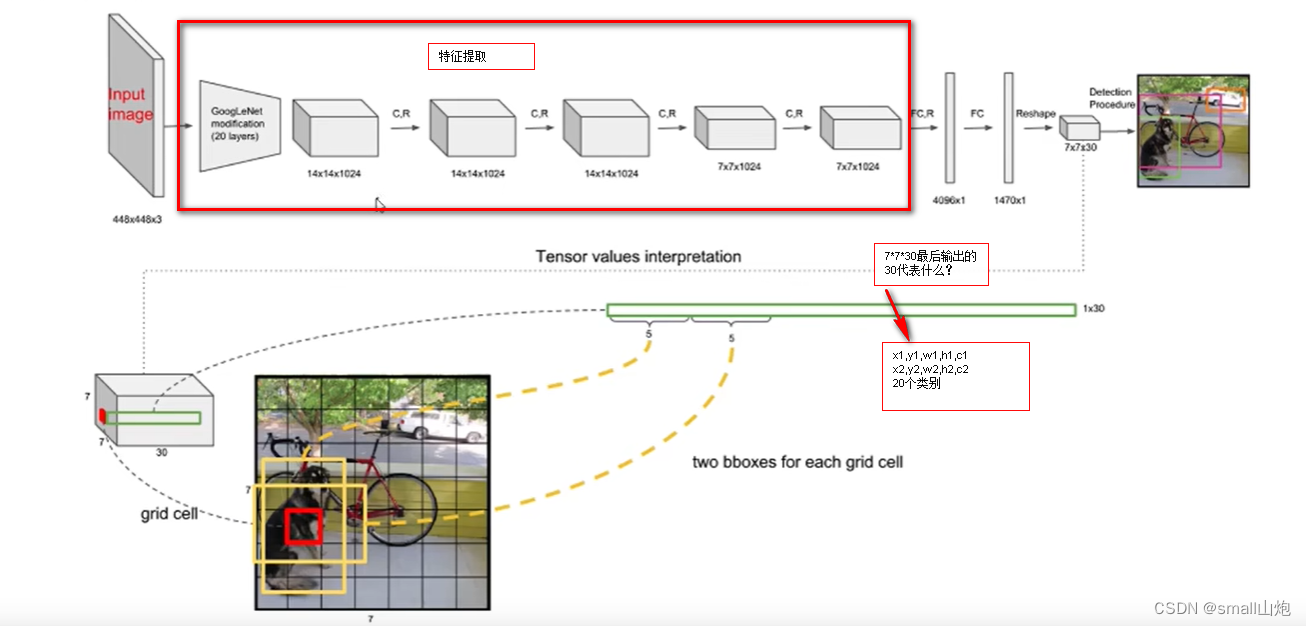
每个grid有30维,这30维中,8维是回归box的坐标,2维是box的confidence。x,y 代表中心点,; w,h代表宽高; c代表置信度,公式:
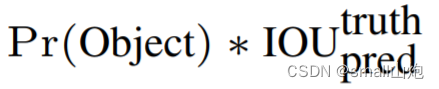
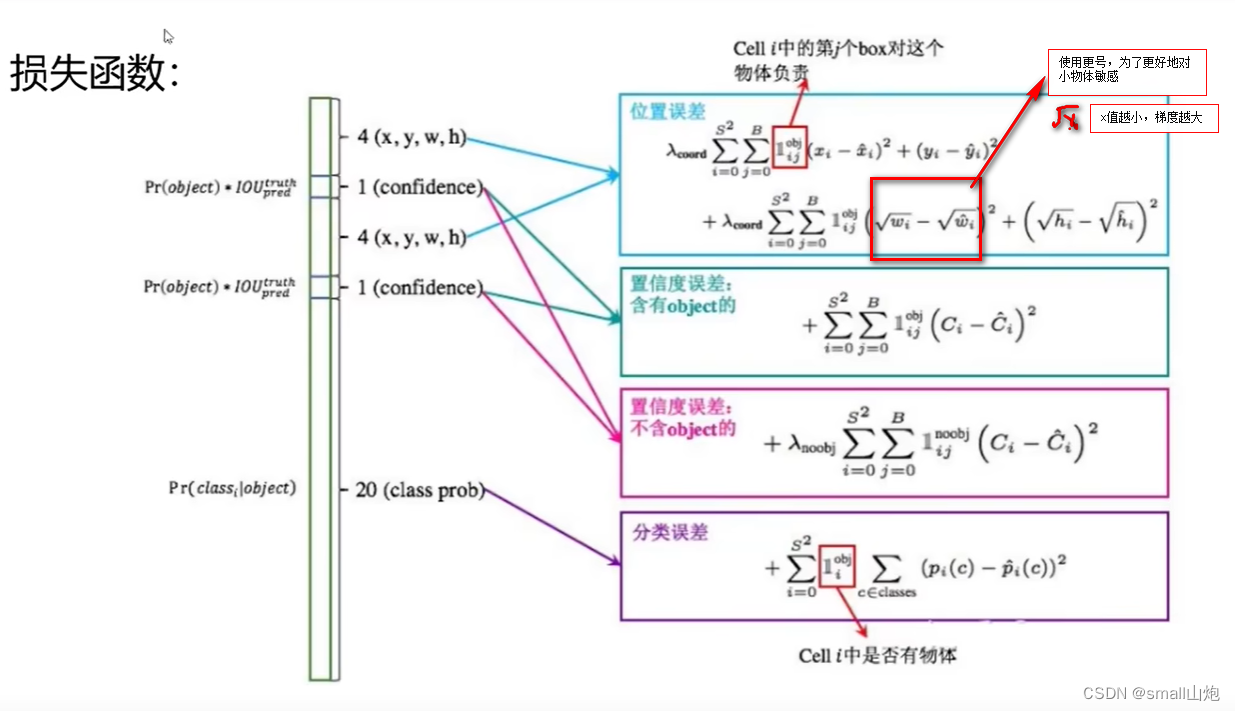
如果有object落在一个grid cell里,则第一项取1,否则取0。 第二项是预测的bounding box和实际的groundtruth之间的IoU值。
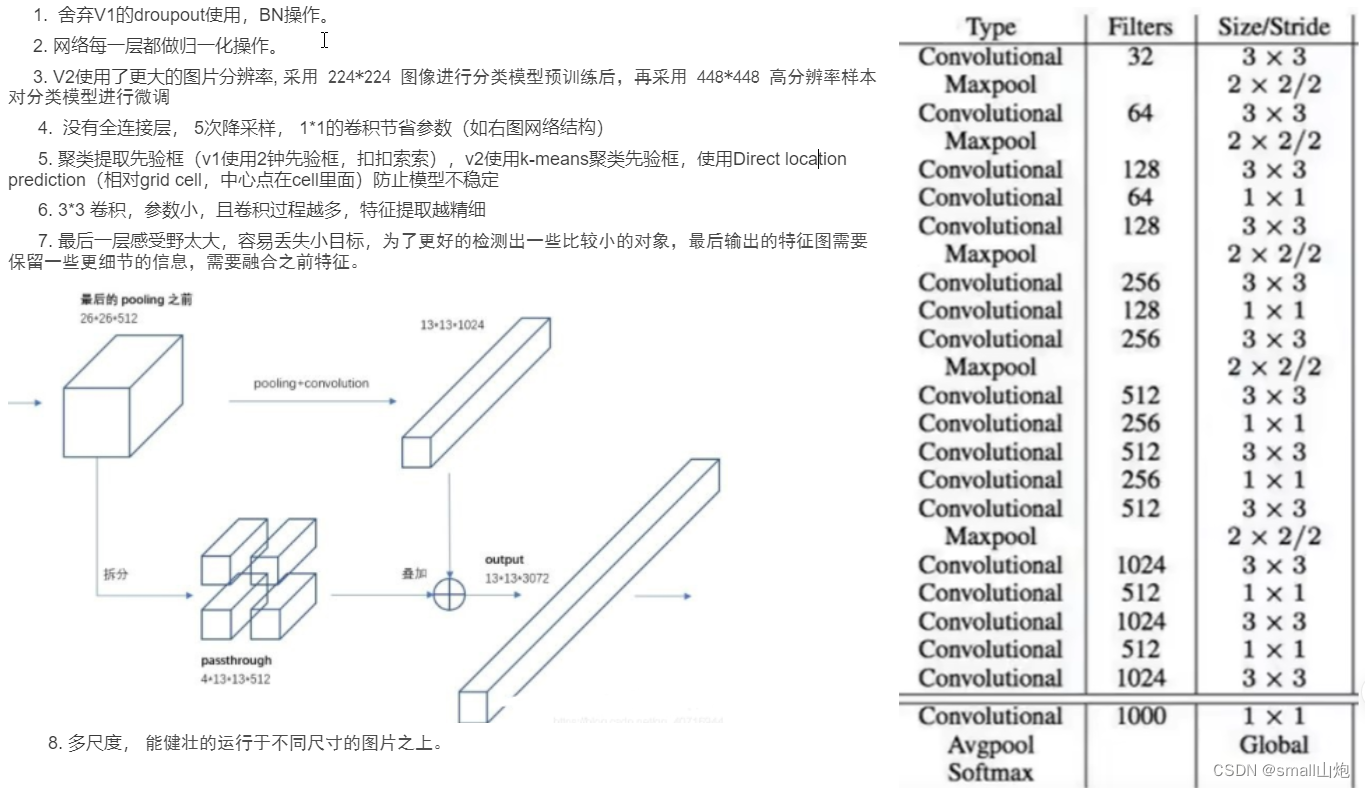
yolov2
yolov3
1. 利用3种scale特征进行目标检测,通常一幅图像包含各种不同的物体,并且有大有小。比较理想的是一次就可以将所有大小的物体同时检测出来。因此,网络必须具备能够“看到”不同大小的物体的能力。因为网络越深,特征图就会越小,所以网络越深小的物体也就越难检测出来。浅层的feature map中主要包含低级的信息(物体边缘,颜色,初级位置信息等),深层的feature map中包含高等信息(例如物体的语义信息:狗,猫,汽车等等)。因此在不同级别的feature map对应不同的scale,所以我们可以在不同级别的特征图中进行目标检测。
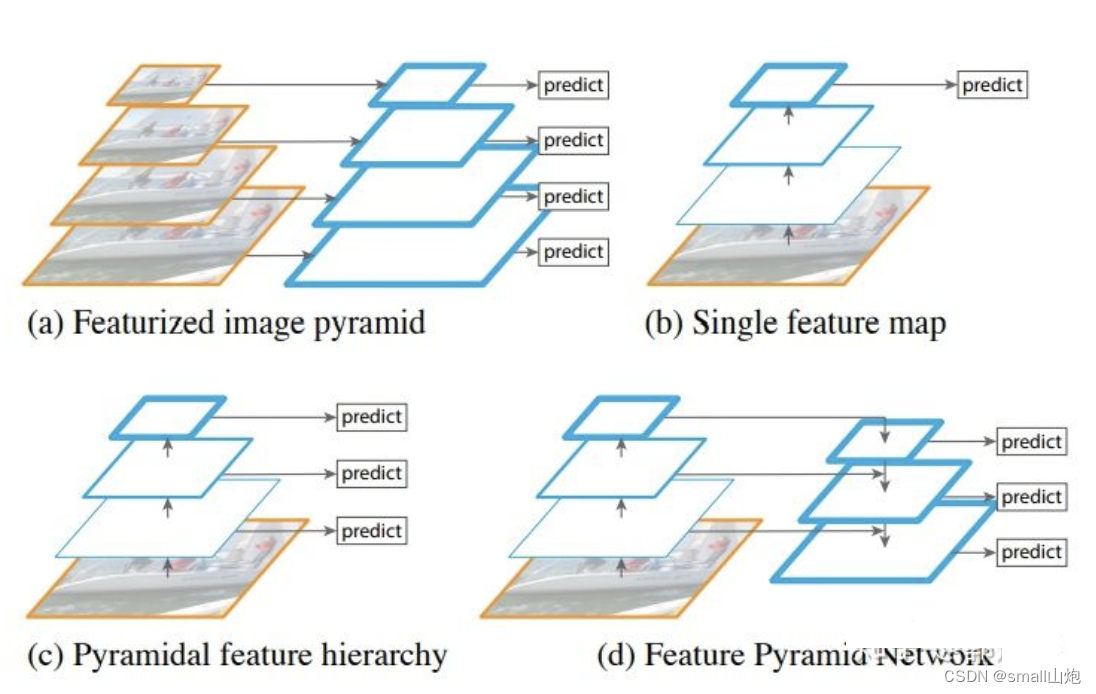
(a) 这种方法首先建立图像金字塔,不同尺度的金字塔图像被输入到对应的网络当中,用于不同scale物体的检测。但这样做的结果就是每个级别的金字塔都需要进行一次处理,速度很慢,在SPPNet使用的就是这种方式。
