




MapReduce是Hadoop系统核心组件之一,它是一种可用于大数据并行处理的计算模型、框架和平台,主要解决海量数据的计算,是目前分布式计算模型中应用较为广泛的一种。
一、MapReduce核心思想
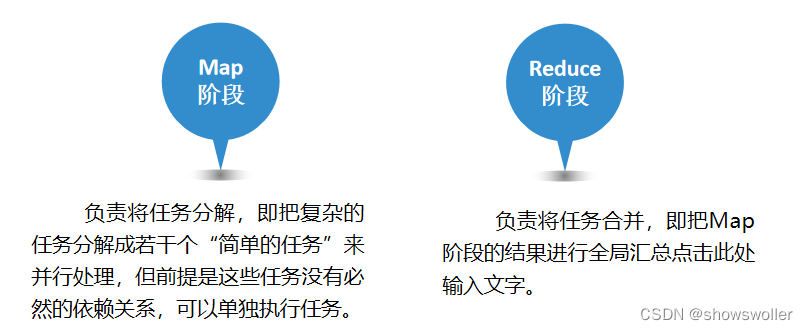
MapReduce的核心思想是“分而治之”。所谓“分而治之”就是把一个复杂的问题,按照一定的“分解”方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,把各部分的结果组成整个问题的结果,这种思想来源于日常生活与工作时的经验,同样也完全适合技术领域。任务分解的前提是这些任务没有必然的依赖关系,可以单独执行任务,将结果合并,即把任务划分中的各个子任务的结果进行全局汇总
MapReduce作为一种分布式计算模型,它主要用于解决海量数据的计算问题。使用MapReduce操作海量数据时,每个MapReduce程序被初始化为一个工作任务,每个工作任务可以分为Map和Reduce两个阶段。
构架方面:以统一构架位开发人员隐藏系统层细节,程序员只需要集中于应用问题和算法本身,而不需要关注其他系统层的处理细节,大大减轻了开发人员开发程序的负担
该框架可负责自动完成以下系统底层相关的处理
1:计算任务的自动划分和调度
2:数据的自动化分布存储和划分
3:处理数据与计算任务的同步
4:结果数据的收集整理
5:系统通信 负载平衡 计算性能优化处理
6:处
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 590
590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











