



 本文探讨迁移学习的概念及其应用场景,特别是如何通过微调(finetune)技术有效利用目标领域的少量标注数据,避免过拟合,同时介绍了多任务学习等其他迁移学习技巧。
本文探讨迁移学习的概念及其应用场景,特别是如何通过微调(finetune)技术有效利用目标领域的少量标注数据,避免过拟合,同时介绍了多任务学习等其他迁移学习技巧。
链接:https://www.zhihu.com/question/49534423/answer/191249820
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
迁移学习,个人感觉是一种思想吧,并不是一种特定的算法或者模型,目的是将已学习到的知识应用到其他领域,提高在目标领域上的性能,比如说一个通用的语音模型迁移到某个人的语音识别,一个ImageNet上的图片分类问题迁移到医疗疾病识别上。
作为知识的搬运工,下面的内容就要开始盗图大法了,台大李宏毅老师的slides,一个能把ML&DL讲成笑话的男人,非常推荐:
1. 首先,回答第一个问题?Why Transfer Learning?
迁移大法好,无论是语音、图片,还是文本处理,都有迁移学习的应用场景和实例,借助现有学习到的知识,能够很好的解决目标问题;
<img src="https://i-blog.csdnimg.cn/blog_migrate/c4ddb700687f30b9c52b34d9df6083f9.png" data-rawwidth="1410" data-rawheight="1024" class="origin_image zh-lightbox-thumb" width="1410" data-original="https://pic2.zhimg.com/v2-7c4ae21abed8ef8acf67190921a4586a_r.jpg">

