



C
L1 玩玩的
选定一个被测方法(focal method),将方法体的源码传给大模型,要求生成单元测试用例。这是不少所谓的可以赋能开发单测的大模型的方案。在某些厂商的demo中,求解一个Hello级别的用例生成还是OK的,一旦换到实际项目,就只能呵呵了。
L2 一锤子买卖
但凡想认真一点,写过几个单测用例,就会知道被测方法会对外部类/二方包中的方法有依赖,而不仅仅依赖JDK/三方包。因此,在使用LLM进行单测生成时,除了提供被测方法(focal method)的代码之外,还需要提供了被测类(focal class)的签名、变量、依赖等额外的关键信息,让LLM能更好地理解代码和生成测试用例。但是即使是这样,目前来说Pass@1的成功率还是一般。通常论文中提到的成功率也就是40-50%左右,而且是基于开源项目。公司的实际项目要更加复杂(也可能是某些专家说的代码质量更差一些),导致LLM一次生成的效果更差。
L3基于G-V-R 生成-验证-修复模型的多轮对话
于是,如何提高LLM生成用例的通过率就是研究的方向。
生成、验证、修复,通过多轮对话来提高生成成功率。(浙大、复旦论文)
以下是浙大论文【1】给出的方案总览。
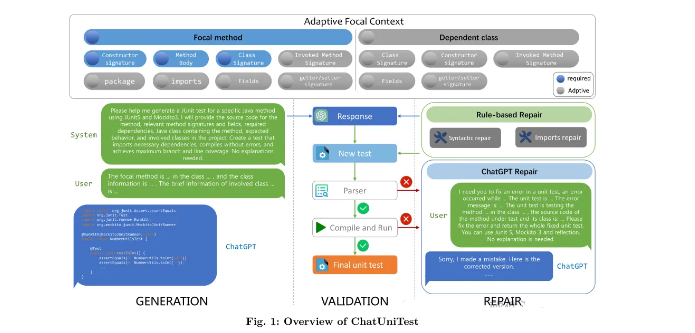
这一套方案比之前一锤子买卖的优势在哪里呢?来看一下浙大论文中给出的效果示例。
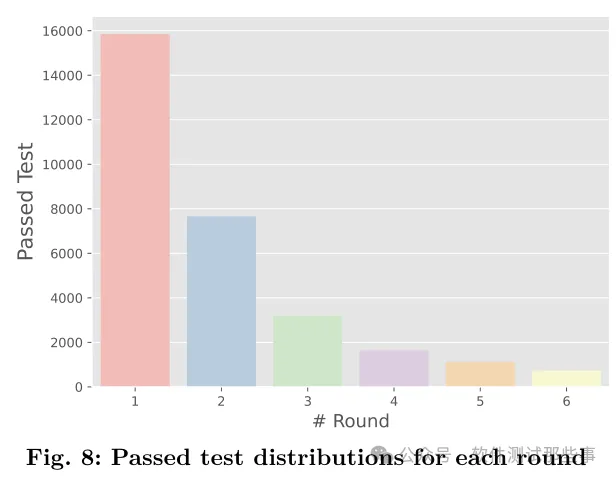
从上图可以看出,大致上,基于开源的代码库,论文团队的方案生成的测试用例,“一条过”的大概是16000个,而经过了一轮修复才通过的用例大致有8000个,而3-6轮修复后通过的用例累计在7000个左右。也就是说,通过G-V-R这样的一条龙,比单纯的“一锤子买卖”大约新增了1倍的通过用例。
当然,从笔者的实践来看,大模型的生成能力,也就是第一轮生成环节产生的用例的质量是具有决定性的。这也很好理解,先天不足的话,后天再补,也是补不上来的。
L4 G-V-R-S 生成-验证-修复-筛选模型
在G-V-R模型的基础上,通过覆盖率指标来遴选测试用例(Meta、南大论文)
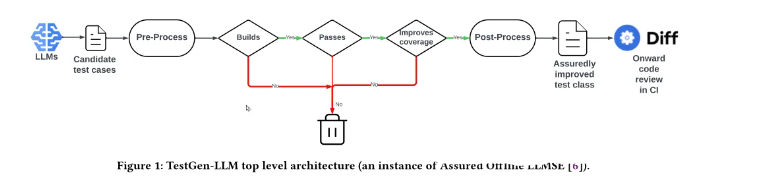
在Meta发表的一篇论文【2】中,在原先只选择编译通过且执行通过的单测用例的基础上,叠加了”Improves coverage”这个环节,对于被测方法(focal method)来说,大模型生成的用例只有增加了覆盖率(代码行、分支等),才会被保留下来。