(b) 检测只在最后一层feature map阶段进行,这个结构无法检测不同大小的物体
(c) 对不同深度的feature map分别进行目标检测。SSD中采用的便是这样的结构。这样小的物体会在浅层的feature map中被检测出来,而大的物体会在深层的feature map被检测出来,从而达到对应不同scale的物体的目的,缺点是每一个feature map获得的信息仅来源于之前的层,之后的层的特征信息无法获取并加以利用。
(d) 与(c)很接近,但不同的是,当前层的feature map会对未来层的feature map进行上采样,并加以利用。因为有了这样一个结构,当前的feature map就可以获得“未来”层的信息,这样的话低阶特征与高阶特征就有机融合起来了,提升检测精度。在YOLOv3中,就是采用这种方式来实现目标多尺度的变换的。
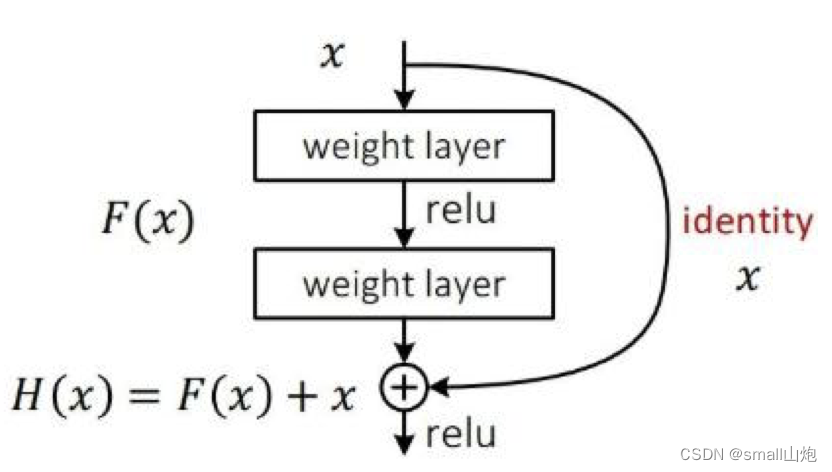
2. 采用了Darknet-53的网络结构(含有53个卷积层),它借鉴了残差网络ResNet的做法,在层之间设置了shortcut,来解决深层网络梯度的问题,shortcut如下图所示:包含两个卷积层和一个shortcut connections。
3. 先验框选取

4. 物体检测任务可能一个物体可能有多个标签 ,使用1x1的卷积层+logistic激活函数的结构。
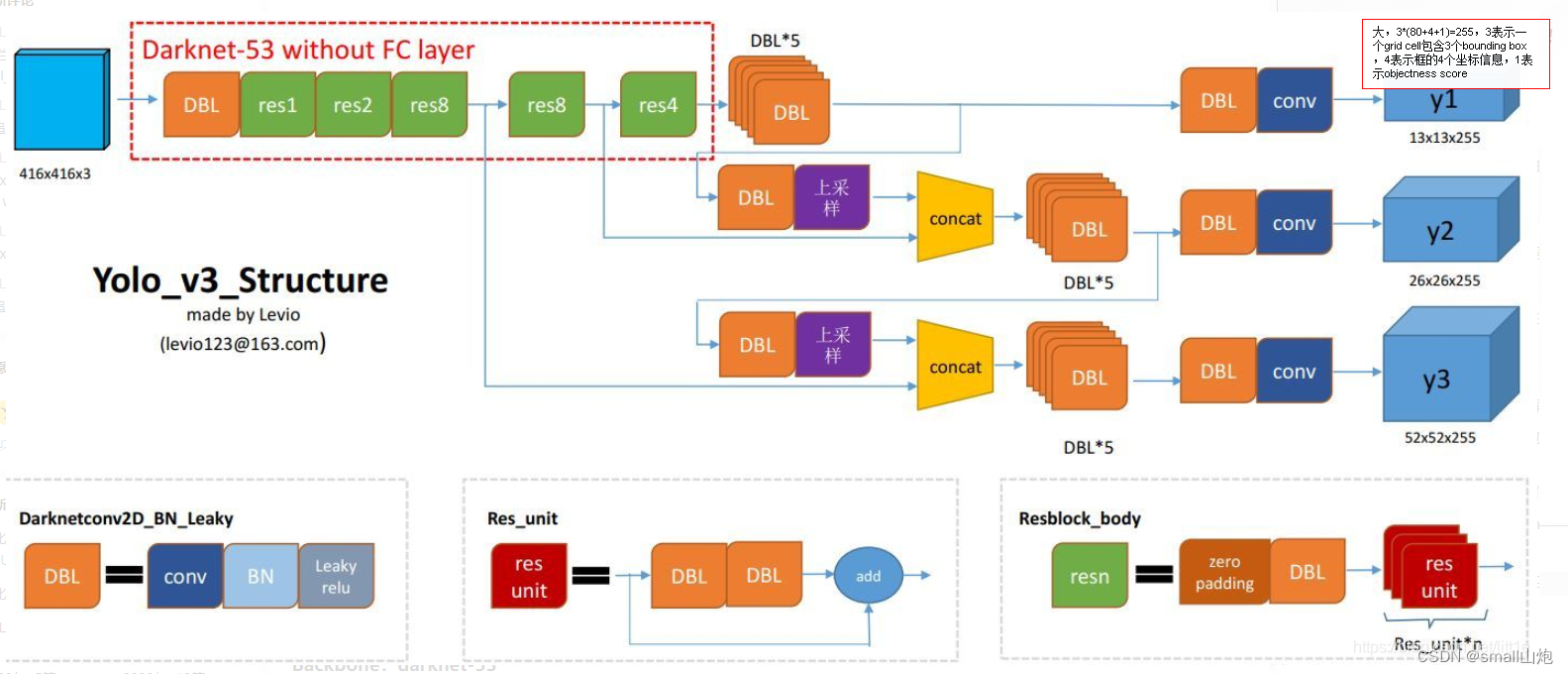
网络结构:
yolov4
