







 本文介绍了word2vec模型的核心思想,它利用n元语法模型假设词与周围n个词相关,通过构建监督学习系统预测片段中的下一个单词。通过神经网络计算词汇的向量表示,经过迭代更新,最终得到每个词的独特向量,这种方法能揭示词汇间的相似性,适用于自然语言处理任务。
本文介绍了word2vec模型的核心思想,它利用n元语法模型假设词与周围n个词相关,通过构建监督学习系统预测片段中的下一个单词。通过神经网络计算词汇的向量表示,经过迭代更新,最终得到每个词的独特向量,这种方法能揭示词汇间的相似性,适用于自然语言处理任务。
词的向量化表示
word2vec模型的采用的思想是,n元语法模型(n-gram model),即假设一个词只与周围n个词有关,而与文本中的其他词无关
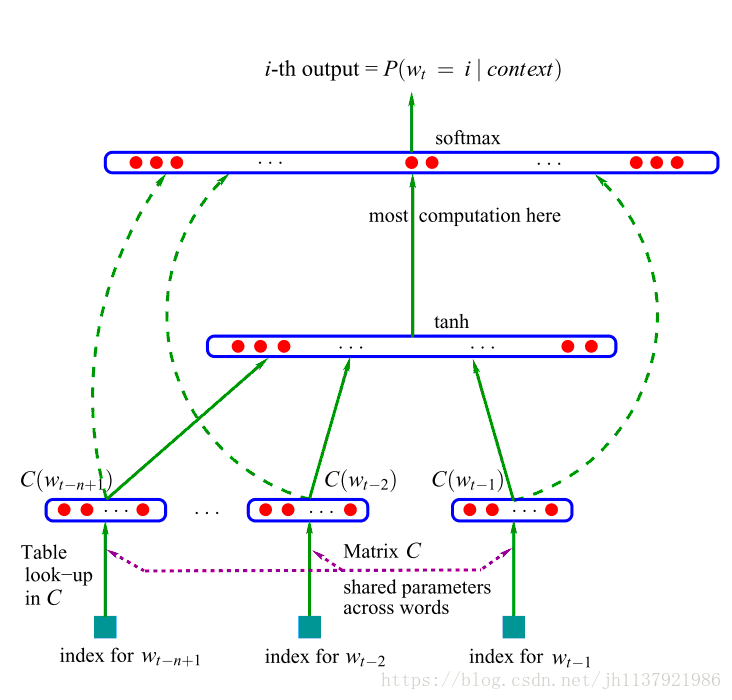
- 首先,我们要明确,句子中的连续词汇片段,也被称为上下文context,词汇之间的联系就是通过无数个这样的上下文建立的。以The cat is walking in the bedroom.为例,如果我们需要这句话中上下文数量为4(每一个片段中有4个词汇)的字段,那么就有The cat is walking、cat is walking in 、is walking in the 、walking in the bedroom共4个context;
- 从语言模型的角度来讲每个连续片段的最后一个单词究竟可能是什么,都会受到该片段中前面所有单词的制约,因此这就形成了一个根据片段中前面单词,预测最后一个单词的监督学习系统;
- 以神经网络框架来描述,当context数量为n(每一个片段中有n个词汇)时,提供给这个网络的输入都是前(n-1)个词汇片段,在下图中用浅蓝色矩形表示,最终指向的输出就是片段中的最后一个单词;
- 在网络中,需要计算的是这些词汇的向量表示,如C(W_t-1)表示要计算的是输入的片段中第(t-1)个单词的向量表示,图中每个红色实心圆都代表了某个词所对应的向量中的元素,实心圆的个数代表了词向量的维度,且所有词汇的维度是一致的;
- 通过不断迭代、更新参数,循环往复,最终获得每个词汇独特的向量表示。
实现代码:
#-*- coding:utf-8 -*-
#学习任务:使用genism工具包,对新闻文本进行词向量训练,并且通过抽样几个词汇,查验word2vec技术能否寻找到相似的词汇
from sklearn.datasets import fetch_20newsgroups
news = fetch_20newsgroups(subset='all')
X,y = news.data,news.target
#从bs4里导入BeautifulSoup
from bs4 import BeautifulSoup
#导入nltk,re工具包
import nltk,re
#定义一个函数名为news_to_sentences的方法,将每条新闻中的句子逐一剥离出来,并返回一个句子列表
def news_to_sentences(news):
#get_text(): Get all child strings, concatenated(串联) using the given separator.
