







 本文介绍了常用的分词方法,包括基于词典的最大长度匹配(前向和后向查找),并强调了后向查找的优势。文中详细解释了如何利用Trie树来优化词典查找过程,并通过Jieba分词器实例,展示了其如何生成有向无环图(DAG)以进行高效分词,采用动态规划找到最大概率路径,并使用HMM模型和Viterbi算法处理未登录词。
本文介绍了常用的分词方法,包括基于词典的最大长度匹配(前向和后向查找),并强调了后向查找的优势。文中详细解释了如何利用Trie树来优化词典查找过程,并通过Jieba分词器实例,展示了其如何生成有向无环图(DAG)以进行高效分词,采用动态规划找到最大概率路径,并使用HMM模型和Viterbi算法处理未登录词。
最常见的分词方法是基于词典匹配
– 最大长度查找(前向查找,后向查找)
后向查找准确
数据结构
– 为了提高查找效率,不要逐个匹配词典中的词
– 查找词典所占的时间可能占总的分词时间的1/3左右,为了保证切分速度,需要选择一个好的查找词典方法
– Trie树常用于加速分词查找词典问题
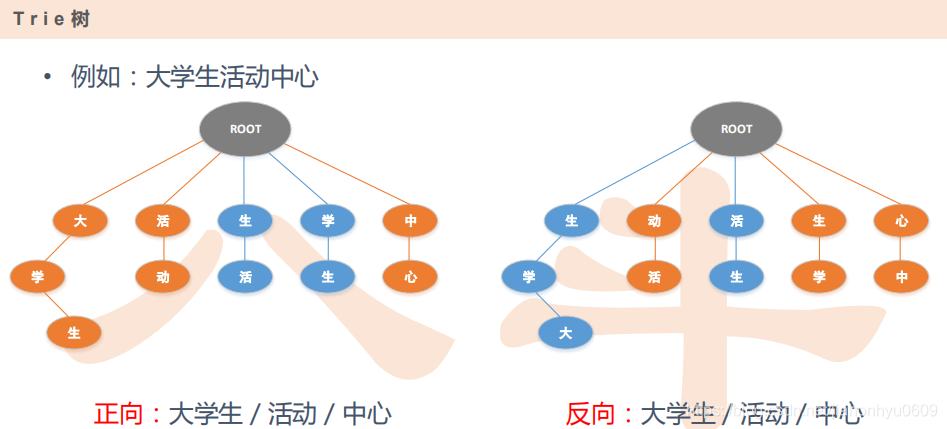
说明反向比较好,正向的话有歧义
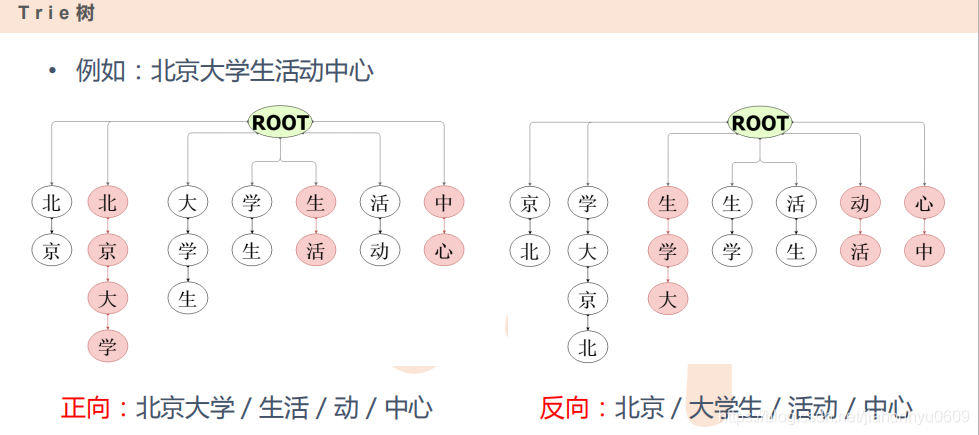
贝叶斯公式:
大学生
大学
大脑
大型活动 p(w2=学|w1=大)=p(大,学)/p(大)=2/4=0.5
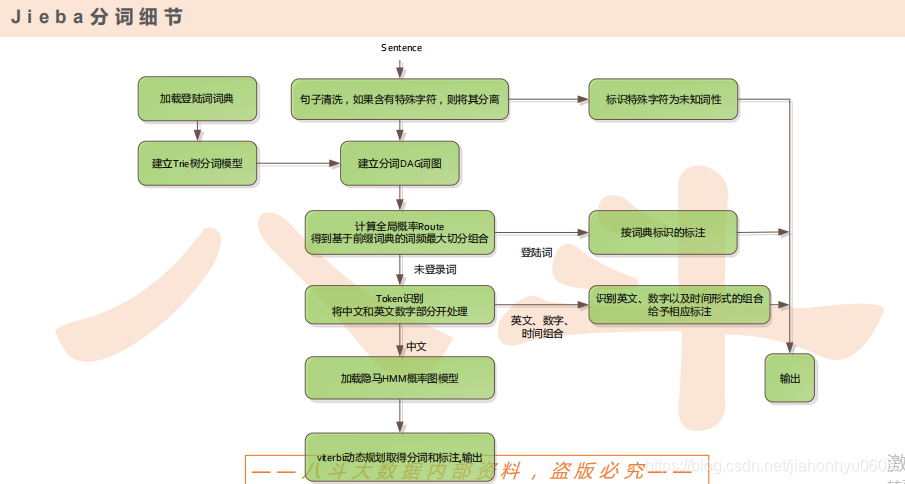
J i e b a 分 词 简 介:
•基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成
的有向无环图(DAG)
• 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
