




 本文深入探讨GloVe与Word2Vec两种词嵌入模型的原理与区别,GloVe通过全局共现矩阵捕捉词间关系,而Word2Vec侧重局部上下文分析。GloVe利用概率比和向量运算建立词向量,形成全局向量表示。
本文深入探讨GloVe与Word2Vec两种词嵌入模型的原理与区别,GloVe通过全局共现矩阵捕捉词间关系,而Word2Vec侧重局部上下文分析。GloVe利用概率比和向量运算建立词向量,形成全局向量表示。
之前介绍了word2vec模型,简单来说,它就是通过一个个句子去发掘出词与词之间的关系,再通过向量去表示出这种关系。而现在将要介绍的GloVe,我觉得它的思想也是和word2vec接近的。
word2vec是通过一个个句子去分析词与词之间的关系,而GloVe是通过整个语料库所有的句子去分析词与词之间的关系,在具体说明之前,首先介绍一下共现矩阵(co-occurrence matrix)。
共现矩阵主要统计了语料库中单词i的上下文中单词j的次数,和word2vec一样,这里的上下文通过指定滑动窗口(context window)大小确定单词数量,比如我们有一个语料库:"he is a boy. He is smart."假设滑动窗口大小为2(也就是分析目标词前后的两个词),可得到共现矩阵:
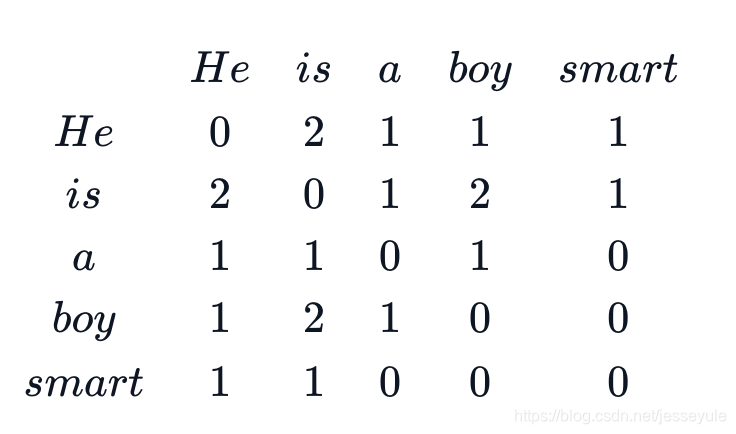
得到了语料库的共现矩阵,接下来就是GloVe的核心思想了,首先,GloVe定义了概率:
P i j = P ( j ∣ i ) = x i j x i P_{ij} = P(j|i) = \frac{x_{ij}}{x_i} Pij=P(j∣i)=xixij
这个概率表示单词i的前后文中出现单词j的概率,然后,GloVe认为,比起这个概率,更有意义的是概率的ratio:
R
a
t
i
o
=
P
i
k
P
j
k
Ratio = \frac{P_{ik}}{P_{jk}}
Ratio=PjkPik
简单来理解就是,如果两个单词ij,以十分接近的概率出现在单词k的上下文,那么就可以认为ij之间具有较大的某种联系。但是要分析这种关系有需要依赖于单词k,所以针对单词i、j、k,GloVe提出了以下公式:
F ( w i , w j , w k ) = P i k P j k F(w_i, w_j, w_k) = \frac{P_{ik}}{P_{jk}} F(wi,wj,wk)=PjkPik
以上公式的意思就是,如果我们能够用一个合理的向量表示这三个单词,那么它们经过一个函数的处理后,应该反映出它们之间的关系(ratio)。
接下来的问题就剩下如何确认这个函数的具体形式了(因为ratio是可以通过共现矩阵计算出来的一个标量,是确定的,所以主要研究左边的函数形式)。
第一步,ratio是通过i和k的关系以及j和k的关系推断出i和j的关系,因而i和j的关系亲疏通过作差去表示;
F ( w i , w j , w k ) = F ( ( w i − w j ) T , w k ) = P i k P j k F(w_i, w_j, w_k) = F((w_i-w_j)^T, w_k) = \frac{P_{ik}}{P_{jk}} F(wi,wj,wk)=F((wi−wj)T,wk)=PjkPik
第二步,因为ratio是一个标量,ij作差后还是向量,k也是一个向量,因此GloVe就通过两个向量求内积把向量转化为标量:
F ( ( w i − w j ) T w k ) = F ( w i T w k − w j T w k ) = P i k P j k F((w_i-w_j)^T w_k) = F(w_i^T w_k - w_j^T w_k) = \frac{P_{ik}}{P_{jk}} F((wi−wj)Twk)=F(wiTwk−wjTwk)=PjkPik
第三步,因为左边是差,右边是商,所以最后通过指数函数把两个联系起来:
e x p ( w i T w k − w j T w k ) = e x p ( w i T w k ) e x p ( w j T w k ) = P i k P j k exp(w_i^T w_k - w_j^T w_k) = \frac{exp(w_i^T w_k)}{exp(w_j^T w_k)} = \frac{P_{ik}}{P_{jk}} exp(wiTwk−wjTwk)=exp(wjTwk)exp(wiTwk)=PjkPik
第三步,因为左边是差,右边是商,所以最后通过指数函数把两个联系起来:
e x p ( w i T w k − w j T w k ) = e x p ( w i T w k ) e x p ( w j T w k ) = P i k P j k exp(w_i^T w_k - w_j^T w_k) = \frac{exp(w_i^T w_k)}{exp(w_j^T w_k)} = \frac{P_{ik}}{P_{jk}} exp(wiTwk−wjTwk)=exp(wjTwk)exp(wiTwk)=PjkPik
本来,我们只需要让对应的分子分母相等就可以了:
e x p ( w i T w k ) = P i k exp(w_i^T w_k) = P_{ik} exp(wiTwk)=Pik
