







LLM 发展简史:带你看懂 NLP 进化史,从 NLP 到 LLM 的非凡旅程(一)!
目录
四、Transformer 和预训练模型的崛起(2020年代)
- Transformer模型
- Transformer(2017年):Vaswani等人提出的Transformer模型,基于自注意力机制,显著提高了并行计算效率和性能。
- BERT(2018年):谷歌提出的双向编码器表示,从双向上下文中学习语义信息,在多项NLP任务上取得了突破性成果。
- 预训练和微调
- GPT系列:OpenAI的GPT模型,通过大规模预训练和任务微调,实现了高质量的文本生成、对话系统等应用。
- T5和BART:其他预训练模型,如谷歌的T5和Facebook的BART,进一步推动了NLP技术的发展。
- Transformer创始八子
- Jakob:提出用自注意力机制替换RNN的想法,并开始评估。
- Ashish与Illia:设计并实现了第一个Transformer模型,并在工作中发挥了关键作用。
- Noam:提出了缩放点积注意力、多头注意力和无参数位置表示,并深入参与工作细节。
- Niki:在原始代码库和tensor2tensor中设计、实现、调优和评估模型变体。
- Llion:尝试新型模型变体,负责初始代码库,以及高效推理和可视化。
- Lukasz和Aidan:设计和实现tensor2tensor,取代早期代码库,改进结果,加速研究。

1. 解读 Transformer
1. 介绍
Transformer 是一种基于注意力机制(Attention Mechanism)的神经网络,最初用于机器翻译任务。由于其高效的并行计算能力和出色的性能。Transformer 在 NLP 领域广泛应用,解决了传统序列模型在长序列处理上的瓶颈问题,显著提升了NLP任务的性能和效率。
2. 结构
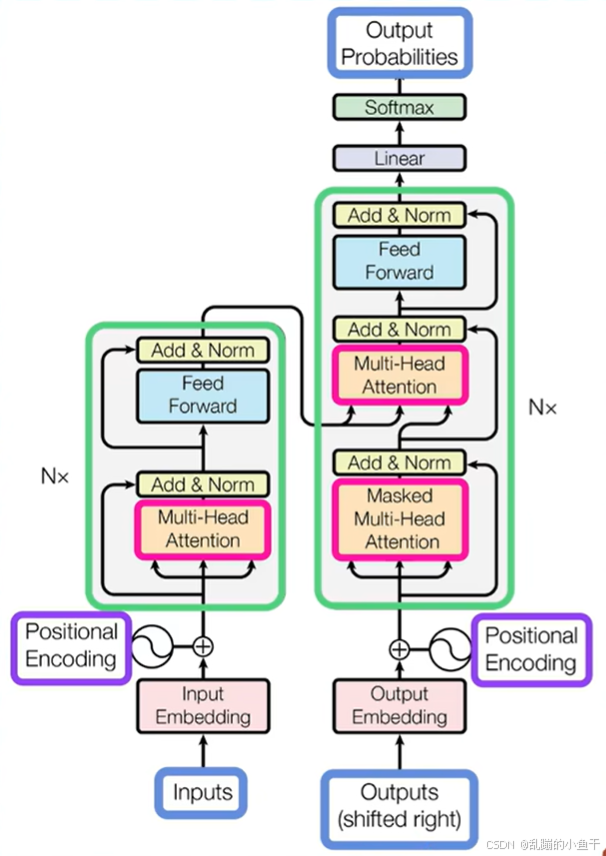
-
编码器(Encoder):由多层堆叠的相同结构组成,每层包括多头自注意力机制和前馈神经网络。
- 多头自注意力机制(Multi-Head Self-Attention Mechanism):
- 自注意力机制允许每个位置的表示向量(词或子词)根据序列中的其他位置进行更新。
- 多头机制是指在不同的子空间中同时执行多个自注意力计算,然后将它们的结果拼接并线性变换。
- 注意力层只是做线性组合(加权平均),本身是线性的,不会改变输入数据的线性结构。
- 前馈神经网络(Feed-Forward Neural Network):
- 在每个位置上独立地应用两个线性变换和一个ReLU激活函数,,它负责对每个位置(token)的表示进行非线性变换和特征提取。
第一层线性变换:提取初步特征
非线性变换(如 ReLU):引入非线性,打破线性限制
第二层线性变换:映射回原始维度
- 多头自注意力机制(Multi-Head Self-Attention Mechanism):
-
解码器(Decoder):解码器与编码器类似,但每个解码器层多了一个子层,编码器-解码器注意力机制:
- 多头自注意力机制:
- 类似于编码器的自注意力,但只关注解码器先前位置的表示,确保预测时不会看到未来的信息(通过掩码机制实现)。
- 编码器-解码器注意力机制(Encoder-Decoder Attention Mechanism):
- 这个子层通过注意力机制在解码器的位置和编码器的输出之间建立联系,帮助解码器利用输入序列的信息进行预测。
- 前馈神经网络:
- 与编码器中的前馈神经网络相同。
- 多头自注意力机制:
-
多头自注意力机制(Multi-Head Self-Attention):通过在多个子空间中独立计算注意力,捕捉序列中的依赖关系,并将它们的结果拼接在一起,然后通过线性变换合并,增强了模型的表达能力。具体来说,多头注意力机制包括以下步骤:
- 线性变换:将输入分别线性变换为查询(Query)、键(Key)、值(Value)矩阵。
- 计算注意力:在每个头上计算注意力分数,然后加权求和得到输出。
- 拼接和线性变换:将所有头的输出拼接起来,并通过线性变换得到最终的多头注意力输出。