2. 回答正题,fine tune和Transfer Learning的关系(经典技法之一吧,适用在source和target中都有标签数据集的情形)
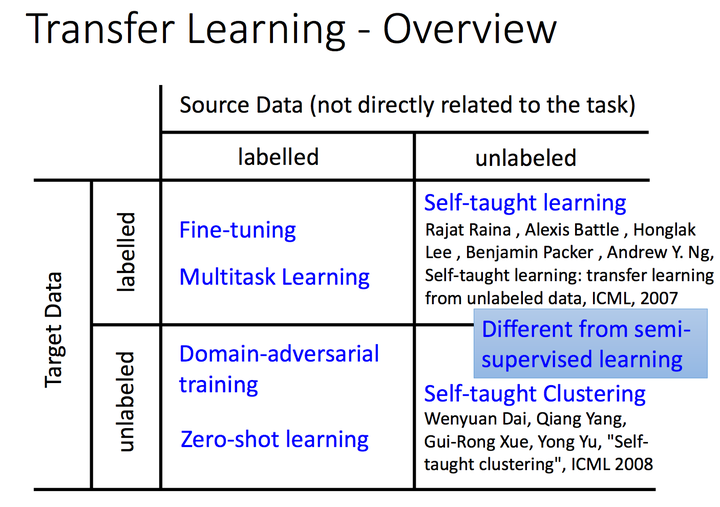
李宏毅老师按照源问题数据集和目标问题数据集是否有标签,可以像下图这样划分,方格中是典型的方法技巧,当然这种分类的标准有很多,像杨强老师早在08年的Trasfer Learning Survey中,就按照domain和task的划分方法,又进一步区分了instance transfer,feature transfer,parameter transfer,knowledge transfer;
<img src="https://i-blog.csdnimg.cn/blog_migrate/5170baaa898fb60d96c91bfc70e31a1f.png" data-rawwidth="1406" data-rawheight="990" class="origin_image zh-lightbox-thumb" width="1406" data-original="https://pic2.zhimg.com/v2-fcaf713f373f3f993829249c1041059f_r.jpg">
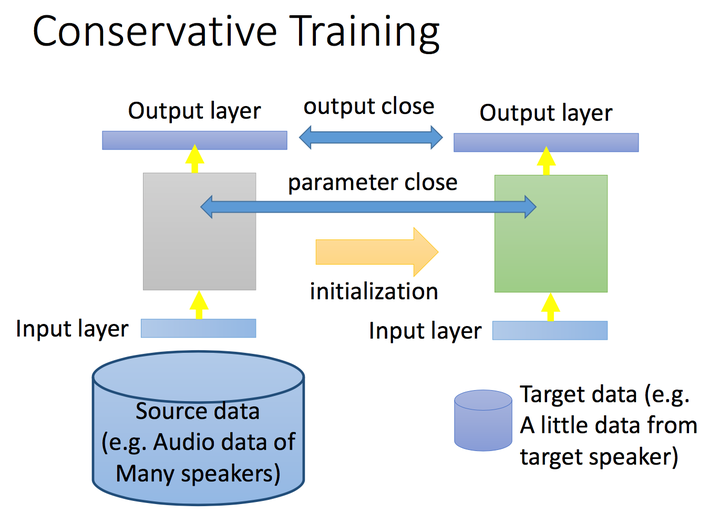
3. 具体聊一聊fine tune吧,应用情景是我们在target上有少量的label data,如何有效利用这部分label data,而且还不过拟合呢,我们以NN的角度为例,在原问题中学习到的NN,我们在target上采用保守学习的方式,比如让target和source上的输出尽可能相近,神经网络中间的参数尽可能相近,或者tune的时候,只tune某几层,其他层的参数不发生变化;
<img src="https://i-blog.csdnimg.cn/blog_migrate/b7c0fad154ff60a2805a8bee943c1759.png" data-rawwidth="1370" data-rawheight="998" class="origin_image zh-lightbox-thumb" width="1370" data-original="https://pic3.zhimg.com/v2-b74a86fc76cd60e0cc2554d760677e91_r.jpg">
<img src="https://i-blog.csdnimg.cn/blog_migrate/51c37551af443c7d258abee3d1b846e8.png" data-rawwidth="1440" data-rawheight="984" class="origin_image zh-lightbox-thumb" width="1440" data-original="https://pic3.zhimg.com/v2-26cf67b53ad6dac55c75b989e28c3f73_r.jpg">
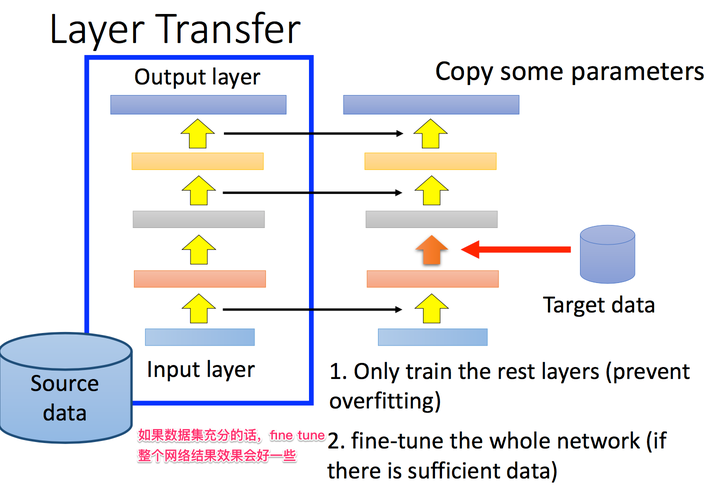
4. 不同领域的问题,在NN上fine tune的经验也不同,语音识别领域一般tune前几层,图片识别问题tune后面几层(背后的哲学,还请大神指点了);
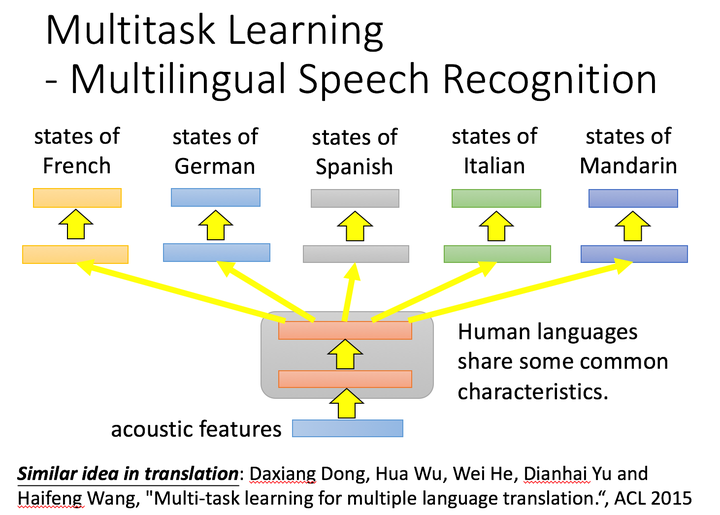
5. 最后举一下迁移学习中的其他技巧吧,比如multi-task learning,怎么说呢?multi-task学习的哲学是同时学,transfer learning的思想是先学习source,在学习target。但技巧还是可以应用的,比如ACL 2015的工作,同时进行多语音的语音识别,效果会好于单独一种语言的识别效果,底层共享神经元,学习到通用特征:
<img src="https://i-blog.csdnimg.cn/blog_migrate/5088d50e245c90e48f103fd0d45008f1.png" data-rawwidth="1462" data-rawheight="1046" class="origin_image zh-lightbox-thumb" width="1462" data-original="https://pic3.zhimg.com/v2-392ce77b235c80df5baa67e71aa0b506_r.jpg">
6. Transfer Learning中的其他技巧也都蛮有意思的,比如domain adversarial training,对抗的思想有点像GAN,通过source domain和target domain的数据投影到同一个空间内,再进行学习;
推荐材料:
1. http://kddchina.org/file/IntroTL2016.pdf
2. https://www.cse.ust.hk/~qyang/Docs/2009/tkde_transfer_learning.pdf
3. Hung-yi Lee
4. http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2017/Lecture/transfer.pdf

















 1294
1294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