w i T w k = l o g P i k = l o g ( X i k ) − l o g ( X i ) w_i^T w_k = log P_{ik} = log(X_{ik}) - log(X_i) wiTwk=logPik=log(Xik)−log(Xi)
等式左边两个词向量相乘对顺序是不敏感的,可是右边不一样,所以会出现问题:
w k T w i = l o g ( X k i ) − l o g ( X k ) w_k^T w_i = log(X_{ki}) - log(X_k) wkTwi=log(Xki)−log(Xk)
w k T w i = w i T w k w_k^T w_i = w_i^T w_k wkTwi=wiTwk
l o g ( X k i ) − l o g ( X k ) ≠ l o g ( X i k ) − l o g ( X i ) log(X_{ki}) - log(X_k) \neq log(X_{ik}) - log(X_i) log(Xki)−log(Xk)̸=log(Xik)−log(Xi)
所以在原式引入偏置项(网上很多文章对这个偏置项的推导不算太详细,我这里具体写一下):
w k T w i + b i = l o g ( X k i ) − l o g ( X k ) w_k^T w_i + b_i = log(X_{ki}) - log(X_k) wkTwi+bi=log(Xki)−log(Xk)
w i T w k + b k = l o g ( X i k ) − l o g ( X i ) w_i^T w_k + b_k = log(X_{ik}) - log(X_i) wiTwk+bk=log(Xik)−log(Xi)
我们知道:
l o g ( X k i ) = l o g ( X i k ) log(X_{ki}) = log(X_{ik}) log(Xki)=log(Xik)
w i T w k = w k T w i w_i^T w_k = w_k^T w_i wiTwk=wkTwi
所以其实:
b i − b k = − l o g ( X k ) + l o g ( X i ) b_i - b_k = - log(X_k) + log(X_i) bi−bk=−log(Xk)+log(Xi)
也就是说,偏置项主要和X_k、X_i有关,我们把两式相加:
w i T w k + w k T w i + b k + b i = l o g ( X i k ) + l o g ( X k i ) − l o g ( X i ) − l o g ( X k ) w_i^T w_k + w_k^T w_i + b_k + b_i = log(X_{ik}) + log(X_{ki}) - log(X_i) - log(X_k) wiTwk+wkTwi+bk+bi=log(Xik)+log(Xki)−log(Xi)−log(Xk)
2 ∗ w i T w k + b k + b i = 2 ∗ l o g ( X i k ) − l o g ( X i ) − l o g ( X k ) 2*w_i^T w_k+ b_k + b_i = 2*log(X_{ik}) - log(X_i) - log(X_k) 2∗wiTwk+bk+bi=2∗log(Xik)−log(Xi)−log(Xk)
因为偏置项和X_k、X_i有关,所以可以进一步简化,消去log(X_i)、log(X_k),其实就是把它们包含在b_i、b_k里面,然后再简化一下式子得到:
w i T w k + b k + b i = l o g ( X i k ) w_i^T w_k+ b_k + b_i = log(X_{ik}) wiTwk+bk+bi=log(Xik)
终于得到了最终的结果,这个结果是基于最完美的词向量得到的,所以,接下来的步骤,就是定义损失函数,通过训练神经网络,从初始向量开始求出这些最完美的词向量:
L o s s = ∑ ( w i T w k + b k + b i − l o g ( X i k ) ) 2 Loss = \sum (w_i^T w_k+ b_k + b_i - log(X_{ik}))^2 Loss=∑(wiTwk+bk+bi−log(Xik))2
同时,GloVe也考虑到两个词共同出现的次数越多,那么在这两个词在损失函数的影响就应该更大,所以可以根据两个词共同出现的次数设计一个权重来对损失函数中的每一项进行加权:
L o s s = ∑ f ( X i k ) ( w i T w k + b k + b i − l o g ( X i k ) ) 2 Loss = \sum f(X_{ik}) (w_i^T w_k+ b_k + b_i - log(X_{ik}))^2 Loss=∑f(Xik)(wiTwk+bk+bi−log(Xik))2
关于这个权重这里我就不再详细说明。
以上就是关于GloVe的详细推导过程,可以看到,GloVe的思想和word2vec的思想接近,但是GloVe是从全局的角度出发,构建一个共现矩阵,每一次的训练都是基于整个语料库进行分析的,所以它才叫Global Vector,而word2vec则是从一个个句子出发,但我认为重点都在于通过句子去分析词与词之间的联系。
想浏览更多关于数学、机器学习、深度学习的内容,可浏览本人博客

















 405
405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









