







一、锁一个联合索引(for update)能不能锁上?
来源:2024-9 淘宝技术一面
首先弄明白,select for update会加什么样的锁?他会对表记录加X型的行级锁。
在可重复读隔离级别下,行级锁的种类除了有记录锁,还有间隙锁(目的是为了避免幻读),所以行级锁的种类主要有三类:
-
Record Lock,记录锁,也就是仅仅把一条记录锁上;
-
Gap Lock,间隙锁,锁定一个范围,但是不包含记录本身;
-
Next-Key Lock:Record Lock + Gap Lock 的组合,锁定一个范围,并且锁定记录本身。
加锁的对象是索引,加锁的基本单位是 next-key lock,它是由记录锁和间隙锁组合而成的,next-key lock 是前开后闭区间,而间隙锁是前开后开区间。 但是,next-key lock 在一些场景下会退化成记录锁或间隙锁。
情况分类:
1. 当我们用唯一索引进行等值查询的时候,
查询的记录存不存在,加锁的规则也会不同:
-
当查询的记录是「存在」的,在索引树上定位到这一条记录后,将该记录的索引中的 next-key lock 会退化成「记录锁」。
-
当查询的记录是「不存在」的,在索引树找到第一条大于该查询记录的记录后,将该记录的索引中的 next-key lock 会退化成「间隙锁」。
2. 当唯一索引进行范围查询时,
会对每一个扫描到的索引加 next-key 锁,然后如果遇到下面这些情况,会退化成记录锁或者间隙锁:
-
情况一:针对「大于等于」的范围查询,因为存在等值查询的条件,那么如果等值查询的记录是存在于表中,那么该记录的索引中的 next-key 锁会退化成记录锁。
-
情况二:针对「小于或者小于等于」的范围查询,要看条件值的记录是否存在于表中:
-
当条件值的记录不在表中,那么不管是「小于」还是「小于等于」条件的范围查询,扫描到终止范围查询的记录时,该记录的索引的 next-key 锁会退化成间隙锁,其他扫描到的记录,都是在这些记录的索引上加 next-key 锁。
-
当条件值的记录在表中,如果是「小于」条件的范围查询,扫描到终止范围查询的记录时,该记录的索引的 next-key 锁会退化成间隙锁,其他扫描到的记录,都是在这些记录的索引上加 next-key 锁;如果「小于等于」条件的范围查询,扫描到终止范围查询的记录时,该记录的索引 next-key 锁不会退化成间隙锁。其他扫描到的记录,都是在这些记录的索引上加 next-key 锁。
-
3. 针对非唯一索引等值查询时,
查询的记录存不存在,加锁的规则也会不同:
-
当查询的记录「存在」时,由于不是唯一索引,所以肯定存在索引值相同的记录,于是非唯一索引等值查询的过程是一个扫描的过程,直到扫描到第一个不符合条件的二级索引记录就停止扫描,然后在扫描的过程中,对扫描到的二级索引记录加的是 next-key 锁,而对于第一个不符合条件的二级索引记录,该二级索引的 next-key 锁会退化成间隙锁。同时,在符合查询条件的记录的主键索引上加记录锁。
-
当查询的记录「不存在」时,扫描到第一条不符合条件的二级索引记录,该二级索引的 next-key 锁会退化成间隙锁。因为不存在满足查询条件的记录,所以不会对主键索引加锁。
4. 非唯一索引范围查询
不同之处在于非唯一索引范围查询,索引的 next-key lock 不会有退化为间隙锁和记录锁的情况,也就是非唯一索引进行范围查询时,对二级索引记录加锁都是加 next-key 锁。
5. 没有加索引的查询
如果锁定读查询语句,没有使用索引列作为查询条件,或者查询语句没有走索引查询,导致扫描是全表扫描。那么,每一条记录的索引上都会加 next-key 锁,这样就相当于锁住的全表,这时如果其他事务对该表进行增、删、改操作的时候,都会被阻塞。
二、索引失效有哪些情况?