把当年很多论文优秀的点吸收,加以组合并进行适当创新的算法,实现了速度和精度的完美平衡,并且有充足的消融实验,是一个值得读的论文。
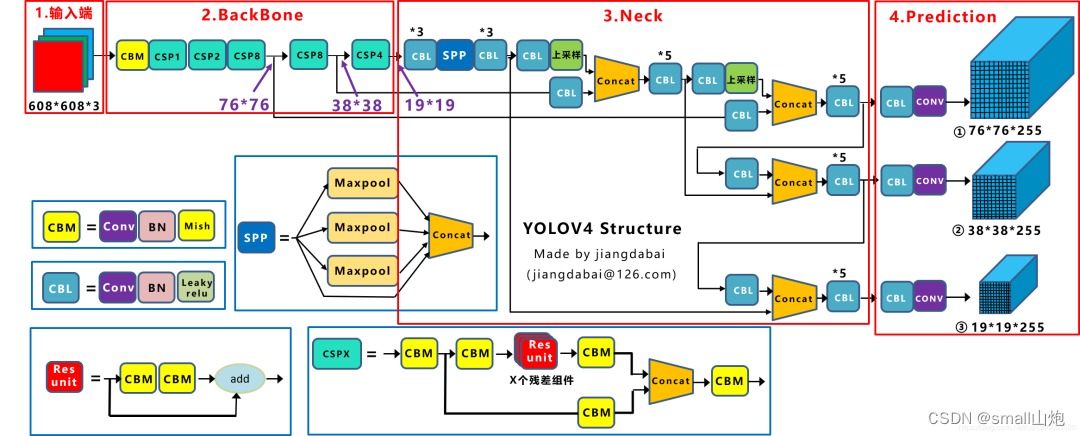
手段有:
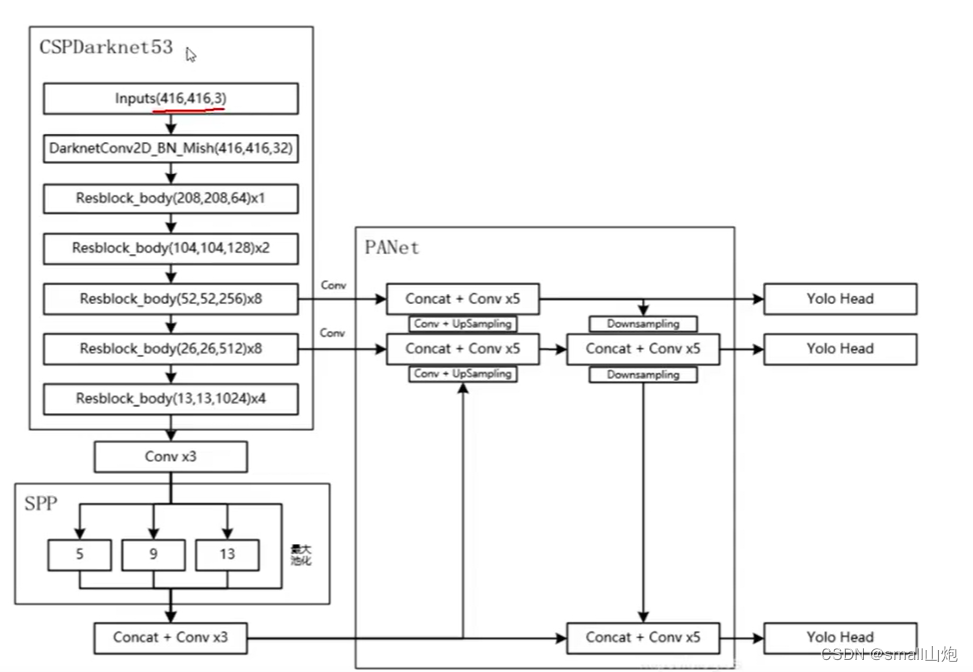
1. 跨阶段部分连接(CSPNet),CSPNet解决了其他大型卷积神经网络框架Backbone中网络优化的梯度信息重复问题,将梯度的变化从头到尾地集成到特征图中,可以有效缓解梯度消失问题,并且减少了模型的参数量和FLOPS数值,既保证了推理速度和准确率,又减小了模型尺寸。

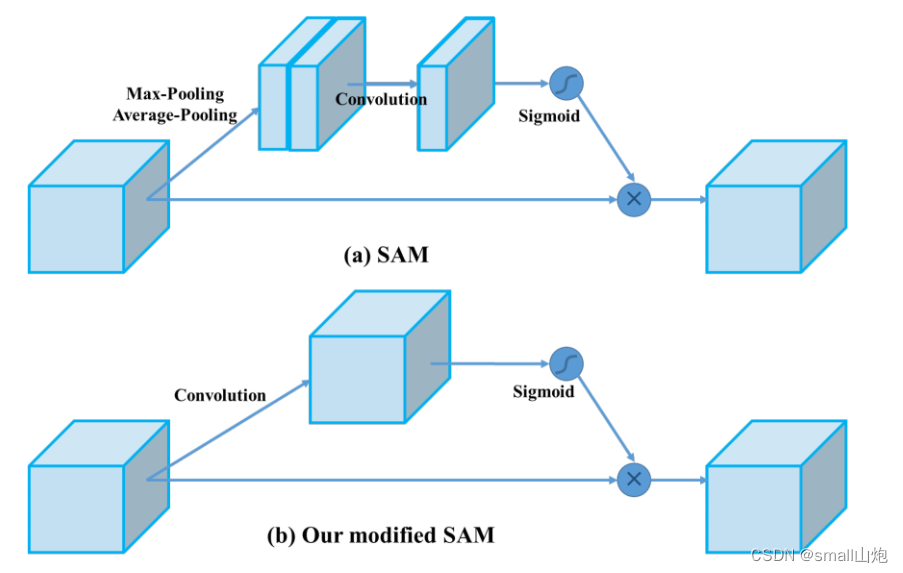
2. v4引入SAM(位置注意力)--->不懂可以看CBAM模块
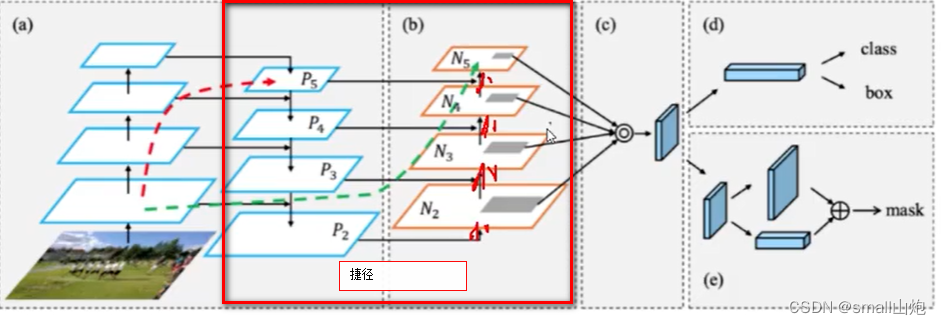
3. PAN结构(采用了双向传递特征模式利用捷径,如下图), YOLOv4使用PANet(Path Aggregation Network)代替FPN进行参数聚合以适用于不同level的目标检测, PANet论文中融合的时候使用的方法是Addition,YOLOv4算法将融合的方法由加法改为Concatenation。
4. SPP(Spatial Pyramid Pooling Networks)结构------特征金字塔,为了满足于不同输入大小,第一:增大感受野;第二:用最大池化满足最终输入特征一致。
5. 数据增强,传统的图像变换;CutMix方法;Mosaic数据增强
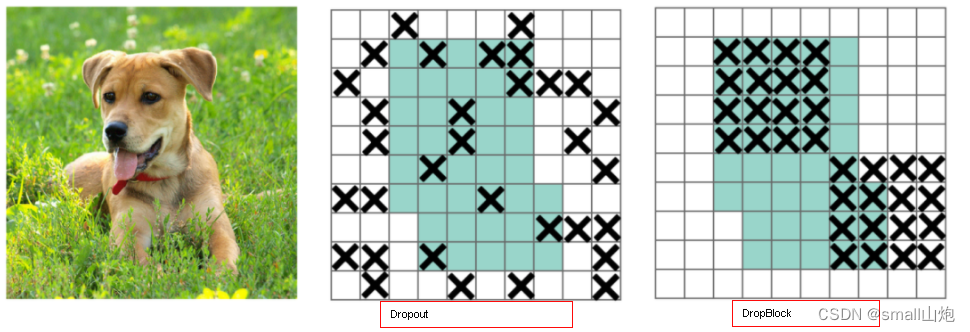