论文中给出了如下的桑基图,
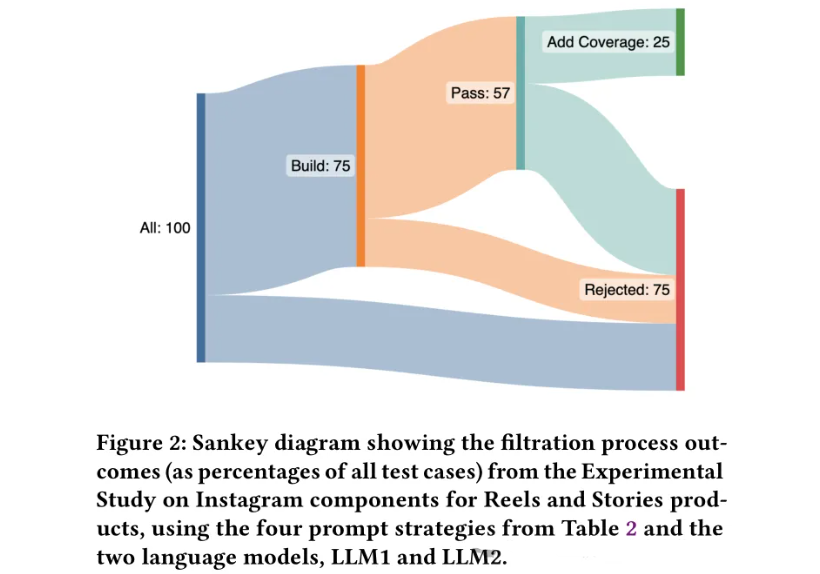
在57%的测试用例可以执行通过的基础上,只有大约一半的用例,也就是总数的25%可以增加测试覆盖率,因而被作为有效用例可以被保留下来作为新增用例。
类似的,南大团队也发表了一篇文章【3】,也提出了类似的套路,他们叫做Testing Feedback,也是利用覆盖率数据来判断新生成的用例是否可以保留。
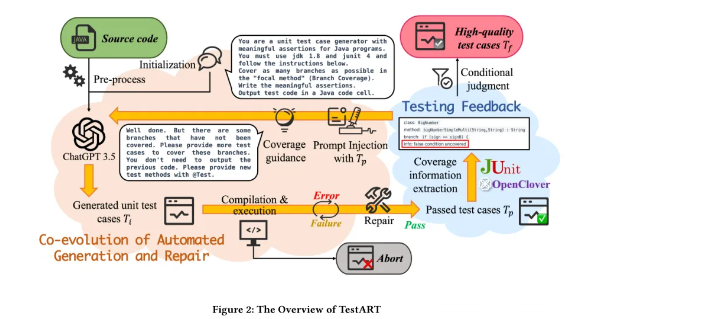
当然,这篇文章主要的创新点还是在于测试用例的修复环节,提出了几个非常有意思的失败用例的修复方式。感兴趣的读者可以拉到文章的底部来查看这个论文。
L5 天下武功,唯快不破
上面的论文中普遍采用了多轮对话的方式和LLM进行交互。目前来讲,随着模型尺寸越来越大,对话窗口size越开越大,LLM返回的内容越多,整个对话过程的耗时也越长。方案中的测试用例编译、执行、覆盖率分析等也需要时间。即使单个环节的耗时一般,整体叠加起来也是非常惊人的。
而笔者在推广过程中发现,其实在IDE的场景中“LLM生成单测用例”其实是一个时间敏感型的任务,开发人员点一下“生成用例”之后,如果几十秒、一分钟以上还没有生成用例,开发人员就开始焦躁起来了。而且如果还占用了IDE资源,造成了卡顿,就会被开发人员吐槽。
因此,如何解决耗时问题就成了后续需要解决的问题。
目前来讲,还没有完美的解决方案。主要的着力点还是在提升第一个环节,也就是首次生成单测用例的时候,能否尽可能通过各种套路(参考上图浙大方案【1】)提供LLM理解被测代码和生成测试用例所需的各种信息和数据。通过一次生成通过率来减少后续轮次,以减少整体的耗时。另外一个思路是,不再等待开发人员在IDE中点击“生成用例”才触发这个流程,而是通过预生成等套路,既然解决不了问题,就消灭问题本身。
【推荐自动化测试教程】:
【软件测试教程】从零开始学自动化测试(2024实用版)自动化测试2024最全面教程!!!_哔哩哔哩_bilibili
如果我的博客对你有帮助、如果你喜欢我的博客内容,请 “点赞” “评论” “收藏” 一键三连哦!
最后: 下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】



















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









