







需要源码请点赞关注收藏后评论区留下QQ并且私信~~~
一、模型、学习、规划简介
1:模型
Agent可以通过模型来预测环境并做出反应,这里所说的模型通常指模拟模型,即在给定一个状态和动作时,通过模型可以对下一状态和奖赏做出预测
模型通常可以分为分布模型和样本模型两种类型
分布模型:该模型可以生成所有可能的结果及其对应的概率分布
样本模型:该模型能够从所有可能的情况中产生一个确定的结果
从功能上讲,模型是用于模拟环境和产生模拟经验的。与样本模型相比,分布模型包含更多的信息,只是现实任务中难以获得所有的状态转移概率
2:学习
学习过程是从环境产生的真实经验中进行学习,根据经验的使用方法,学习过程可以分为直接强化学习和模型学习两种类型
直接强化学习:在真实环境中采集真实经验,根据真实经验直接更新值函数或策略,不受模型偏差的影响
模型学习:在真实环境中采集真实经验,根据真实经验来构建和改进模拟模型,提供模拟模型精度,使其更接近真实环境
3:规划
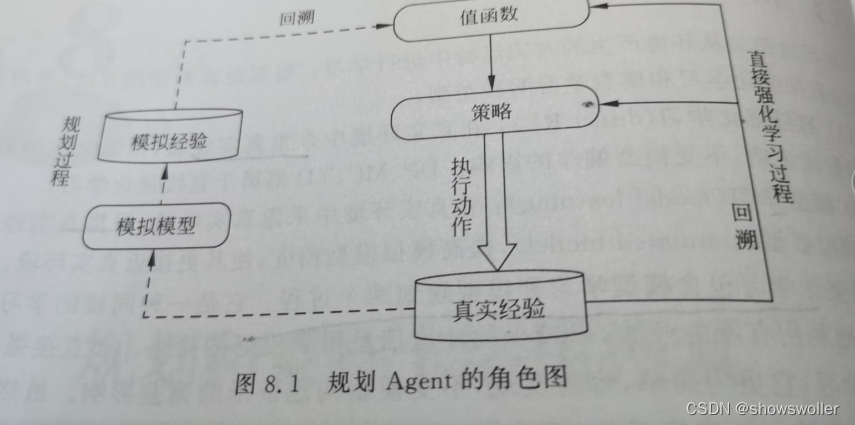
规划过程是基于模拟环境或经验模型,从模拟经验中更新值函数,实现改进策略的目的,学习和规划的核心都是通过回溯操作来评估值函数,不同之处在于:在规划过程中,Agent并没有与真实环境交互
规划通常可分为状态空间规划和方案空间规划,状态空间规划是在状态空间中寻找最优策略,值函数的计算都是基于状态的,通常该规划方法视为搜索方法,其基本思想如下
1:所有规划算法都以计算值函数作为策略改进的中间关键步骤
2:所有规划算法都可以通过基于模型产生的模拟经验来计算值函数
二、Dyna-Q结构及其算法
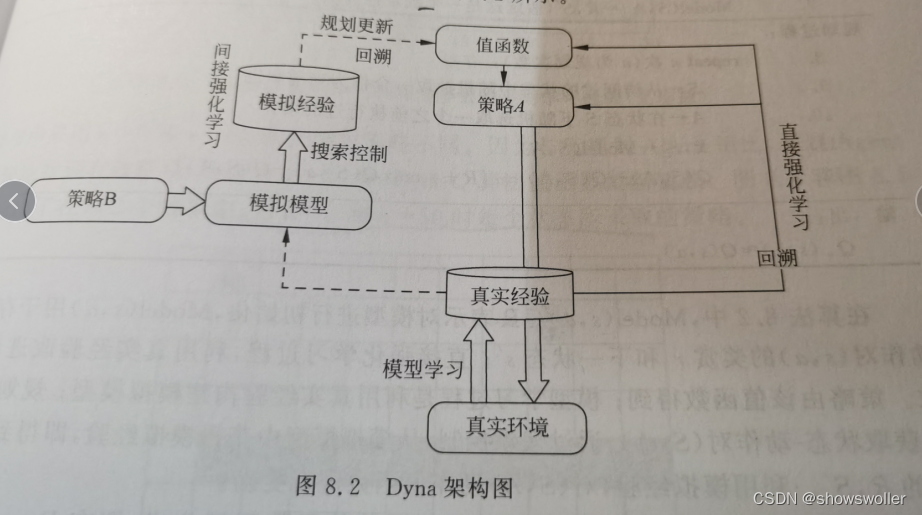
Dyna-Q架构包含了在线规划Agent所需要的主要功能,该架构讲学习和规划有机地结合在一起,是有模型和无模型方法的融合,其数据来源包括基于真实环境采样的真实经验以及基于模拟模型采样的模拟经验,通过直接强化学习或间接强化学习来更新值函数或者策略
架构图如下
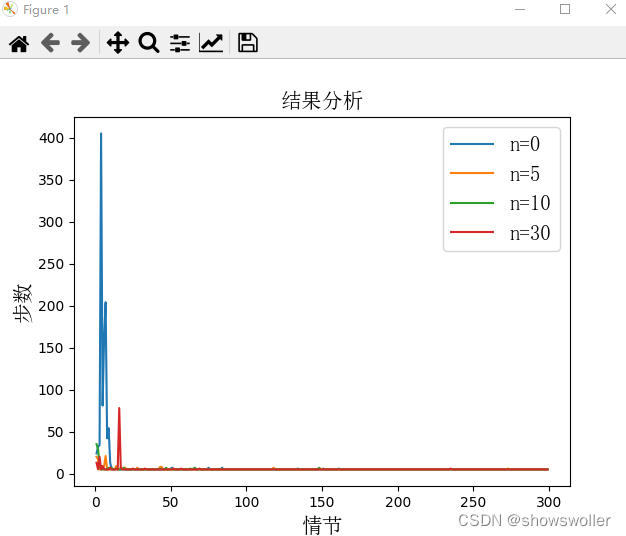
三、Dyna-Q不同规划对学习步数的影响
机器人环境搭建以及背景可点击如下链接了解
此处比较不同规划步数对实验效果的影响,当机器人离开边界或者撞到障碍物则得到-10的奖赏,到达充电桩获得+1的奖赏,其他情况奖赏均为0,不同需要不同情节数,可视化结果如下

代码如下
import gym
from gym import spaces
from gym.utils import seeding
from random import random, choice
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
class Grid(object):
def __init__(self, x:int = None,
y:int = None,
type:int = 0,
reward:float = 0.0):
self.x = x # 坐标x
self.y = y
self.type = type # 类别值(0:空;1:障碍或边界)
self.reward = reward # 该格子的即时奖励
self.name = None # 该格子的名称
self._update_name()
def _update_name(self):
self.name = "X{0}-Y{1}".format(self.x, self.y)
def __str__(self):
return "name:{3}, x:{0}, y:{1}, type:{2}".format(self.x,
self.y,
self.type,
self.name
)
class GridMatrix(object):
def __init__(self, n_width:int, # 水平方向格子数
n_height:int, # 竖直方向格子数
default_type:int = 0, # 默认类型
default_reward:float = 0.0, # 默认即时奖励值
):
self.grids = None
self.n_height = n_height
self.n_width = n_width
self.len = n_width * n_height
self.default_reward = default_reward
self.default_type = default_type
self.reset()
def reset(self):
self.grids = []