6. DropBlock正则化(为了克服Dropout随机丢弃特征[并没有增加太大的游戏难度]的主要缺点),DropBlock技术在称为块的相邻相关区域中丢弃特征。这样既可以实现生成更简单模型的目的,又可以在每次训练迭代中引入学习部分网络权值的概念,对权值矩阵进行补偿,从而减少过拟合。
7. 标签平滑

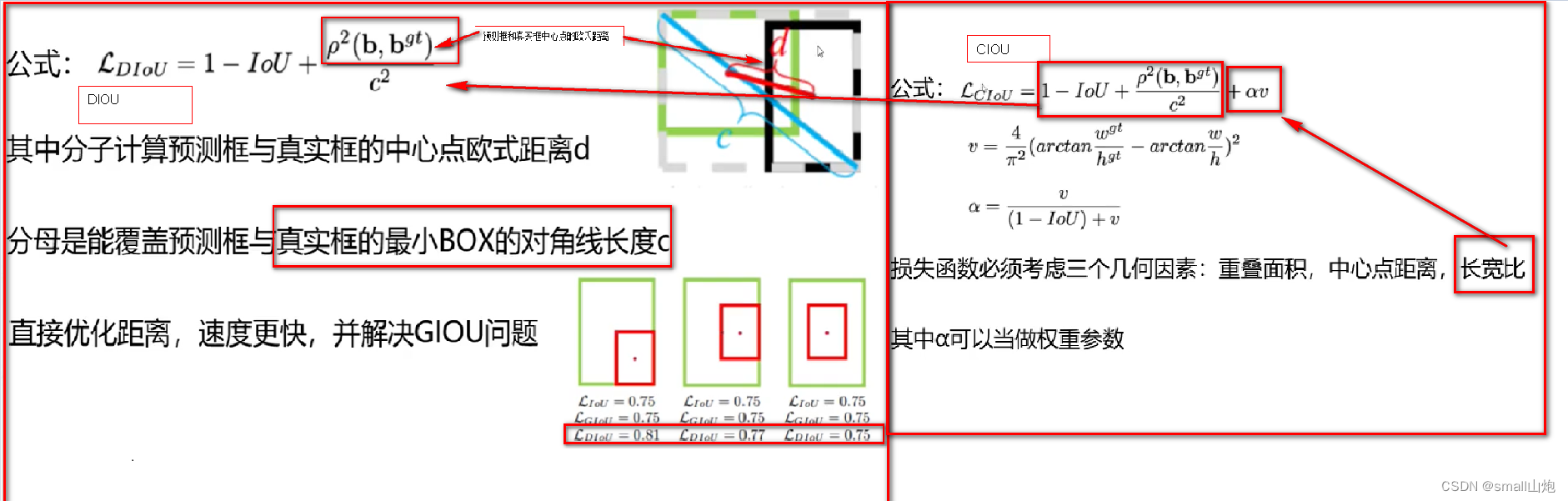
8. 使用CIOU(损失函数)的预测框回归
9. 激活函数(mish激活函数)
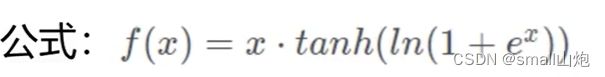
网络结构
yolov5
v5不像1234对应的论文,v5相当于对v4做了更好实现,v5更像偏工程的算法,使其速度与精度都得到了极大的性能提升。
主要的改进思路如下所示:
- 输入端:在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
- 基准网络:融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构;
- Neck网络:目标检测网络在BackBone与最后的Head输出层之间往往会插入一些层,Yolov5中添加了FPN+PAN结构;
- Head输出层:输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
YOLOv5算法具有4个版本,具体包括:YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四种。
