







一、HashMap
hashing:transformation of a string of characters(Text) to a shorted fixed-length value that represents original string.A shorter value helps in indexing and faster searches.
In Java every object has a method public int hashcode() that will return a hash value for given object.
hashMap():构造一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空 HashMap。
//resize()与ArrayList类似,创建新的数组,将原数组内容复制过去:
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
//Node<K,V>数据结构:
int hash;
K key;
V value;
Node<K,V> next; //newTab中每个元素,都可以是个链表
1.put(K k ,V v)
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)//第一次put(k,v)
n = (tab = resize()).length;//创建Node数组
if ((p = tab[i = (n - 1) & hash]) == null)//tab[i]还没元素
tab[i] = newNode(hash, key, value, null);//将元素放tab[i]中
else {
Node<K,V> e; K k;
//[i]的第一个(hash、equal均相同),则更新值
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//p是TreeNode 树是red-black tree
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//沿[i]链表找
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);//将此tab[i]转换成tree
break;
}
//[i]链表后面发现是重复元素
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//break执行 ① if ((e = p.next) == null) ②发现key重复 1)kv一致 2)只key同
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//若不是更新,则size++,若需要,则扩容
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null; //新添加元素,则没有旧值
}
hash:
static final int hash(Object key) {
int h; //允许key为null,从而value可以为null
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
key.equals(k)
①比较的是hashcode 若①同,则比较equal
return :与 key 关联的旧值;如果 key 没有任何映射关系,则返回 null。(返回 null 还可能表示该映射之前将 null 与 key 关联。
In Java 8,when we have too many unequal keys which gives same hashcode(index)-when the number of items in a hash bucket grows beyond certain threshold(TREEIFY_THRESHOLD=8),content of that bucket switches from using a linked list of Entry objects to a red-black tree.This theoretically improves the worst-case performance from from O(n) to O(lgn).
若tab[i]链表长度超过TREEIFY_THRESHOLD,则将tab[i]转换成红黑树存储方式。
简单讲:
put(K k,V k)
{
hash(k)
index=hash&(n-1) //n是tab_size
}
例子:
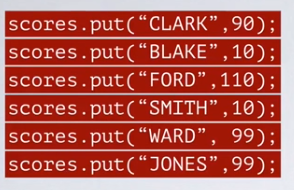
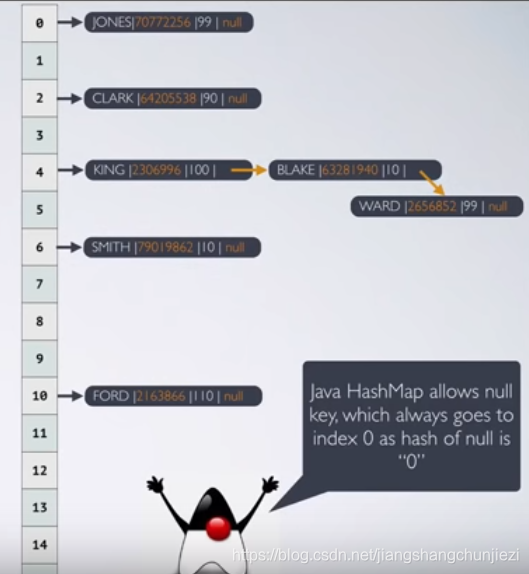
2. get(Object key)
get过程和put过程类似。
简单讲:
V get(Object key)
{
hash(k)
index=hash&(n-1) //n是tab_size
}
3.自定义HashMap中key:重写hashCode()和equal方法
从put(K k,V k)中可以看出一直在比较的是key.hashcode、key.equal,从而自定义什么样的是hashcode相同的、什么样的是equal相同的。
若要根据自己的逻辑判定是否为同一个key,则要重写hashCode()和equal方法
import java.util.HashMap;
import java.util.Map.Entry;
import java.util.Set;
import java.util.Iterator;
public class Student {
String name;
String id;
public Student(String name,String id)
{
this.name=name;
this.id=id;
}
public String toString()
{
return "id="+id+"---"+"name="+name;
}
public int hashCode(){
System.out.println(id.hashCode());
return id.hashCode(); //String重写了Object中的hashCode()方法
}
//自定义了id相同的是相同学生
public boolean equals(Object obj){
Student s=(Student)obj;
if(s.id.equals(this.id))
return true;
else
return false;
}
public static void main(String []args) {
HashMap<Student,String> hm=new HashMap<Student,String>();
hm.put(new Student("Spig","001"),"sp1");//①
hm.put(new Student("Spig","001"),"sp2");//②
Iterator<Entry<Student,String>> it=hm.entrySet().iterator();
while(it.hasNext())
{
Entry<Student,String> e=it.next();
System.out.println(e.getKey()+"----"+e.getValue());
}
}
结果:47665
47665
id=001---name=Spig----sp2
解释:第一次会把元素放在tab[i]中
第二次,hash与第一次同,进而比较key.equals(k) ,从而确定是相同的key,更新值。
注意我们可以自定义HashMap中key相同的方式,但是不能和new Object()混淆。new Object总会生成新的对象。
二、HashMap vs Hashtable
“Hashtable” is the generic name for hash-based maps.并没有红黑树优化
1.synchronized
HashMap is non synchronized. It is not-thread safe and can’t be shared between many threads without proper synchronization code whereas Hashtable is synchronized. It is thread-safe and can be shared with many threads.