news_text = BeautifulSoup(news).get_text()
tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
raw_sentences = tokenizer.tokenize(news_text)
sentences = []
for sent in raw_sentences:
#Python的re模块提供了re.sub用于替换字符串中的匹配项。
#语法:re.sub(pattern, repl, string, count=0, flags=0)
# pattern : 正则中的模式字符串。
# repl : 替换的字符串,也可为一个函数。
# string : 要被查找替换的原始字符串。
# count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
sentences.append(re.sub('[^a-zA-Z]',' ',sent.lower().strip()).split())
return sentences
#这里必须空一行
sentences=[]
#将长篇新闻文本中的句子剥离出来,用于训练
for x in X:
sentences += news_to_sentences(x)
#此处要空一行,表示下一步代码写在for循环外面
#从gensim.models导入word2vec
from gensim.models import word2vec
#配置词向量的维度
num_features=300
#被考虑的词汇的频度
#min-count 表示设置最低频率,默认为5,如果一个词语在文档中出现的次数小于该阈值,那么该词就会被舍弃
min_word_count = 20
#设定并行化训练使用CPU计算核心的数量
num_workers = 2
#定义上下文的窗口大小
context = 5
#定义下采样的值为10^-3
downsampling=1e-3
#训练词模型 Word2Vec
#参数说明 转自:(https://www.cnblogs.com/wuxiangli/p/7183476.html):
# sentences:可以是一个·ist,对于大语料集,建议使用BrownCorpus,Text8Corpus或·ineSentence构建。
# sg: 用于设置训练算法,默认为0,对应CBOW算法;sg=1则采用skip-gram算法。
# size:是指特征向量的维度,默认为100。大的size需要更多的训练数据,但是效果会更好. 推荐值为几十到几百。
# window:表示当前词与预测词在一个句子中的最大距离是多少
# alpha: 是学习速率
# seed:用于随机数发生器。与初始化词向量有关。
# min_count: 可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5
# max_vocab_size: 设置词向量构建期间的RAM限制。如果所有独立单词个数超过这个,则就消除掉其中最不频繁的一个。每一千万个单词需要大约1GB的RAM。设置成None则没有限制。
# sample: 高频词汇的随机降采样的配置阈值,默认为1e-3,范围是(0,1e-5)
# workers:控制训练的并行数。
# hs: 如果为1则会采用hierarchica·softmax技巧。如果设置为0(defau·t),则negative sampling会被使用。
# negative: 如果>0,则会采用negativesamp·ing,用于设置多少个noise words
# cbow_mean: 如果为0,则采用上下文词向量的和,如果为1(defau·t)则采用均值。只有使用CBOW的时候才起作用。
# hashfxn: hash函数来初始化权重。默认使用python的hash函数
# iter: 迭代次数,默认为5
# trim_rule: 用于设置词汇表的整理规则,指定那些单词要留下,哪些要被删除。可以设置为None(min_count会被使用)或者一个接受()并返回RU·E_DISCARD,uti·s.RU·E_KEEP或者uti·s.RU·E_DEFAU·T的函数。
# sorted_vocab: 如果为1(default),则在分配word index 的时候会先对单词基于频率降序排序。
# batch_words:每一批的传递给线程的单词的数量,默认为10000
model = word2vec.Word2Vec(sentences,workers=num_workers,\
size=num_features,min_count=min_word_count,\
window=context,sample=downsampling)
#这个设定代表当前训练好的词向量为最终版,也可以加快模型的训练速度
model.init_sims(replace=True)#1.利用训练好的模型,寻找训练文本中与morning最相关的十个词汇
model.most_similar('morning')输出:
[(u'afternoon', 0.8229345679283142), (u'weekend', 0.795312225818634), (u'evening', 0.747612476348877), (u'saturday', 0.7321940064430237), (u'night', 0.7067388296127319), (u'friday', 0.6979213356971741), (u'sunday', 0.6577881574630737), (u'monday', 0.6498968601226807), (u'summer', 0.649657666683197), (u'thursday', 0.6478739380836487)]#2.利用训练好的模型,寻找训练文本中与love最相关的十个词汇
model.most_similar('love')输出:
[(u'hate', 0.7348656058311462), (u'praise', 0.605739414691925), (u'pray', 0.5700856447219849), (u'die', 0.5681827068328857), (u'christ', 0.5652735829353333), (u'lord', 0.5511417388916016), (u'preach', 0.5481806397438049), (u'fear', 0.5467240810394287), (u'father', 0.5341935157775879), (u'eternal', 0.5326560735702515)]总结:在不使用语言学词典的前提下,词向量技术仍然可以借助上下文信息,找出词汇之间的相似性,这一技术可以作为基础模型应用到更加复杂的自然语言处理中。

















 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