源码:https://gitcode.net/mirrors/ultralytics/yolov5
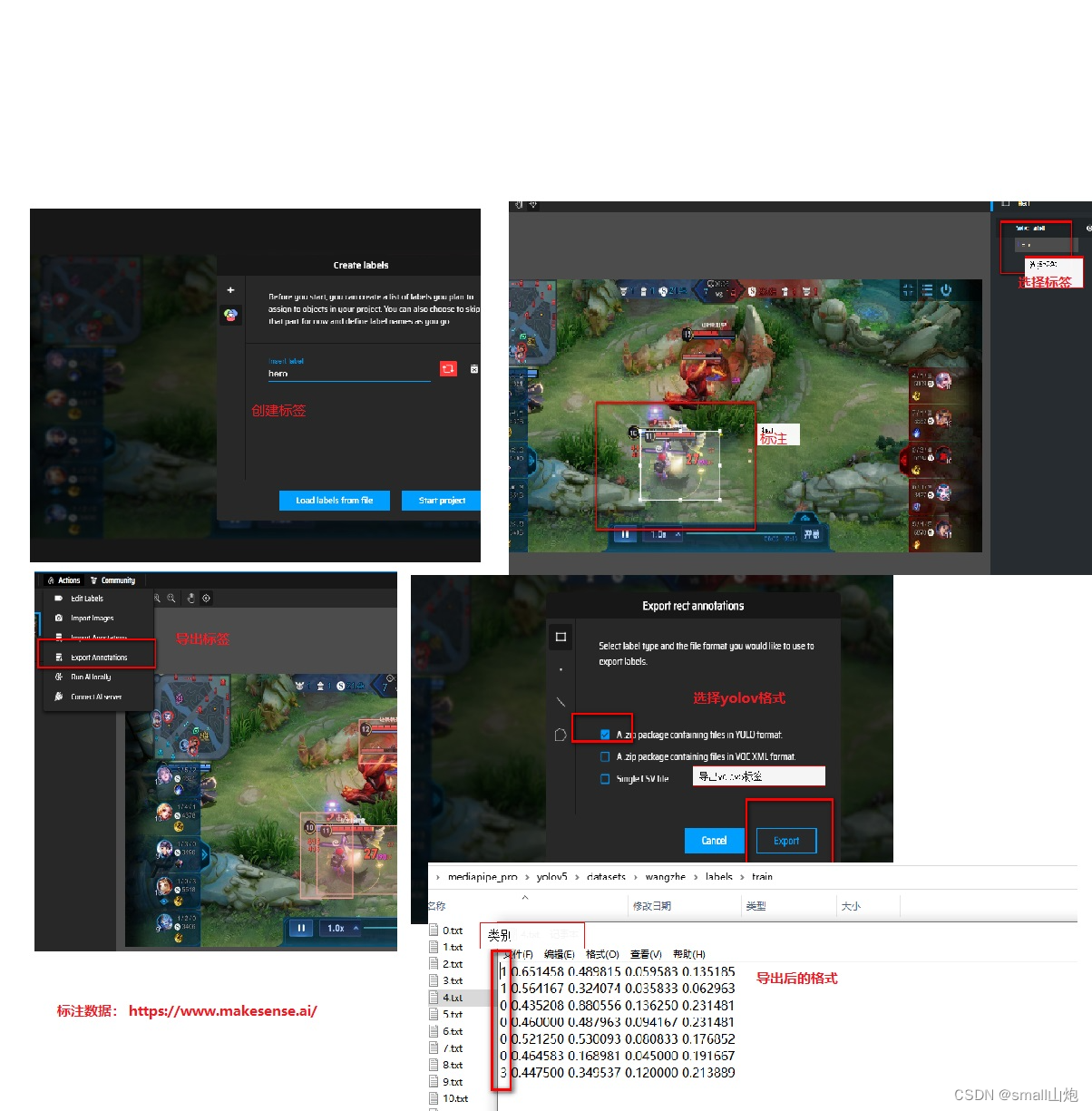
1. 标注数据: Make Sense(也可以使用labelme标注)
2. 训练 train.py
1) 在data建文件:wangzhe.yaml
train: datasets/wangzhe/images/train
val: datasets/wangzhe/images/train
nc: 8
names: ['hero', 'soldier', 'Buff', 'grass', 'wild_monster', 'dragon', 'tower', 'crystal']
2) 下载模型(下载已经训练好的迁移模型,训练速度快) yolov5m.pt
3)标记好的数据集,放在yolov5的datasets目录
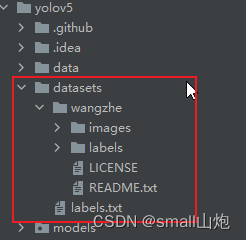
4)修改解析参数

5)其它参数,根据情况修改
os.environ["CUDA_VISIBLE_DEVICES"] = "-1" 使用cpu
workers :训练进程数量 设置0
batch-size : 16大小大概需要4g内存 8或者4
hyp: 超参数
epochs:训练次数
resume: 是否继续按照模型训练 default="路径/last.pt"
linear-lr: 学习率
6) 训练完成,生成下面目录, best.pt就是生成的模型
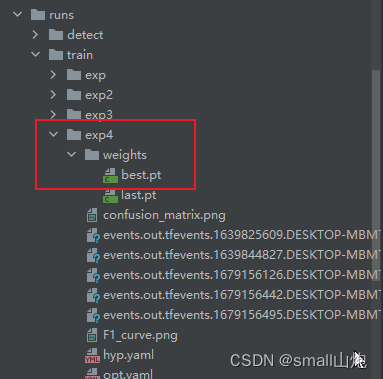