2.key、value 为null
HashMap allows one null key and multiple null values whereas Hashtable doesn’t allow any null key or value.
3.HashMap是Hashtable轻量级实现
HashMap is generally preferred over HashTable if thread synchronization is not needed
Why HashTable doesn’t allow null and HashMap does?
To successfully store and retrieve objects from a HashTable, the objects used as keys must implement the hashCode method and the equals method. Since null is not an object, it can’t implement these methods. HashMap is an advanced version and improvement on the Hashtable. HashMap was created later.(HashMap会对key==null时的hash做特殊处理,value是null或其他没有处理)
Hashtable:
//首先检查value是否为空,空则报异常;key.hashCode() 若key为null,会报异常。
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
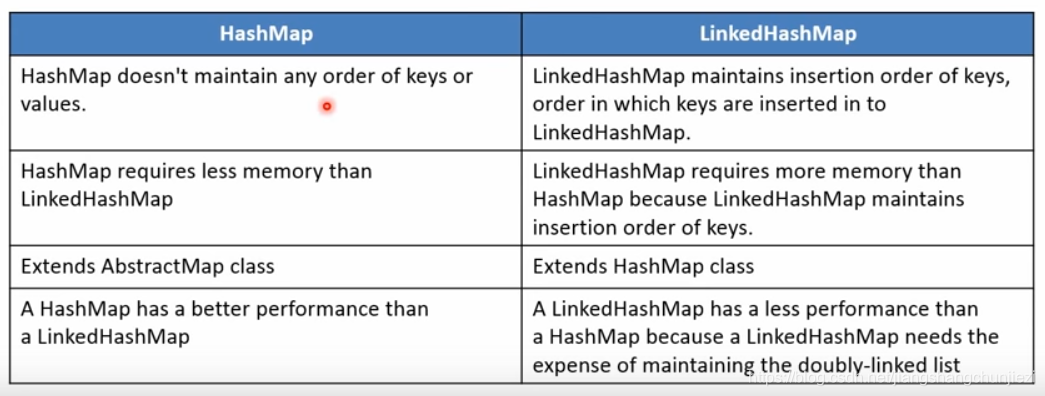
三、HashMap vs LinkedHashMap
LinkedHashMap是HashMap的子类,it retains the original order of insertion for its elements using a doubly-linked list.Thus iteration order of its elements is same as the inserton order for LinkedHashMap.
①数据结构
/**
* HashMap.Node subclass for normal LinkedHashMap entries.
*/
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}

②put()会将新node添加到doubly linked list
//LinkedHashMap复用put(K k,V v)
tab[i] = newNode(hash, key, value, null); 若是新节点,先放到双向链表中
再向hashmap中插入tab[i]的linked list或者元素太多插入二叉树中
//LinkedHashMap中newNode构造函数
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p); //将p(新节点)插入双向链表中
return p;
}
// link at the end of list
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)//第一个节点
head = p;
else {
p.before = last;
last.after = p;
}
}
简单的画了一个节点(黄色圈出来的)示意一下,注意左边的红色箭头引用为Entry节点对象的next引用(散列表中的单链表),绿色线条为Entry节点对象的before, after引用(双向链表的前后引用);
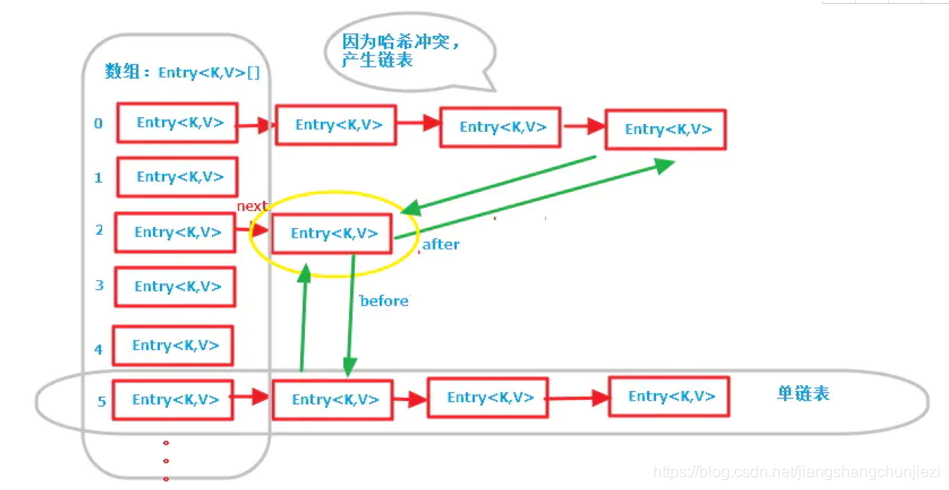
③遍历有序
Iterator<Entry<String,String>> it=lh.entrySet().iterator();
//LinkedHashMap
public Set<Map.Entry<K,V>> entrySet() {
Set<Map.Entry<K,V>> es;
return (es = entrySet) == null ? (entrySet = new LinkedEntrySet()) : es;
}
//内部类
final class LinkedEntrySet extends AbstractSet<Map.Entry<K,V>> {
public final int size() { return size; }
public final void clear() { LinkedHashMap.this.clear(); }
public final Iterator<Map.Entry<K,V>> iterator() {
return new LinkedEntryIterator();}
}
abstract class LinkedHashIterator {
LinkedHashMap.Entry<K,V> next;
LinkedHashMap.Entry<K,V> current;
int expectedModCount;
LinkedHashIterator() {
next = head; //next指向doubly-linked list头节点
expectedModCount = modCount;
current = null;
}
public final boolean hasNext() {
return next != null;
}
final LinkedHashMap.Entry<K,V> nextNode() {
LinkedHashMap.Entry<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
current = e;
next = e.after; //指向doubly-linked list中下一个
return e;
}
四、TreeMap
1.Comparable接口:
This interface imposes a total ordering on the objects of each class that implements it.
实现此接口的类,使得2个对象有了可比较性。根据传递性,从而使此类的所有对象排序。这种排序称为自然排序(nature ordering)。
int compareTo(T o)
< :负数
= :0
> :正数
String 类实现了Comparable接口
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence
在min(len1,len2),找到第一个不同的字符;若min均相同,则长的大
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {
return c1 - c2;
}
k++;
}
return len1 - len2;
}
测试:
String str1="abc";
String str2="ab1";
System.out.println(str1.compareTo(str2));// a:99 1:49 结果为50
2.Comparator接口

举例
public final class Integer extends Number implements Comparable<Integer>
public class MyCompare implements Comparator {
/*
* 注意Comparator接口有两个函数:compare、equals,不用实现equals,
* 因为共同上帝Object已经实现了这个方法,所以MyCompare不是抽象类
*/
//姓名相同,则比年龄。只有姓名和年龄均相同的,才是同一个人
public int compare(Object o1,Object o2) {
Student s1=(Student)o1;
Student s2=(Student)o2;
int num=s1.getName().compareTo(s2.getName());
if(num==0) {
return new Integer(s1.getAge()).compareTo(s2.getAge());
}
return num;
}
}
3.put(K key, V value)
①构造方法:

/**
* The comparator used to maintain order in this tree map, or
* null if it uses the natural ordering of its keys.
*
* @serial
*/
private final Comparator<? super K> comparator;
/*
* Constructs a new, empty tree map, using the natural ordering of its
* keys. All keys inserted into the map must implement the {@link
* Comparable} interface. Furthermore, all such keys must be
* mutually comparable
使用key的自然顺序;key必须实现Comparable接口
*/
public TreeMap() {
comparator = null;
}
/**
* Constructs a new, empty tree map, ordered according to the given
* comparator. All keys inserted into the map must be mutually
* comparable by the given comparator
使用给定的comparator
*/
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
②树节点的数据结构:红黑树
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
}
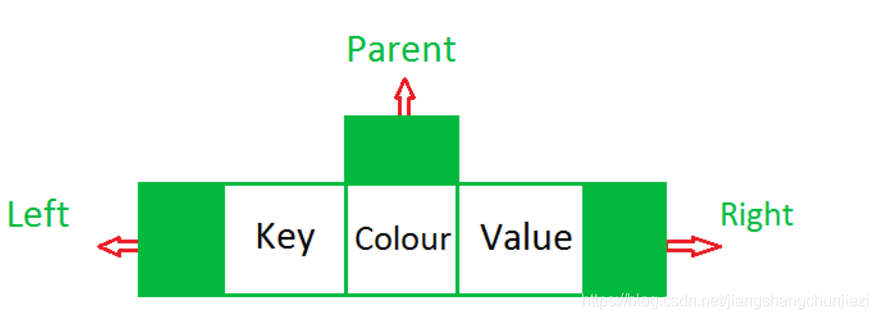
③put(K key, V value)
public V put(K key, V value) {
Entry<K,V> t = root; //红黑树是一种自平衡二叉查找树
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
//类型1:given comparator
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
//类型2:natural ordering:comparable
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
3.V get(Object key)
public V get(Object key) {
Entry<K,V> p = getEntry(key);
return (p==null ? null : p.value);
}
//优先级:comparator > comparable
final Entry<K,V> getEntry(Object key) {
// Offload comparator-based version for sake of performance
if (comparator != null)
return getEntryUsingComparator(key);
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
Entry<K,V> p = root;
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
return null;
}
4.自定义TreeMap中key:实现Comparable或Comparator
实现Comparator<T>中compare<T o1,T o2> :这是key类应该实现的
class Student {
int rollno;
String name, address;
// Constructor
public Student(int rollno, String name,
String address)
{
this.rollno = rollno;
this.name = name;
this.address = address;
}
// Used to print student details in main()
public String toString()
{
return this.rollno + " "
+ this.name + " "
+ this.address;
}
}
实现Comparator写法一:单独封装类
// Comparator implementattion
class Sortbyroll implements Comparator<Student> {
// Used for sorting in ascending order of
// roll number
public int compare(Student a, Student b)
{
return a.rollno - b.rollno; //若rollno相同,则Student为相同对象
}
}
//测试:
public static void main(String args[]) {
// Creating an empty TreeMap
