



 本文详细介绍了Hive的数据处理流程,包括解释、编译、优化和执行等步骤,并探讨了如何通过设置参数和调整策略来解决数据倾斜问题,同时提供了提升Hive性能的实用技巧,如合理安排Join操作和利用MapJoin。
本文详细介绍了Hive的数据处理流程,包括解释、编译、优化和执行等步骤,并探讨了如何通过设置参数和调整策略来解决数据倾斜问题,同时提供了提升Hive性能的实用技巧,如合理安排Join操作和利用MapJoin。
架构
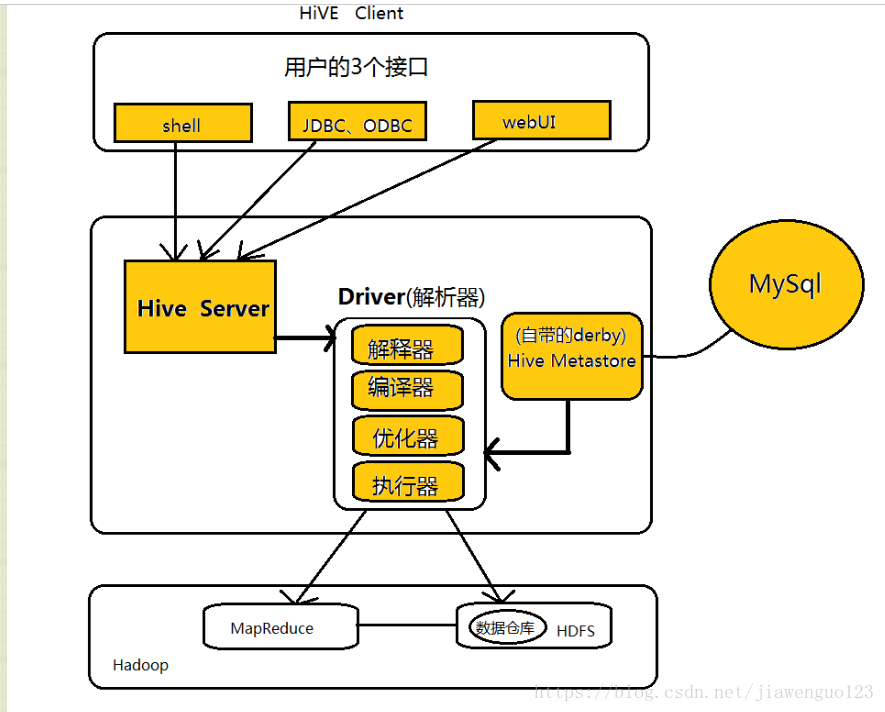
Hive Driver
1.解释 - 分析query
2.编译
3.优化
4. 执行器
要与metastore进行通讯
– explode
select a, explode(b) as bb from tbl;
– lateral view
select a, b from tbl
lateral view expode(splict(b)) as b;
解决数据倾斜
1. set hive.map.aggr=true
2. set hive.groupby.skewindata=true
3. distinct时将倾斜的key去掉,
4. 在key后面多加一列随机列,类似2
hive性能优化
1. 尽量先join小表
2. 小表使用map join。在map端完成join, 避免shuffle
select /+ MAPJOIN(a) /
a.start_level, b.*
from dim_level a
join (select * from test) b
where b.xx>=a.start_level and b.xx

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