3. 预测 detect.py
weights : 模型
source : 训练目录 //视频 图像路径
img-size: 对图片成比例的放大或者缩小的尺寸
conf-thres: 置信度的阈值
iou-thres: iou置信度 , 一个目标检测出很多区域,取的区域的值 iou= 交集/并集 避免重复
view-img: 命令行指定/true实时看
classes: 指定显示哪个类别

4. 效果
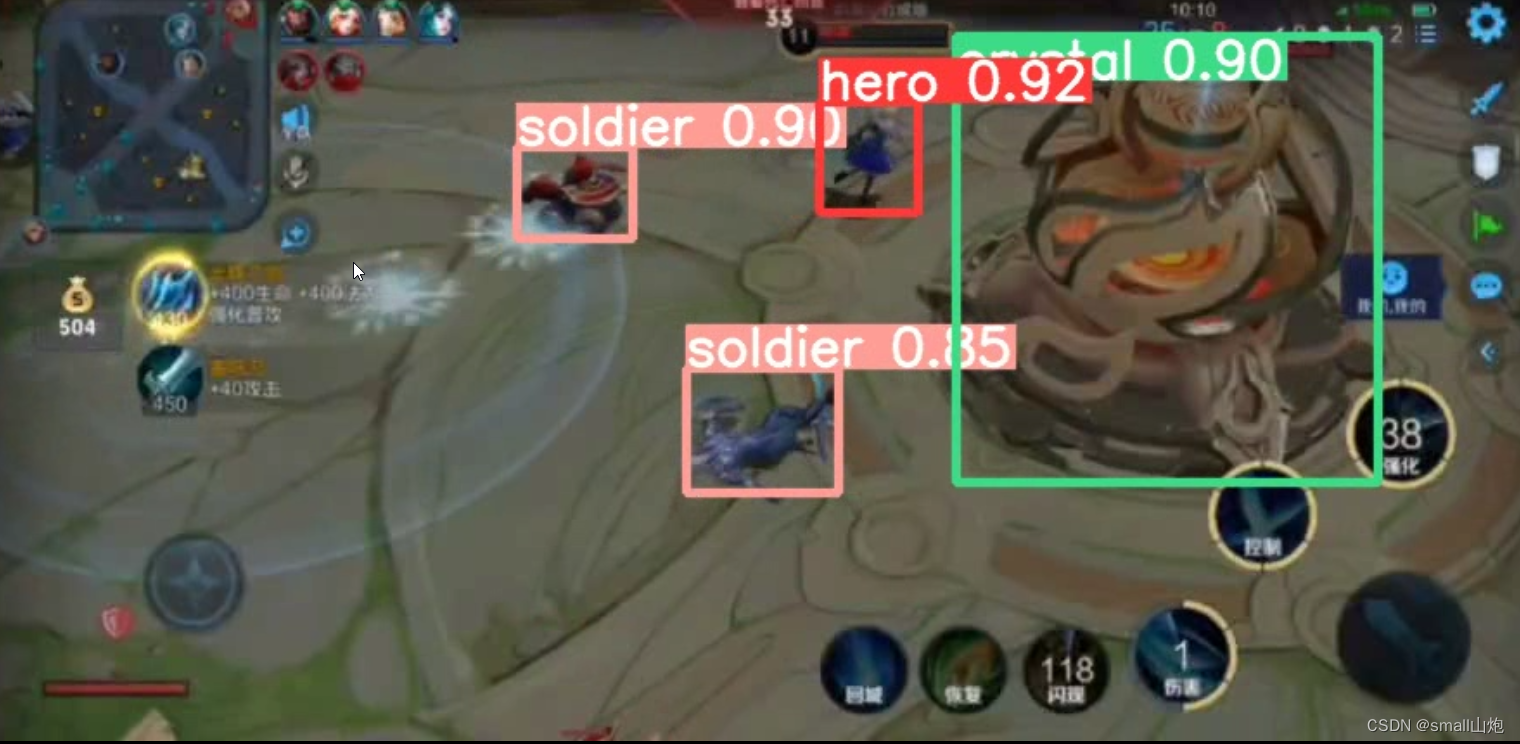
5. 其它介绍
1)datasets.py 数据增强; 数据、标签读取
2)export.py 将pt文件转成ONX文件,可视化展示模型(Netron)
3) 配置文件yolov5s.yaml介绍
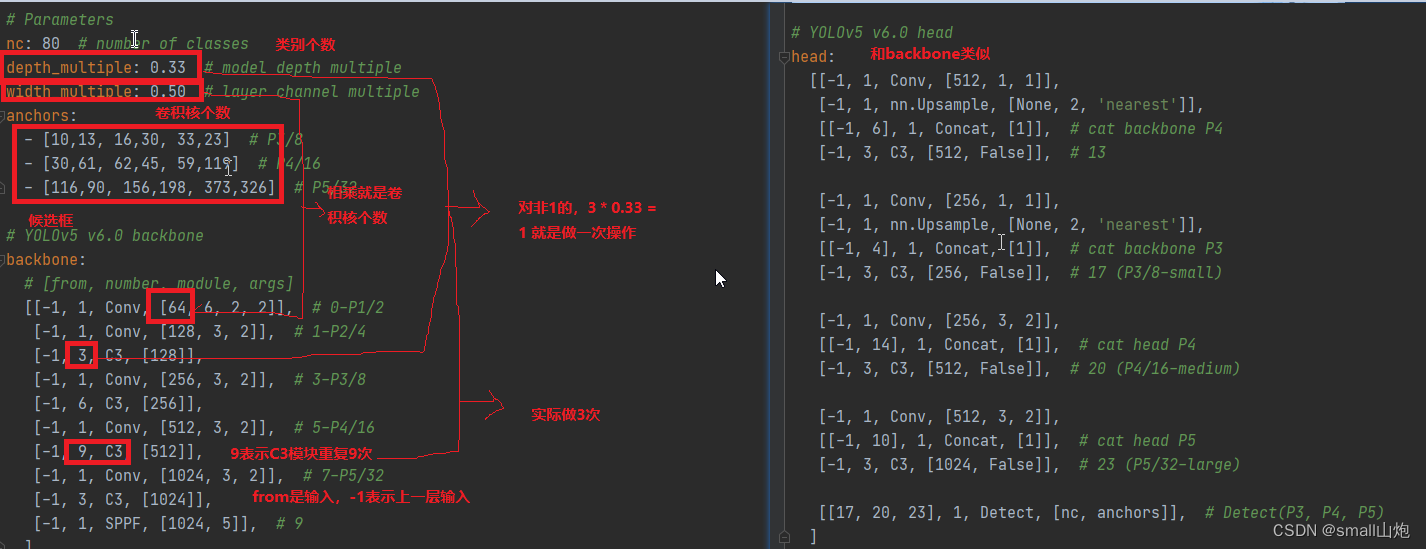
网络结构
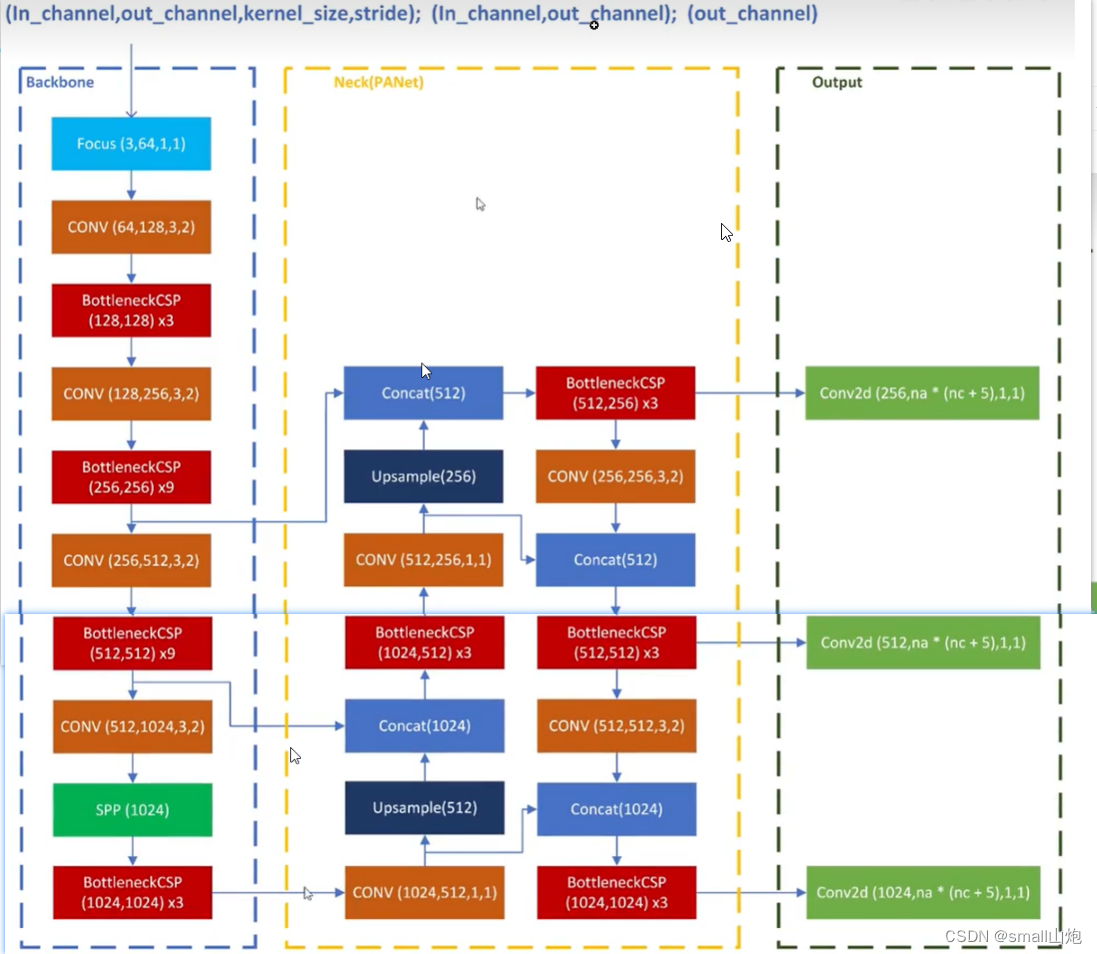
yolov6
YOLOv6 是美团视觉智能部研发的一款目标检测框架,致力于工业应用。在部署方面,YOLOv6 支持 GPU(TensorRT)、CPU(OPENVINO)、ARM(MNN、TNN、NCNN)等不同平台的部署,极大地简化工程部署时的适配工作。主要在 Backbone、Neck、Head 以及训练策略等方面进行了诸多的改进:
- 统一设计了更高效的 Backbone 和 Neck :受到硬件感知神经网络设计思想的启发,基于 RepVGG style设计了可重参数化、更高效的骨干网络 EfficientRep Backbone 和 Rep-PAN Neck。