来源:2024-7拼多多技术一面
(1)最左前缀法则不满足
在MySQL建立联合索引时会遵守最佳左前缀原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。
原理:
先弄清楚mysql索引本质存储格式,如下图所示:
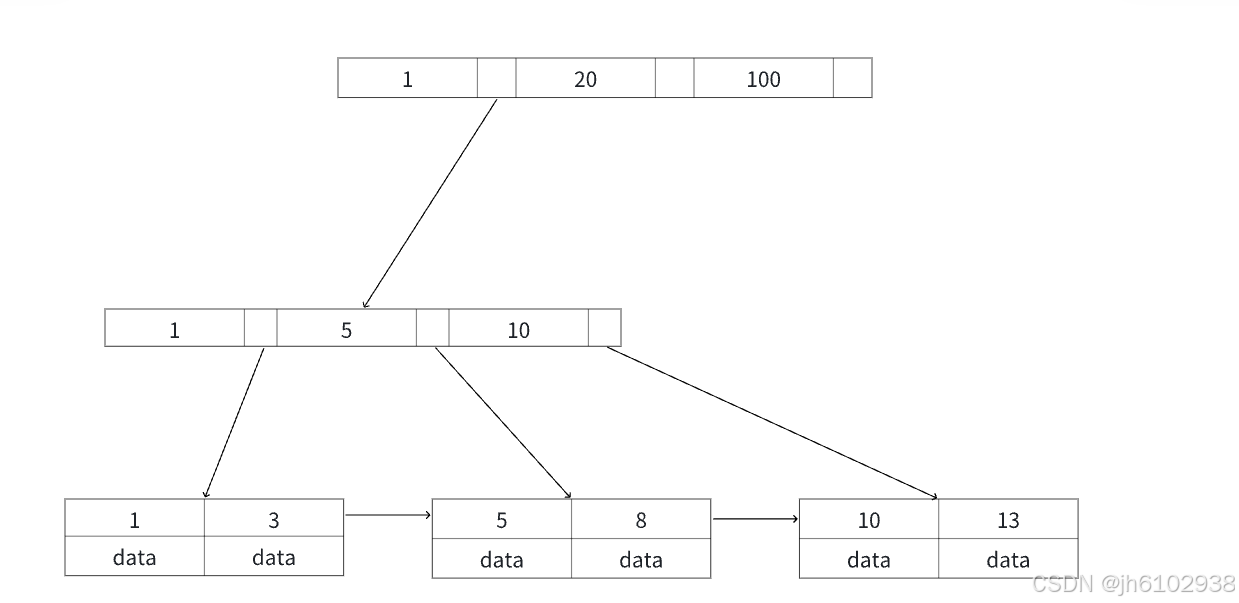
1:非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
2:叶子节点包含所有索引字段
3:叶子节点用指针连接,提高区间访问的性能
联合索引为多值的索引结构
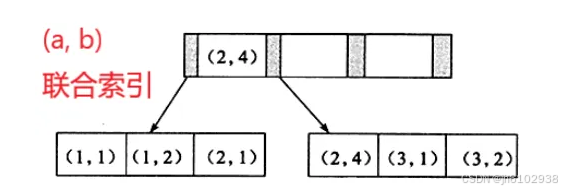
当我们只分析a时发现它是有序的,只分析b时则是无序的,当我们限定了a值时,连带的b变为有序。这就是联合索引的原理,当a本身有序的情况下,a值确定的情况下,那么整体都是有序的,也就验证了最左前缀法则。
(2)使用了select *
在《阿里巴巴开发手册》中明确说过,查询sql中禁止使用select *
原理:
如果select语句中的查询列,都是索引列,那么这些列被称为覆盖索引。这种情况下,查询的相关字段都能走索引,索引查询效率相对来说更高一些。
而使用select *查询所有列的数据,大概率会查询非索引列的数据,非索引列不会走索引,查询效率非常低。
这里就涉及到了覆盖索引和回表的概念。
"覆盖索引"指的是索引中已经包含了查询需要的所有字段,所以不需要回表。覆盖索引查询可以直接从索引中获取所有数据,大大提高查询效率。
"回表"指的是查询过程在使用索引获取一部分信息后,还需要到主表中再次查找数据。一般来说,回表查询的发生是因为索引中并不包含所有需要的字段
举个简单的例子,有user表,里面包含id,name,age字段,其中id为唯一索引,name普通索引,当使用select *时,age字段并不在索引上,所以需要通过主键回主表进行数据补充,也就是回表,则查询效率就会减慢。反之如果建立name,age联合索引,那么查询即可在索引上查到所有数据,这就是覆盖索引。
(3)索引列上有计算
(4)索引列用了函数
(5)字段类型不同
(6) like左边包含%
那么,为什么会出现这种现象呢?可以类比最左前缀法则。
答:其实很好理解,索引就像字典中的目录。一般目录是按字母或者拼音从小到大,从左到右排序,是有顺序的。
我们在查目录时,通常会先从左边第一个字母进行匹对,如果相同,再匹对左边第二个字母,如果再相同匹对其他的字母,以此类推。
通过这种方式我们能快速锁定一个具体的目录,或者缩小目录的范围。
(7)使用or关键字
如果使用了or关键字,那么它前面和后面的字段都要加索引,不然所有的索引都会失效
(8)not in和not exists
MySQL 会在选择索引的时候进行优化,如果 MySQL 认为全表扫描比走索引+回表效率高, 那么他会选择全表扫描。也就是not in和not exists有可能走索引也有可能不走,这要看mysql优化器。
(9)order by
有些情况下的order by是可能不走索引的,这点很容易被人忽略。
1. 如果order by语句中没有加where或limit关键字,该sql语句将不会走索引。
2. 对不同的索引做order by
3. 不满足最左匹配原则
4. 不同的排序
例如查询user表
order by name asc,age desc limit 100;三、怎么看sql语句用没用索引?
来源:2024-06滴滴测开一面
使用explain来查看sql语句的执行计划。
如下图所示:
mysql> explain select * from test \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 13
