




 本文对比分析了HBase和Kudu两款分布式存储系统。Kudu借鉴了HBase的部分结构,但有明显差异,如Kudu将Zookeeper功能集成在TMaster中,数据存储采用列式存储并实现MVCC。Kudu通过主键约束确保数据唯一,而HBase支持多版本。两者在写入和读取数据时的处理方式不同,影响了它们在随机读写和批量扫描的性能表现。Kudu在牺牲写性能的同时,提升了批量读取的效率,适合在线分析场景。
本文对比分析了HBase和Kudu两款分布式存储系统。Kudu借鉴了HBase的部分结构,但有明显差异,如Kudu将Zookeeper功能集成在TMaster中,数据存储采用列式存储并实现MVCC。Kudu通过主键约束确保数据唯一,而HBase支持多版本。两者在写入和读取数据时的处理方式不同,影响了它们在随机读写和批量扫描的性能表现。Kudu在牺牲写性能的同时,提升了批量读取的效率,适合在线分析场景。
欢迎访问网易云社区,了解更多网易技术产品运营经验。
背景
Cloudera在2016年发布了新型的分布式存储系统——kudu,kudu目前也是apache下面的开源项目。Hadoop生态圈中的技术繁多,HDFS作为底层数据存储的地位一直很牢固。而HBase作为Google BigTable的开源产品,一直也是Hadoop生态圈中的核心组件,其数据存储的底层采用了HDFS,主要解决的是在超大数据集场景下的随机读写和更新的问题。Kudu的设计有参考HBase的结构,也能够实现HBase擅长的快速的随机读写、更新功能。那么同为分布式存储系统,HBase和Kudu二者有何差异?两者的定位是否相同?我们通过分析HBase与Kudu整体结构和存储结构等方面对两者的差异进行比较。
整体结构Hbase的整体结构
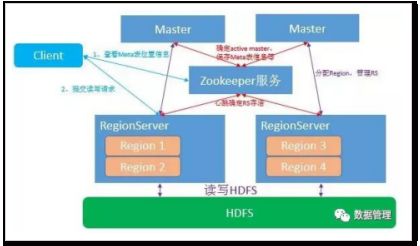
HBase的主要组件包括Master,zookeeper服务,RegionServer,HDFS。
(1)Master:用来管理与监控所有的HRegionServer,也是管理HBase元数据的模块。
(2)zookeeper:作为分布式协调服务,用于保存meta表的位置,master的位置,存储RS当前的工作状态。
(3)RegionServer:负责维护Master分配的region,region对应着表中一段区间内的内容,直接接受客户端传来的读写请求。
(4)HDFS:负责最终将写入的数据持久化,并通过多副本复制实现数据的高可靠性。
Kudu的整体结构
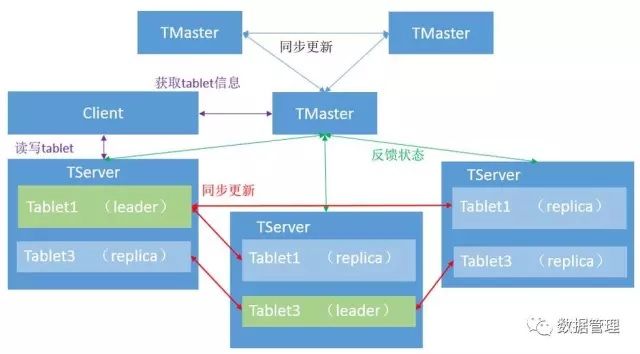
Kudu的主要组件包括TServer和TMaster。
(1) TServer:负责管理Tablet,tablet是负责一张表中某块内容的读写,接收其他TServer中leader tablet传来的同步信息。
(2) TMaster:集群中的管理节点,用于管理tablet的基本信息,表的信息,并监听TServer的状态。多个TMaster之间通过Raft 协议实现数据同步和高可用。
主要区别
Kudu结构看上去跟HBase差别并不大,主要的区别包括:
(1)Kudu将HBase中zookeeper的功能放进了TMaster内,Kudu中TMaster的功能比HBase中的Master任务要多一些。
(2)Hbase将数据持久化这部分的功能交给了Hadoop中的HDFS,最终组织的数据存储在HDFS上。Kudu自己将存储模块集成在自己的结构中,内部的数据存储模块通过Raft协议来保证leader Tablet和replica Tablet内数据的强一致性,和数据的高可靠性。为什么不像HBase一样,利用HDFS来实现数据存储,笔者猜测可能是因为HDFS读小文件时的时延太大,所以Kudu自己重新完成了底层的数据存储模块,并将其集成在TServer中。
数据存储方式
HBase
HBase是一款Nosql数据库,典型的KV系统,没有固定的schema模式,建表时只需指定一个或多个列族名即可,一个列族下面可以增加任意个列限定名。一个列限定名代表了实际中的一列,HBase将同一个列族下面的所有列存储在一起,所以HBase是一种面向列族式的数据库。

HBase将每个列族中的数据分别存储,一个列族中的每行数据中,将rowkey\列族名、列名
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2031
2031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