1. RepVGG Style结构(替换YOLOV5的CSP-Backbone):通过融合成的 3x3 卷积结构,可以有效利用计算密集型硬件计算能力(比如 GPU),同时也可获得 GPU/CPU 上已经高度优化的 NVIDIA cuDNN 和 Intel MKL 编译框架的帮助。
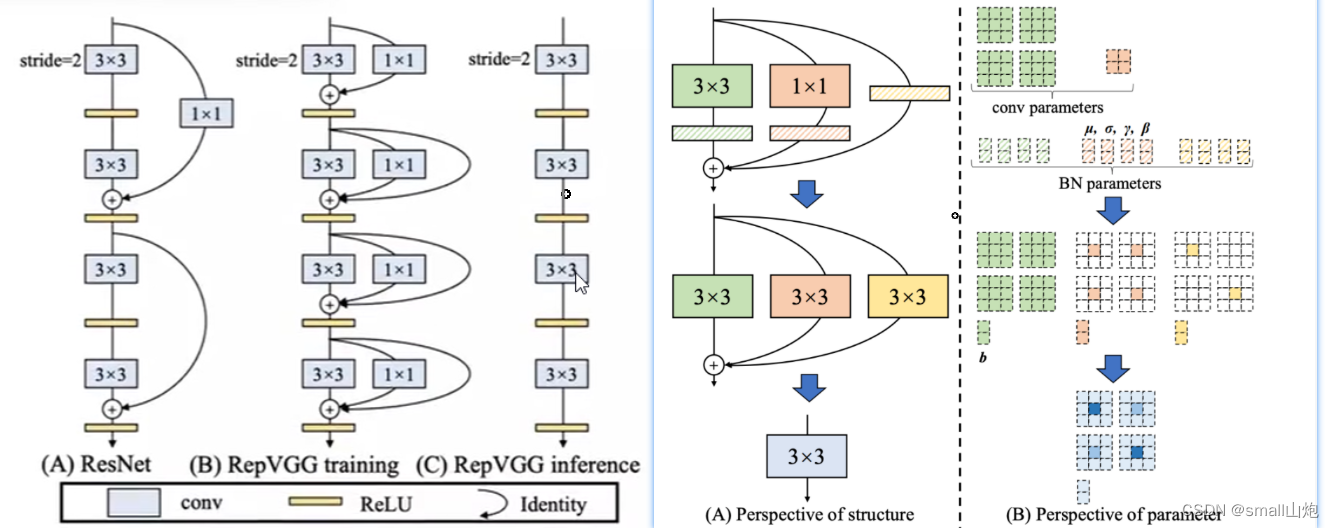
2. Rep-PAN 结构(替换YOLOv5 中使用的 CSP-Block):在 Neck 设计方面,为了让其在硬件上推理更加高效,以达到更好的精度与速度的平衡。
- 优化设计了更简洁有效的 Efficient Decoupled Head,在维持精度的同时,进一步降低了一般解耦头带来的额外延时开销。
Decoupled Head(YOLOv5 的检测头是通过分类和回归分支融合共享的方式来实现的):维持精度的同时降低了延时,缓解了解耦头中带来的额外延时开销。
- 在训练策略上,我们采用Anchor-free 无锚范式,同时辅以 SimOTA标签分配策略以及 SIoU边界框回归损失(分类损失和边界框回归损失)来进一步提高检测精度。
yolov7
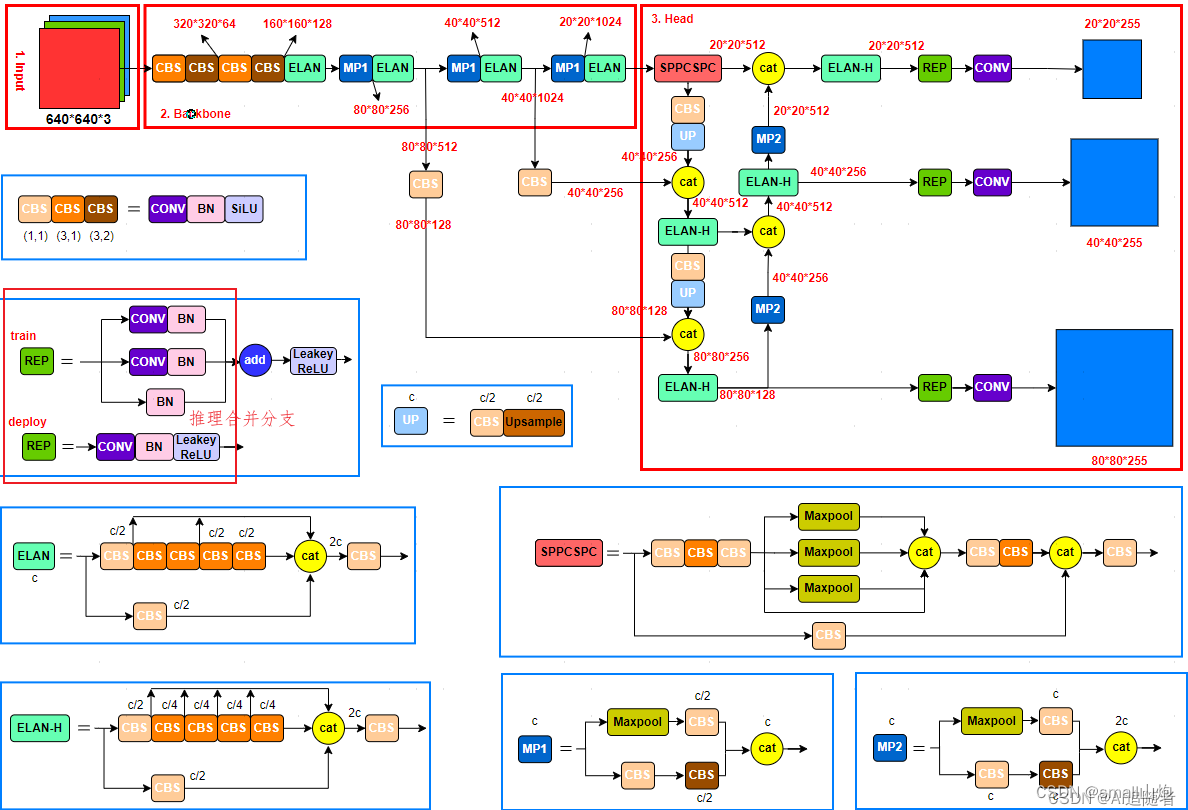
1. RepVGG Style结构上加速,将1*1的卷积和3*3的卷积合并 , Conv+BN 合并
2. 正样本分配策略:
1)初筛
2)IOU筛选(选了10个候选框,而且需要副筛,即做多10个)
3)计算类别预测损失
3. AUX(辅助头)辅助输出
4. v7版本源码就是把v5拿过来改吧改吧
yolov8