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
这里内容很多,但是值得我们关注的只有这几个字段
- type
- rows
- Extra
type
表示 MySQL 在执行当前语句时候执行的类型,有这几个值 system,const,eq_ref,ref,fulltext,ref_or_null,index_merge,unique_subquery,index_subquery,range,index,ALL。
- system 比较少见,当引擎是 MyISAM 或者 Memory 的时候并且只有一条记录,就是 system,表示可以系统级别的精准访问,这个不常见可以忽略。
- const 查询命中的是主键或者唯一二级索引等值匹配的时候。比如
where id = 1 - eq_ref 连表时候可以使用主键或者唯一索引进行等值匹配的时候。
- ref 和 ref_or_null, 当非唯一索引和常量进行等值匹配的时候。只是 ref_or_null 表示查询条件是
where second_key is null - fulltext, index_merge不常见跳过。
- unique_subquery 和 index_subquery 表示联合语句使用 in 语句的时候命中了唯一索引或者普通索引的等值查询。
- range 表示使用索引的范围查询,比如
where second_key > 10 and second_key < 90 - index 我们命中了索引,但是需要全部扫描索引。
- All,这个太直观了,就是说没有使用索引,走的是全表扫描。
rows
表示MySQL 在执行语句的时候,评估预计扫描的行数。
Extra
Using index,当我们查询条件和返回内容都存在索引里面,就可以走覆盖索引,不需要回表,比如 select second_key from test where second_key = 10
Using index condition,经典的索引下推,虽然命中了索引,但是并不是严格匹配,需要使用索引进行扫描对比,最后再进行回表,比如 select * from test where second_key > 10 and second_key like '%0';
Using where,当我们使用全表扫描时,并且 Where 中有引发全表扫描的条件时,会命中。比如 select * from test where text = 't'
Using filesort,查询没有命中任何索引,需要在内存或者硬盘中排序的,比如 select * from test where text = 't' order by text desc limit 10
四、聚簇索引和非聚簇索引的区别
来源:2024-12快手技术一面
在MySQL中,聚簇索引和非聚簇索引是两种不同的索引存储方式,主要区别在于数据的物理存储方式和索引结构。以下是它们的区别:
1. 聚簇索引(Clustered Index)
-
数据物理存储顺序:聚簇索引将数据按照主键顺序存储,数据行和索引存储在一起,物理上按顺序排列。
-
主键为默认聚簇索引:在InnoDB存储引擎中,主键默认就是聚簇索引。如果没有主键,则选择一个唯一的非空列;如果没有唯一的列,则MySQL会自动生成一个隐藏的行ID作为聚簇索引。
-
快速数据检索:聚簇索引在使用主键查询时非常高效,因为数据和索引在同一位置,不需要额外的查找步骤。
-
数据页分裂影响:由于数据按主键顺序存储,插入新数据时可能会触发数据页分裂,导致性能下降,尤其是在对主键频繁插入或更新的情况下。
-
