






说明:码代码复习(有些板块没时间就先不码代码了以后有时间补/用到了再说)
———————————————————
系统变量、用户变量、局部变量
(根据动力节点课件做的笔记,后期想要补充/修改可以回头对照动力节点视频和课件)
(1)系统变量(全局变量、会话变量):
①查看系统变量
show variables;
show global variables;
show variables like '%auto&';
select @@global.xxx;
select @@session.xxx;
select @@xxx;
———
②设置系统变量
set xxx=0/1;(0代表开,1代表关)
set global xxx=0/1;
set session xxx=0/1;
———————
(2)用户变量:
①定义用户变量并赋值
set @a='qwe';
set @b:='asd'
set @c:='zxc',@d:='rty';
———
②读取用户变量
select @a;
select @a,@b,@c;
———
③赋值用户变量
select @e:='fgh';
—
set @f:='vbn';
select @f;
———————
(3)局部变量:
①声明局部变量a、b
declare a type default xxx;
declare b type default xxx;
———
②给局部变量a赋值
set a:=xyz;(静态赋值)
select…into a from table;(动态赋值)
———
③读取局部变量a和b
select a,b;
———————————————————
❗️⭐️暂时没时间,以后再码一遍熟悉熟悉⭐️❗️
存储过程中的各种循环语句(和java等其他编程语言有关的一系列语法内容)
———————————————————
触发器(里面也用到了concat()函数)
insert触发器
drop trigger trigger_dept_insert if exits;
create trigger trigger_dept_insert
begin
after/before insert on dept for each row
insert into oper_log(id,oper_type,oper_time,oper_desc)values(null,'insert',now(),concat('插入数据:deptno=',new.deptno,',dname=',new.dname,',loc=',new.loc));
end;
update触发器
drop trigger trigger_dept_update if exits;
create trigger trigger_dept_update
after update dept on for each row
begin
insert into oper_log(id,oper_type,oper_time,oper_desc)
values(null,'update',now(),concat('更新数据,更新前:deptno=',old.deptno,',dname=',old.dname,',lod=',old.loc,',更新后:deptno=',new.deptno,',dname=',new.dname,',loc=',new.loc));
end;
delete触发器
drop trigger trigger_dept_delete if exits;
create trigger trigger_dept_delete
after delete on dept for each row
begin
insert into oper_log(id,oper_type,oper_time,oper_desc)
values(null,'delete',now(),concat('删除操作,删除的数据是:deptno=',old.deptno,',dname=',old.dname,',loc=',old.loc));
end;
———————————————————
存储引擎
①查看所有存储引擎:
show engines \G;
②指定存储引擎(建表时):
create table t1(int,varchar(20))engine=InnoDB;
③修改存储引擎(建表后指定存储引擎):
alter table t1 engine=MyISAM;
———————————————————
索引
1)给指定字段添加索引
①建表时添加索引:
create table t1(
name varchar(20),
index idx_name(name)
);
②建完表后期给字段添加索引:
方式一:alter table t1 add index idx_name(name);
方式二:create index idx_name on t1(name);
2)删除指定字段上的索引
alter table t1 drop index idx_name;
3)查看某张表上添加了哪些索引
show index from t1;
———————————————————
覆盖索引
为下面select语句创建覆盖索引进行sql查询优化→
select email form user where username='lucy';
所以创建覆盖索引的sql语句(感觉索引名里的user即表名还是别加了):
create index idx_user_username_email on user(username,email);
———————————————————
索引下推(基于多列索引)
为下面select语句创建索引下推(/多列字段的联合索引)进行sql查询优化→
select * from users where age>30 and city='London';