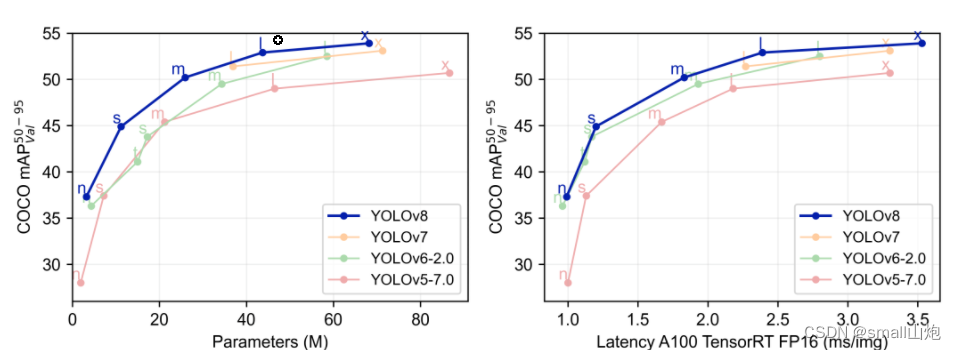
其核心特性和改动可以归结为如下:
- Backbone:使用的依旧是CSP的思想,不过YOLOv5中的C3模块被替换成了C2f模块,实现了进一步的轻量化,同时YOLOv8依旧使用了YOLOv5等架构中使用的SPPF模块;
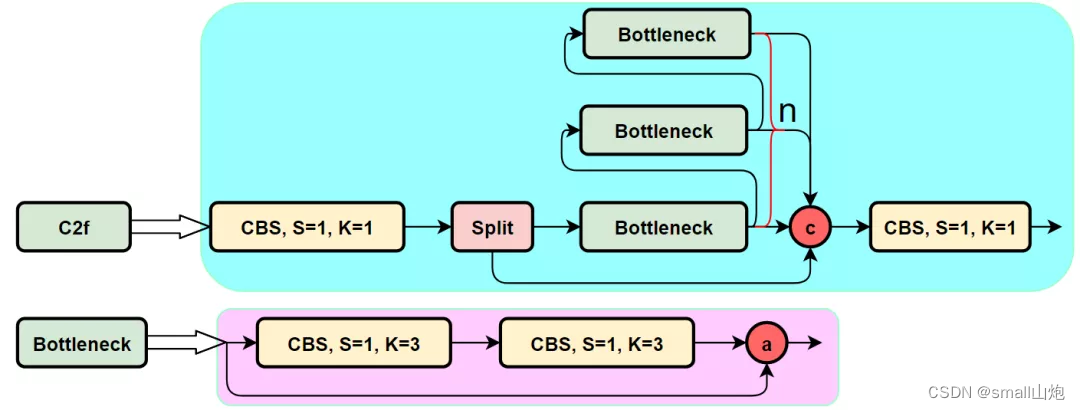
- PAN-FPN:YOLOv8依旧使用了PAN的思想,不过通过对比YOLOv5与YOLOv8的结构图可以看到,YOLOv8将YOLOv5中PAN-FPN上采样阶段中的CBS 1*1的卷积结构删除了,同时也将C3模块替换为了C2f模块;
- Decoupled-Head:YOLOv8使用了Decoupled-Head;
- Anchor-Free:YOLOv8抛弃了以往的Anchor-Base,使用了Anchor-Free的思想;
- 损失函数:YOLOv8使用VFL Loss作为分类损失,使用DFL Loss+CIOU Loss作为分类损失
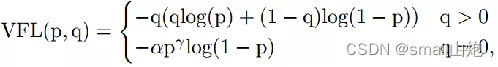
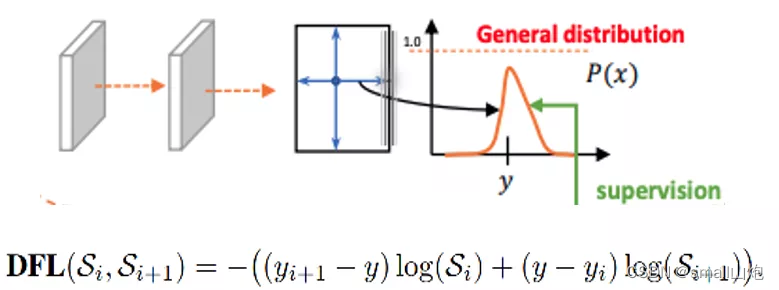
- 样本匹配:YOLOv8抛弃了以往的IOU匹配或者单边比例的分配方式,而是使用了Task-Aligned Assigner匹配方式。
网络结构:
总结:




















 3032
3032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