每个表只能有一个聚簇索引:因为数据行只能按一种顺序存储,因此一个表只能有一个聚簇索引。
2. 非聚簇索引(Non-Clustered Index)
-
索引和数据分离:非聚簇索引将索引和数据存储在不同的物理位置。索引指向的是数据行的物理地址或主键值,而不是直接存储数据本身。
-
索引项包含指针:非聚簇索引的叶子节点存储的是指向数据行的指针(或主键),因此在使用非聚簇索引查询时,通常需要一次额外的回表操作来检索完整数据。
-
可以有多个非聚簇索引:一个表可以有多个非聚簇索引,这些索引用于非主键列上的查询。
-
适合频繁更新的列:因为数据和索引分离,非聚簇索引在更新时不会像聚簇索引那样频繁导致数据页分裂,适合用于非主键列的高频查询和更新。
举个例子
假设有一个用户表users,以id列为主键:
-
聚簇索引:如果
id是主键,则它也是聚簇索引,数据行按id顺序存储在一起。在查询时,按id查找速度最快。 -
非聚簇索引:如果在
email列上创建索引,则是非聚簇索引。查询email时,MySQL会先通过非聚簇索引找到主键,然后回表查找完整的数据行。
总结
-
聚簇索引:数据按索引顺序存储,索引和数据在一起,查询主键更快,但影响频繁更新操作;每表只能有一个。
-
非聚簇索引:索引和数据分离,数据按原始顺序存储,适合多列查询和频繁更新,可以有多个。
五、explain命令时查询计划会执行吗 ?
来源:2024-11绿盟技术一面
使用EXPLAIN命令时,查询计划不会执行实际的查询操作。EXPLAIN命令用于模拟优化器执行SQL语句,分析查询的执行计划,而不是实际执行查询。通过在SELECT语句前添加EXPLAIN关键字,MySQL会在查询上设置一个标记,执行查询时会返回执行计划的信息,而不是执行实际的SQL语句。
六、mysql查询店铺销售额前三个的产品种类,怎么写sql?
来源:2024-08蔚来测开实习技术一面
注:MySQL从8.0版本开始支持窗口函数。
既然要分组统计每个店铺、每个商品的数据,先回忆一下具有分组统计功能的group by 和 partition by的区别:group by具有汇总的功能,只保留参与分组的字段和聚合函数的结果; 而partition by 能够保留全部数据,只对其中某些字段做分组统计,常与排序函数连用。
SELECT shop.shopname, goods.goodsname, a.sumprice, a.sumprice_rank FROM
(SELECT shopid,
goodsid,
SUM(salenum * price) AS sumprice,
ROW_NUMBER() OVER (PARTITION BY shopid ORDER BY SUM(salenum * price) DESC) AS sumprice_rank
FROM sales
WHERE orderdate > '2020-01-01'
AND orderdate < '2020-03-31'
GROUP BY shopid, goodsid) a
LEFT JOIN shop ON a.shopid = shop.shopid
LEFT JOIN goods ON a.goodsid = goods.goodsid
WHERE a.sumprice_rank <= 3
ORDER BY shopname, sumprice_rank;这里先从店铺售卖表里sum聚合商品卖的总价格,然后通过partition分类店铺,最后在最外层对聚合过后的数据进行排序选取前三。


















 256
256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