所以创建多列索引(索引下推基于多列索引)的sql语句:
alter table users add index idx_name_city_age(name,city,age) ;
———————
补:“覆盖索引”和“索引下推”各自的含义和两者区别→
1)覆盖索引,指的是select具体字段代替select *,将复合索引建立在要查询的具体字段上,这样在非聚集索引上,也就是第一颗B+树上就能拿到数据,从而不用“回表查询”。
①在username上建立一个索引:
create index index_username on sys_user(username);
②使用覆盖索引查询其中一条数据:
explain select username from sys_user where username='test_852107';
2)索引下推,是自MySQL5.6版本引入的一个新特性,目的也是减少“回表查询”,从而提升整体的查询效率。
①假设表中有三个字段name、age、sex,且创建了三者的联合索引,
②如果SQL写成下面这样,就会出问题,索引断开了,sex这个索引值是没有用上的:
select * from tuser where name ='zou' and sex=1;
③在5.6之前索引断了就不会往下走了,匹配到的所有name='zou'的数据,挨个“回表”,无疑这将会造成很多无意义的额外IO开销;
④而索引下推的意思是,索引断裂、走不下去后,不会立即回表,还会向下推一步再继续比较其它索引字段,从而减少无意义的额外IO。以上表为例,就是会匹配到name='zou'后发现索引断掉了也不会立即回表,而是继续向下比对sex是不是等于1;
———————————————————
单列索引
为下面select语句创建单列索引→
select * from student where student_id=123456;
创建单列索引的sql:
方式一:alter table student add index idx_student_id(student_id);
方式二:create index idx_student_id on student(student_id);
———————————————————
复合索引(组合索引)
为下面select语句创建复合索引→
select * from order where customerid=123453 and orderdate='2021-02-01';
创建复合索引的sql:
方式一:alter table order add index idx_customerid_orderdate(customer,orderdate);
方式二:create index idx_customer_orderdate on order(customer,orderdate);
———————————————————
sql性能分析工具
1)查看数据库整体情况
eg:查看insert操作在整个mysql服务期间所占比例情况
show global status like 'Com_insert';
2)慢查询日志
①查看慢查询日志是否开启
show variables like 'slow_query_log';
②修改my.ini文件来开启慢查询日志功能并设置记入慢查询日志的时长
[mysqld]
slow_query_log=1
long_query_time=3(或更大的数字)
———————————————————
show profiles
查看当前数据库是否支持profile操作
show have @@profiling;(yes支持,no不支持)
查看profiling开关是否打开
select @@profiling;(1开,0关)
将profiling开关打开
set profiling=1;
执行多条DQL语句,然后用show profiles;命令查看这几条DQL语句的耗时情况
select ename,empno from emp;
select count(*)from emp;
show profiles;
查看某个sql语句在执行过程中,每个阶段的耗时情况
show profile for query 4;
查看执行过程中cpu的情况
show profile cpu for query 4;
———————
补:关于 @@ 符号的作用
在 MySQL 中,@@ 表示访问全局或会话级别的系统变量。它有两种形式:
单个 @:通常用来声明用户自定义变量。
双 @ (@@):专门用于读取内置的系统配置参数,这些参数可能影响数据库的行为模式、安全性设定以及其他运行特性等。
———————————————————
explain
查询结果里id越大表示执行优先级越高(子查询subquery高于主查询primary)
explain select e.ename,d.dname form emp e join dept d on e.deptno=d.deptno join salgrade s on e.sal between s.losal and s.hisal;
explain select e.ename,d.dname form emp e join dept d on e.deptno=d.deptno where e.sal=(select sal from emp where ename='ford');
———————————————————
索引优化(加索引vs不加索引)
select * form t_vip where name='4c';
create index idx_t_vip_name on t_vip(name);
select * form t_vip where name='4c';
———————————————————