• 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法做预测。
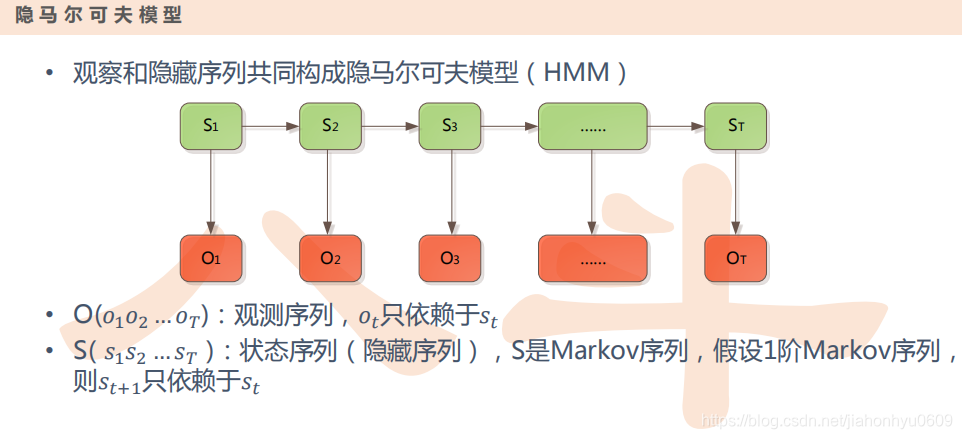
我们输入的拼音是隐藏层,还有语音也是隐藏层,出来的汉子就是观察层。
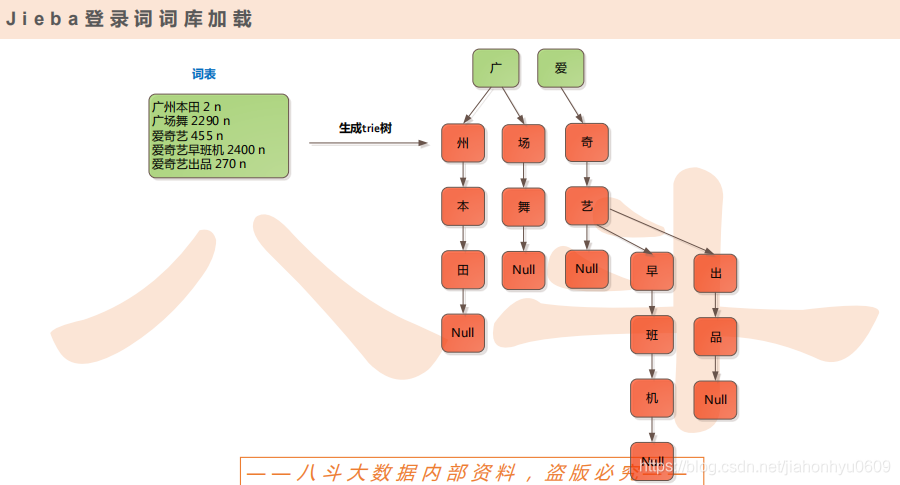
1.登录词词库加载
2.生成DAG词图
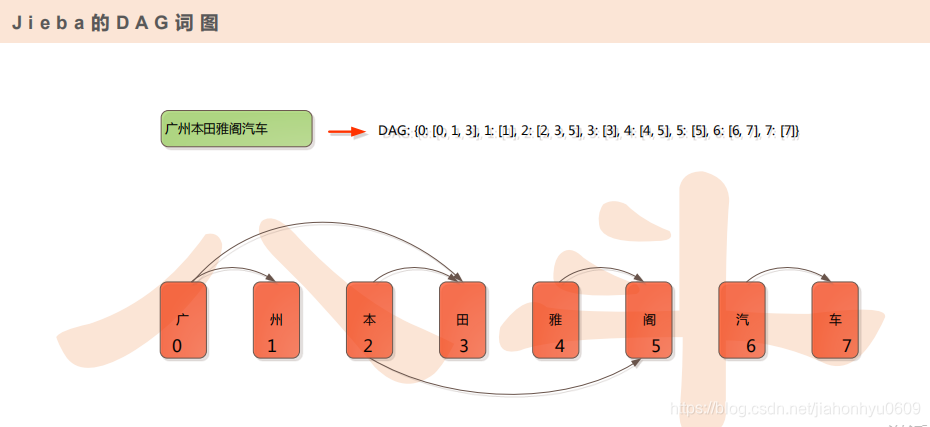
3.获取全局概率Route,获得词频最大切分,负数是取了log,从后往前算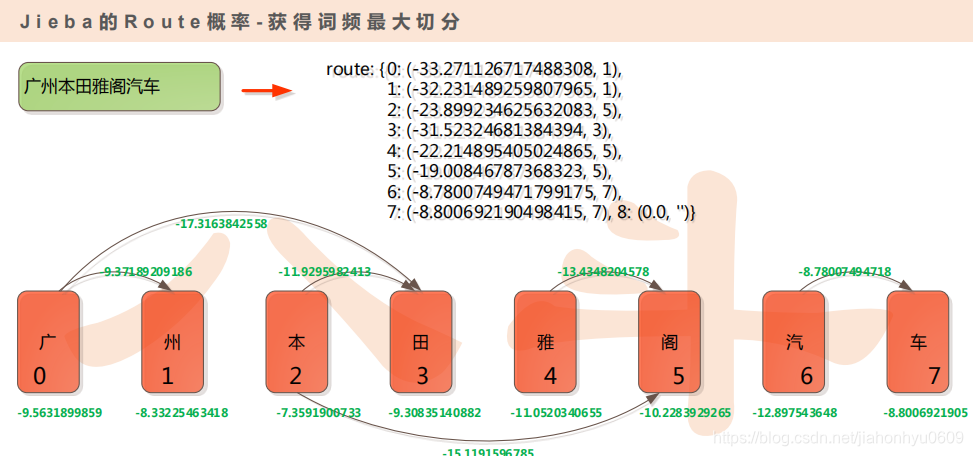
4.token识别,吧中文,英文,数字分开,对于中文的用HMM记载,最后用viterbi取得分词输出。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