TreeMap<Student, Integer> tree_map
= new TreeMap<Student, Integer>(new Sortbyroll());
// Mapping string values to int keys
tree_map.put(new Student(111, "bbbb", "london"), 2); //①
tree_map.put(new Student(131, "aaaa", "nyc"), 3);
tree_map.put(new Student(111, "cccc", "jaipur"), 1);
//与①是相同对象,所以为更新操作
Set<Student> s=tree_map.keySet();
Iterator<Student> it1=s.iterator();
while(it1.hasNext())
{
Student str=it1.next();
System.out.println("键: "+str+" 值:"+tree_map.get(str));
}
}
// 输出:
键: 111 bbbb london 值:1
键: 131 aaaa nyc 值:3
实现Comparator写法二:匿名内部类
匿名内部类
TreeMap<Student, Integer> tree_map1
= new TreeMap<Student, Integer>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.rollno - o2.rollno;
}
});
四、HashMap vs TreeMap
不同点:
-
ordering:HashMap无序,TreeMap按Key排序
HashMap is not ordered, while TreeMap sorts by key. How items are stored depends on the hash function of the keys and seems to be chaotic(混乱).
TreeMap, which implements not only Map but also NavigableMap automatically sorts pairs by their keys natural orders (according to their compareTo() method or an externally supplied Comparator). -
Performance:操作速度、空间
HashMap is faster and provides average constant time performance O(1) for the basic operations get() and put(), if the hash function disperses(分散) the elements properly among the buckets. It usually works as is, but in reality sometimes collisions(冲突) happen. In this case HashMap handles collision using a linked list to store collided elements and performance reduces up to O(n).
To improve the performance in case of frequent collisions, in JDK 8 is used balanced tree instead of linked list. JDK8 switches to balanced tree in case of more than 8 entries in one bucket, it improves the worst-case performance from O(n) to O(log (n)).
According to its structure, HashMap requires more memory than just to keep its elements. The performance of a hash map depends on two parameters — Initial Capacity and Load Factor. The Initial Capacity is a quantity of buckets of a new created HashMap. The load factor measures a percentage of fullness. The default initial capacity is 16 and default load factor is 0.75. We can change these values.
load factor(加载因子)
null(分析put源码)
HashMap中key只能1个null,多个value为null
TreeMap中 NullPointerException - if the specified key is null and this map uses natural ordering, or its comparator does not permit null keys.
比如put中,compare(key, key); 则①是k1.comparaTo(k2)若k1为null,则抛空指针异常
②是两个对象比较,是否抛异常,取决于自定义的compare是怎么实现的。
final int compare(Object k1, Object k2) {
return comparator==null ? ((Comparable<? super K>)k1).compareTo((K)k2)//①
: comparator.compare((K)k1, (K)k2); //②
}
相同点
Both TreeMap and HashMap implement the Map interface, so they don’t support duplicate keys. (可以从treemap和hashmap的put代码看出)
They are not thread-safe, so you can’t use them safely in a multi-threaded application.
线程安全:
SortedMap m = Collections.synchronizedSortedMap(new TreeMap(...));
Map m = Collections.synchronizedMap(new HashMap(...));

















 1529
1529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