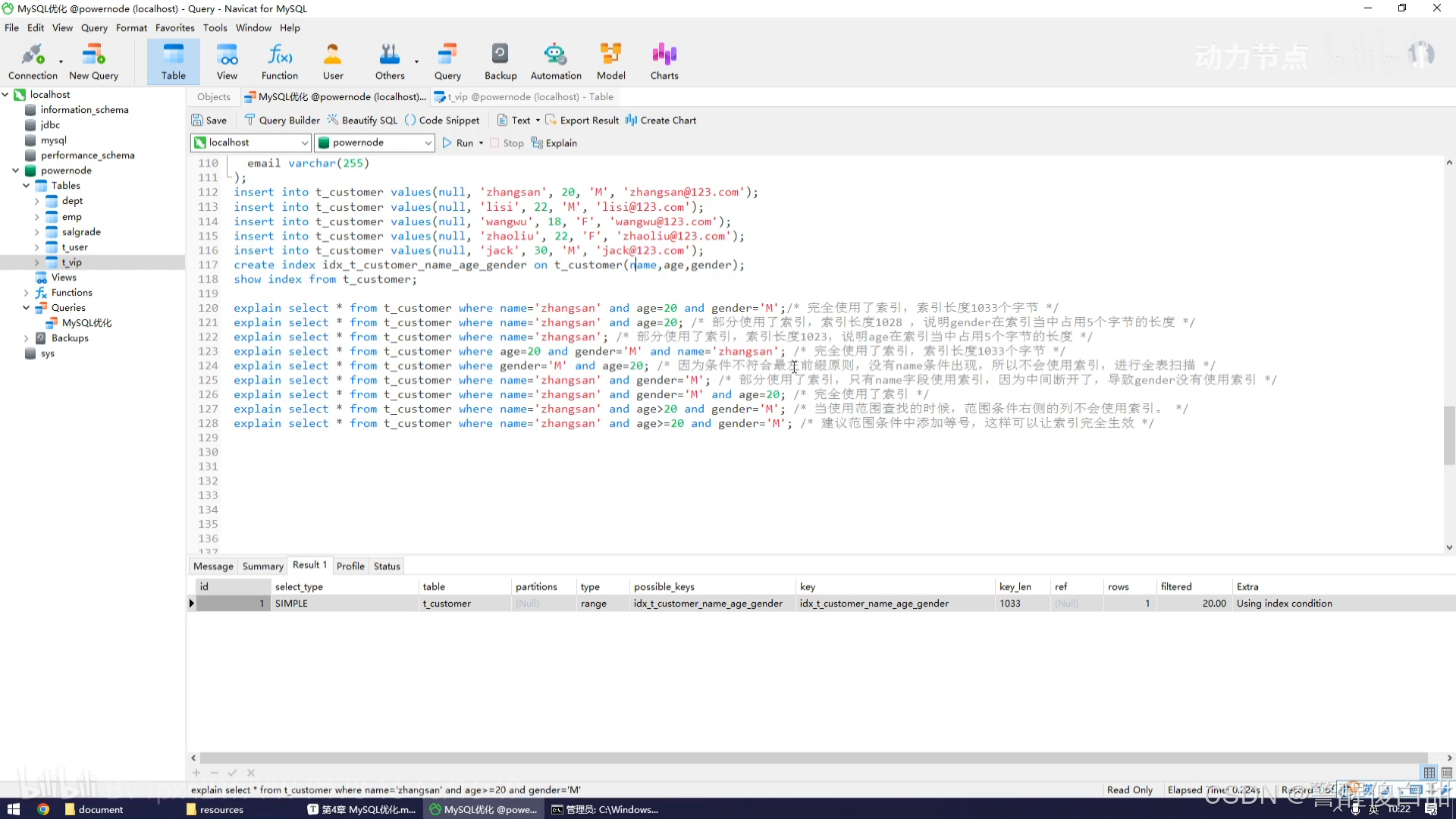
最左前缀法则
index:idx_name_age_gender(name,age,gender简称字段1,2,3)
①where筛选的条件中索引里的字段123全出现了则顺序怎样都不影响,都走索引
②where筛选的条件中索引里的字段只出现了12,则部分走索引即12走索引
③where筛选的条件中索引里的字段只出现了1,则部分走索引即1走索引
④where筛选的条件中索引里的字段出现了231,都出现了所以顺序怎样不影响,都走索引
⑤where筛选的条件中索引里的字段只出现了32,没出现最左边的索引即字段1的索引,所以全不走索引
⑥where筛选的条件中索引里的字段只出现了13,则部分走索引,中间断开,1走索引、3不走索引
⑦where筛选的条件中索引里的字段只出现了132,都出现了所以顺序怎样不影响,都走索引
⑧where筛选的条件中索引里的字段123全出现了但是2使用了不带等号=的范围查找,所以2右侧的列即3不走索引,而12都走索引
⑨where筛选的条件中索引里的字段123全出现了,2也使用了带等号=的范围查找,所以123都走索引
———————————————————
索引失效
①索引列参加运算,索引失效
explain select * from t_emp where sal*10>50000;
②索引列进行模糊查询时以%开始,索引失效
explain select * from t_emp where name like '%飞';
③索引是字符串类型,但查询时省略了单引号,索引失效
explain select * from t_emp where age=20;(正确的应该是:age='20';)
④查询条件中有or,只要有未添加索引的字段,索引失效
alter table t_emp drop index idx_t_emp_sal;
explain select * from t_emp where name='张三' or sal=5000;
⑤当查询的符合条件的记录在表中占比较大,索引失效
explain select * from emp2 where sal>1000;(占比大,不走索引)
explain select * from emp2 where sal>2000;(占比小,走索引)
⑥关于is null和is not null的索引失效问题(同⑤看占比决定走不走索引)
explain select * from emp2 where comm is null;
explain select * from emp2 where comm is not null;
———————————————————
指定索引
explain select * from t_customer where name='张三';
①建议使用该索引
use index(索引名称);
explain select * from t_customer use index(idx_t_customer_name) where name='张三';
②忽略某个索引
ignore index(索引名称);
explain select * from t_customer ignore index(idx_t_customer_name_age_gender) where name='张三';
③强行使用某个索引
force index(索引名称);
explain select * from t_customer force index(idx_t_customer_name) where name='张三';
———————————————————
覆盖索引
在select后面写字段的时候,这些字段尽可能是索引所覆盖的字段
create index idx_emp3_ename_job on emp3(ename,job);
explain select empno,ename,job from emp3 where ename='king';
———————————————————
前缀索引
①对长文本字段类型创建索引会导致索引体积过大,所以优化、将字段的前几个字符取来当前缀索引
create index idx_emp4_ename_2 on emp4(ename(2));
②使用前缀索引可以使用以下公式确定使用几个字符作为索引,公式计算的结果越大、越接近1表示索引的效果越好
select count(distinct substring(ename,1,2))/count(*)from emp4;
———————————————————
单列索引和复合索引怎么选择
依据select需求,如果select查询的是单个字段则给单个字段创建单列索引,如果查询的是多个字段则个多谢字段创建复合索引,略
———————————————————
order by优化
0)为order by后接的字段创建索引
eg:explain select id,name from workers order by name;
create index idx_workers_name on workers(name);
1)排序遵循最左前缀法则
2)使用覆盖索引
3)针对不同的排序规则,创建不同索引(如果所有字段都是升序,或者所有字段都是降序,则不需要创建新的索引)
eg:如果一个升一个降则为齐创建相应索引
explain select id,age,sal from workers order by age asc,sal desc;
create index idx_workers_ageasc_saldesc on workers(age asc,sal desc);
4)如果无法避免 filesort ,要注意排序缓存的大小,默认缓存大小256KB,可以修改系统变量 sort _ buffer _ size :