-
位置编码(Positional Encoding):由于Transformer没有循环和卷积,无法处理序列的顺序信息。为了引入序列中的位置信息,Transformer使用了位置编码(Positional Encoding)。位置编码向量被加到输入嵌入(Input Embeddings)中,使得模型能够区分不同位置的词。
3. 应用及翻译案例
- 自然语言理解:如文本分类、命名实体识别。
- 机器翻译:将一种语言翻译成另一种语言。
- 文本生成:生成高质量的自然语言文本。
Transformer架构被广泛应用于各种NLP任务,包括机器翻译(如Google的BERT和OpenAI的GPT系列)、文本生成、摘要生成和问答系统等。
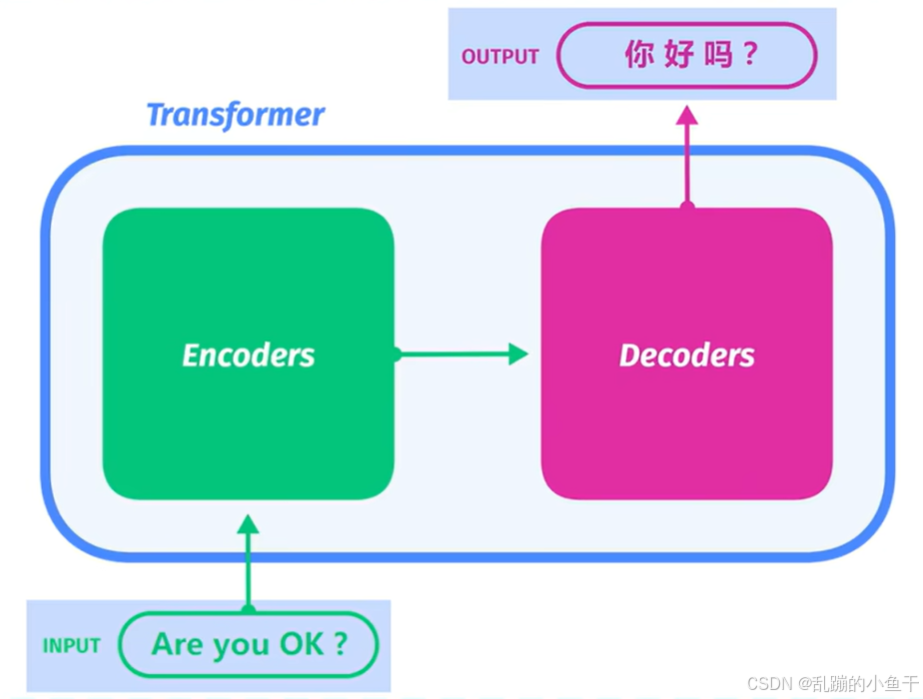
翻译案例:
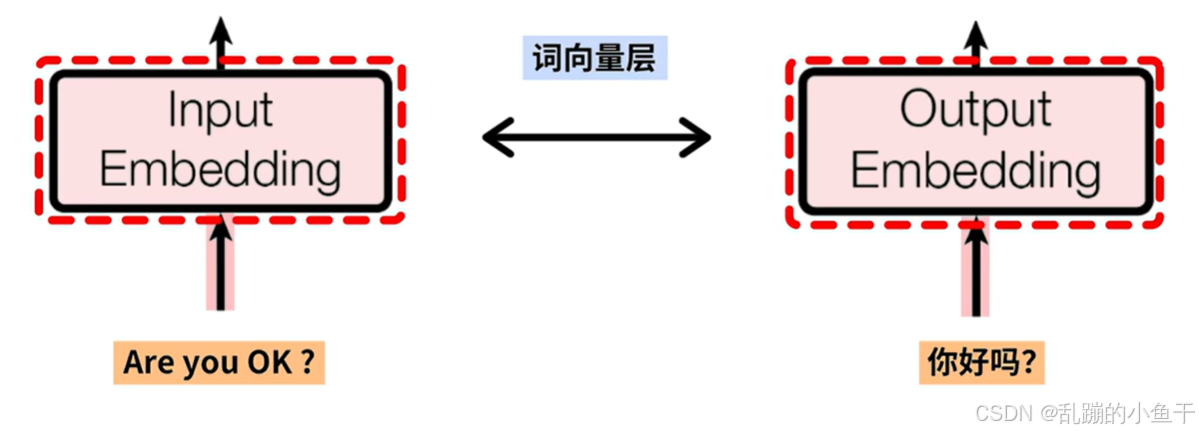
Input Embedding 负责将输入的离散词汇(即单词或子词的索引)转换为连续的、密集的向量表示,便于模型进行处理。这是因为深度学习模型(包括Transformer)并不能直接操作词汇表中的离散符号,必须将这些符号映射为可以处理的向量形式。(eg:用于指导生成中文翻译。)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