for x in range(self.n_height):
for y in range(self.n_width):
self.grids.append(Grid(x,
y,
self.default_type,
self.default_reward))
def get_grid(self, x, y=None):
'''获取一个格子信息
args:坐标信息,由x,y表示或仅有一个类型为tuple的x表示
return:grid object
'''
xx, yy = None, None
if isinstance(x, int):
xx, yy = x, y
elif isinstance(x, tuple):
xx, yy = x[0], x[1]
assert(xx >= 0 and yy >= 0 and xx < self.n_width and yy < self.n_height), "任意坐标值应在合理区间"
index = yy * self.n_width + xx
return self.grids[index]
def set_reward(self, x, y, reward):
grid = self.get_grid(x, y)
if grid is not None:
grid.reward = reward
else:
raise("grid doesn't exist")
def set_type(self, x, y, type):
grid = self.get_grid(x, y)
if grid is not None:
grid.type = type
else:
raise("grid doesn't exist")
def get_reward(self, x, y):
grid = self.get_grid(x, y)
if grid is None:
return None
return grid.reward
def get_type(self, x, y):
grid = self.get_grid(x, y)
if grid is None:
return None
return grid.type
# 格子世界环境
class GridWorldEnv(gym.Env):
metadata = {
'render.modes': ['human', 'rgb_array'],
'video.frames_per_second': 30
}
def __init__(self, n_width: int=5,
n_height: int = 5,
u_size=40,
default_reward: float = 0.0,
default_type=0):
self.u_size = u_size # 当前格子绘制尺寸
self.n_width = n_width # 格子世界宽度(以格子数计)
self.n_height = n_height # 高度
self.width = u_size * n_width # 场景宽度 screen width
self.height = u_size * n_height # 场景长度
self.default_reward = default_reward
self.default_type = default_type
self.grids = GridMatrix(n_width=self.n_width,
n_height=self.n_height,
default_reward=self.default_reward,
default_type=self.default_type)
self.reward = 0 # for rendering
self.action = None # for rendering
# 0,1,2,3 represent up, down, left, right
self.action_space = spaces.Discrete(4)
# 观察空间由low和high决定
self.observation_space = spaces.Discrete(self.n_height * self.n_width)
self.ends = [(0, 0)] # 终止格子坐标,可以有多个
self.start = (0, 4) # 起始格子坐标,只 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1123
1123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