show variables like ' sort _ buffer _ size ';
———————————————————
group by优化
1)同样遵循最左前缀法则,为要查询的多个字段添加复合索引,为group by后接的字段创建索引
2)此外注意:复合索引最左边的那个字段不一定要group by后面,在where后面也行,只要出现且在复合索引里右边字段的前面出现就行,就都会走索引(即group by前面的where中使用了最左列索引就行)
eg:create index idx_empx_deptno_sal on empx(deptno,sal);
explain select sal,count(*)from empx where deptno=10 group by sal;
———————————————————
limit优化
覆盖索引(select的字段要有索引)+子查询(select的字段有索引且作为临时表t、与主查询进行join on表连接)
eg:
1)普通查询(慢)
select * from t_user order by id limit 9000000,2;
2)优化查询(快)→覆盖索引+子查询
①select id from t_user order by id limit 9000000,2;
②select u.* from t_user u join
(select id from t_user order by id limit 9000000,2)t
on u.id=t.id;
———————————————————
主键优化
1)主键值不要太长(导致索引占用空间太大)
2)尽量使用 auto _ increment 生成主键,尽量不要使用 uuld 做主键,因为 uuid 不是顺序插入。
3)最好不要使用业务主键,因为业务的变化会导致主键值的频繁修改,主键值不建议修改
4)在插入数据时,主键值最好是顺序插入,不要乱序插入
———————————————————
insert优化
1)数据量较大时,不要一条一条插入,可以批量插入,eg:
insert into t_user(id,name,age)values(1,'jack',20),(2,'lucy',30),(3,'timi',22);
2)mysql默认是自动提交事务,只要执行一条 DML 语句就自动提交一次,因此,当插入大量数据时,建议手动开启事务和手动提交事务,不建议使用数据库事务自动提交机制:
①修改事务提交方式,自动改为手动,然后出错手动回滚,没错手动commit
②查看/设置事务提交方式
select @@autocommit; -- 查看事务的提交方式,1是自动提交,0是手动提交
③set @@autocommit = 0; -- 把事务设置为手动提交
④开启事务:
start transaction 或 begin;
⑤提交事务:
commit;
⑥回滚事务:
rollback;
———
展示eg:
start transaction;
select * from account where name = 'A';
update account set money = money - 1000 where name = 'A';
update account set money = money + 1000 where name = 'B';
这里A会减少1000,B余额不会变。
commit; -- 提交,修改的是一张表的事务提交方式,每次执行操作后都要执行commit
rollback;
3)主键值建议采用顺序插入,顺序插入比乱序插入效率高。
4)超大数据量插入可以考虑使用 mysql 提供的 load 指令, load 指令可以将 csv 文件中的数据批量导入到数据库表当中,并且效率很高,步骤如下,eg:
-- ①客户端连接服务端时,加上参数 -–local-infile
mysql –-local-infile -u root -p
-- ②设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
set global local_infile = 1;
-- ③执行load指令将准备好的数据,加载到表结构中
load data local infile '/root/sql1.log' into table tb_user fields
terminated by ',' lines terminated by '\n' ;
———
简要版:
mysql --local-infile -u root -p
set global local_infile=1;
load data local infile 'xxx.xxx' into table tb_user fields terminated by ',' lines terminated by '\n';
———————————————————
count优化
1)count(主键)
原理:将每个主键值取出,累加
2)count(常量值)
原理:获取到每个常是值,累加
3)count(字段)
原理:取出字段的每个值,判断是否为 NULL ,不为 NULL 则累加
4)count(*)
原理:不用取值,底层 mysql 做了优化,直接统计总行数,效率最高。
———
结论:如果你要统计一张表中数据的总行数,建议使用 count (*)
———————————————————
update优化(❗️⭐️后期学完“锁”的内容后再补笔记码代码复习⭐️❗️)
开启事务后,
针对索引创建的的锁是行级锁,
如果索引失效了、或者不是索引列时,
会提升为表级锁

















 377
377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









